
![]()
![]()
A partir de la position du gène (Insuline INS ), localiser le gène sur les chromosomes humains, trouver la séquence en acides nucléiques et acides aminés .
Pour une version simplifiée voir BIST-ABC
On peut également effectuer la démache inverse : scénario 1 : du nom de protéine à la séquenceCet exemple a été réalisé avec l'EPO mais il peut être réalisé avec l'insuline ou d'autres : liste d'exemples de protéines.
La démarche inverse présente aussi un intérêt : partir des chromosomes pour aller vers le gène, puis la protéine.
Mapviewer est un "outil" proposé par le NCBI, très adapté pour une approche qui part depuis l'espèce puis les chromosomes et aide à situer les séquences dans leur contexte.
On trouve quelques autres loci de gènes en rapport avec le mot "insulin" sur les différents chromosomes humains (insulin receptor , insulin induced gene ...). le gène de l'insuline est nommé INS et est sur le 11
Alternativement activer le "Quick Filter" à droite avec l'option gene cela n'affiche que certaines séquences ->, on y repère plus facilement ("insulin" tout court) le gène de l'insuline humaine sur le chr 11.
Choisir Reference (Génome humain complet, vérifié)
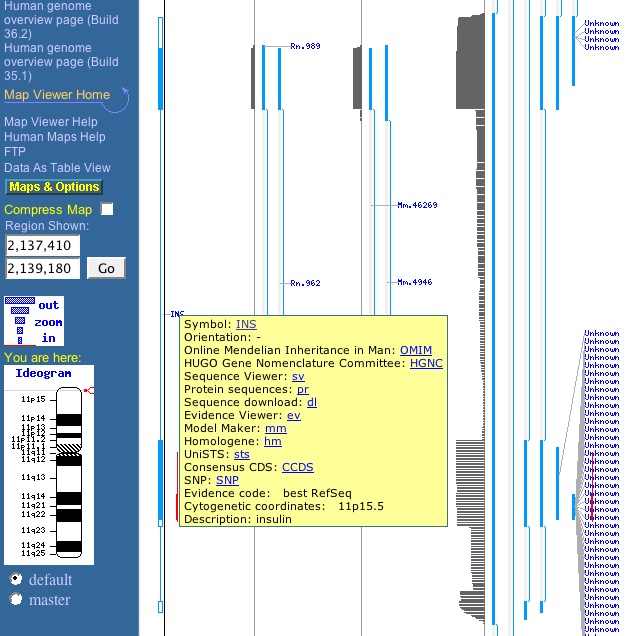 On visualise un agrandissement de la région du chromosome 11 codant pour l'insuline :
On visualise un agrandissement de la région du chromosome 11 codant pour l'insuline :
cf ci-contre : cliquer pour agrandir .
Les lignes verticales sont des séquences pour différentes espèces Notre séqeunce humaine est la plus à gauche. Avec le gène INS au milieu
Cliquer X en haut pour supprimer l'affichage des colonnes (autres sp.) non désirées ( Solution )
 On peut cliquer la séquence verticale à gauch et zoomer plus près du gène pour mieux visualiser le gène et les espaces non codants
Solution
On peut cliquer la séquence verticale à gauch et zoomer plus près du gène pour mieux visualiser le gène et les espaces non codants
Solution
Notez bien que le nom officiel du gène de l'insuline est INS
|
Lien direct sur l'insuline dans Mapviewer http://doiop.com/mapview-ins |
Sous Genomic context on voit un schéma des séquences genomiques et du snees de lecture ![]()
Ce browser indique dans une page interactive
![]() de nombreuses informations dont :
de nombreuses informations dont :
la séquence présentée en bases : chr11:2,181,009-2,182,439 1431 bp
un schéma du chromosomes correspondant (11) avec la position repérée en rouge ( bras court près de l'extrémité)

les introns représentés avec une barre épaisse et les exons avec le sens de transcription indiqué par des >>>> ou <<<< 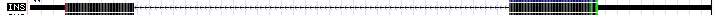
On peut visualiser les variantes et les snp en ajustant les paramètres Touuuut en bas : common SNPs(138) : full et Genome variants : Full 
On peut ainsi voir l'alignement avec d'autres organismes et les variantes connues.
Le degré de conservation de la protéine est un reflet de la pression de sélection. 
La séquence est nommée NP_000198
Le numéro d'accession commence par NP (cf glossaire ) On en déduit que c'est une protéine (numéro d'accession de la banque de données "RefSeq" spécifique pour une protéine), qu'elle se nomme proinsulin precursor et que c'est chez Homo sapiens
Cette séquence est au format fasta .cf glossaire
|
>gi|4557671|ref|NP_000198.1| proinsulin precursor [Homo sapiens] |
Retour à BIST | Swiss-Prot | M.C. Blatter | Projets Home de F. Lo