
![]()
![]()
Taper dans un texteur quelconque (e.g. ) une séquence au hasard, P. ex :
attatacgtatataattccgataatcgcgctga
Le copier
Selectivité : Une similitude de plus de 25% d'aa et de plus de 70% des nucléotides est considére comme homologue (Claverie & Notredame p 229) si on a des séquences de plus de 100 résidus. En dessous de 10 résidus même la similitude parfaite n'est pas signifiante
Coller la séquence dans le champ indiqué "Enter accession number, gi, or FASTA sequence" , vérifier que la base de données utilisée est bien Human genomic + transcript
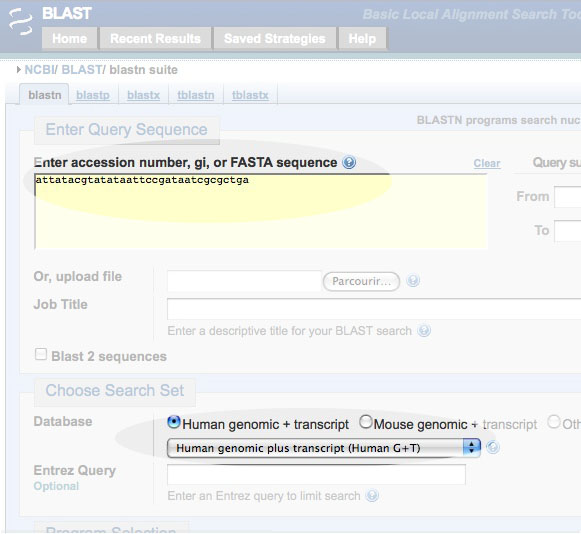
et cliquer le bouton BLAST 
La séquence fait apparaitre des similitudes notamment avec notamment un gène localisé sur le chromosome 20 (NM_022106.1) mais avec un facteur de coincidence E de 4.4 très élevé qui signifie en fait que la similitude est due à une coincidence et donc que cette séquence n'a pas réellement été trouvée.
3 a) Chercher une séquence connue :
ctgggcgggg gccctggtgc aggcagcatg est celle de l'insuline mais avec une seule point-mutation en rouge.
Blast de cette séquence : on trouve l'insuline avec E = 4e-06 la ligne verte est l'insuline humaine :
Cliquer la ligne verte pour obtenir les détails sur cette séquence
Le facteur de coincidence est de 4e-06 ce qui signifie qu'on a une chance sur un million que ce soit dû au hasard...
3 b) Chercher une séquence connue de taille diminuant progressivement jusqu'à non-reconaissance :
3c) Essayer avec l'insuline très modifiée
par exemple ici 9 mutations de rempacements + 2 bases insertion (l'insuline en bleu pour comparer)
ctgggcgctg gccactggtgc agaagttgggtcctgggcgggg gccctggtgc aggcagcctgNo significant similarity found
Ici on a choisi Blast contre le human genome: avec le Blast contre toutes les espèces http://www.ncbi.nlm.nih.gov/BLAST/, les résultats pourraient être différents.
Retour à BIST | Swiss-Prot| M.C. Blatter | Projets Home de F. Lo