Un système de production est un programme qui fonctionne de façon particulière. Il représente le problème qu'il doit résoudre sous forme d'un ensemble d'informations factuelles telles que "le patient est âgé de 55 ans" ou "la température dans le bassin 15 est de 120 degrés". Ces données sont appelés les faits. Les connaissances nécessaires pour résoudre un problème sont représentées par un ensemble d'énoncés tels que "si le patient est âgé de plus de 40 ans, alors la probabilité d'une maladie cardio-vasculaire est plus grande" ou "si la température dans un bassin est de 90 degrés, il faut réduire le chauffage et relâcher les soupapes de cette cuve." Ces énoncés sont appelés 'règles'. Ils prennent généralement la forme suivante:
SI telles conditions sont satisfaites
ALORS faites ceci ou déduisez cela.
Un système de production contient donc un ensemble de faits (appelé 'base de faits' et un ensemble de règles (appelé 'base de règles'). Les conditions de la règle font référence à l'ensemble des faits qui définissent le problème. Les conclusions (ou actions) de la règle modifient la base de faits: ajouter un nouveau fait ou effacer un fait qui n'est plus valide. Résoudre un problème consiste à considérer de la base de faits, appliquer une règle, mettre à jour la base de faits selon les conclusions de cette règle et réitérer ce cycle jusqu'au moment où le problème est résolu. Prenons un exemple simple. Le système veut savoir si "Jean est le petit-fils d'Eugène". Il dispose au départ des faits suivants:
F1) Jean est le fils de Victor
F2) Victor est le frère de Serge
F3) Serge est le fils de Marthe
F4) Marthe est l'épouse d'Eugène
Il dispose également des règles suivantes:
R1) Si X est le fils de Y et
si Y est le fils de Z,
ALORS X est le petit fils de Z.
R2) Si X est le frère de Y
et si Y est le fils de Z
ALORS X est le fils de Z
R3) Si X est le fils de Y et
si Y est l'épouse de Z,
ALORS X est le fils de Z.
Les règles ne décrivent pas un problème particulier. Elle décrivent des relations entre des variables du problème (ici X, Y ou Z). Ces variables seront instanciées par une donnée du problème. Si on remplace X par "Victor" et Y par "Serge", le fait F2 correspond à la première condition de R2, qui devient 'si Victor est le frère de Serge'. La correspondance entre le fait F2 et la première condition instanciée est purement syntaxique, les mêmes mots devant se trouver à la même place dans les deux expressions:
Victor est le frère de Serge (F2)
(si) Victor (X) est le frère de Serge(Y) (condition 1 de R2)
Cette mise en correspondance terme à terme ne supporte pas de variations orthographiques ou syntaxiques. Toute variation doit être définie explicitement. Par exemple, pour accepter le mot 'frere' sans accent, il faudrait ajouter une règle:
Si X est le frere de Y, alors X est le frère de Y
Cette exemple met en évidence que, même s'il s'agit de techniques d'intelligence artificielle, le traitement repose finalement sur des manipulations syntaxiques. Afin de simplifier ces manipulations, les faits et les règles sont souvent exprimés dans une syntaxe dépourvue d'articles, voire de prépositions, dans laquelle la position des éléments est essentielle.
Exemple: Si Père (X,Y) et mâle (Y) alors Fils (Y,X)
Une variable présente plusieurs fois dans une règle prendra chaque fois la même valeur. Ainsi si "Y" vaut "Serge dans la première condition de R2, cette variable garde la même valeur à chaque apparition dans R2, tant dans la seconde condition que dans la conclusion (si elle y apparaît).
Le système va chercher un jeu de valeurs (une valeur par variable) qui permette de trouver un fait qui satisfasse chaque condition. Ainsi, si on remplace Y par "Serge" et Z par "Marthe", le fait F3 satisfait la seconde condition de R2.
Lorsque toutes les conditions de la règle sont satisfaites, on peut activer la règle, c'est-à-dire instancier les conclusions de la règle avec les valeurs des variables utilisées pour unifier les conditions. Les nouveaux faits sont ajoutés dans la base de faits. Les conclusions de la règle 2 sont "Victor est le fils de Marthe". Notre base de fait devient
F1) Jean est le fils de Victor
F2) Victor est le frère de Serge
F3) Serge est le fils de Marthe
F4) Marthe est l'épouse d'Eugène
F5) Victor est le fils de Marthe
Ce nouveau fait F5 et le fait F4 permettent d'activer la règle R3 (X = Victor, Y = Marthe et Z = Eugène) et d'en déduire que Victor est le fils d'Eugène. Ce nouveau fait vient à son tour enrichir la base de faits.
F1) Jean est le fils de Victor
F2) Victor est le frère de Serge
F3) Serge est le fils de Marthe
F4) Marthe est l'épouse d'Eugène
F5) Victor est le fils de Marthe
F6) Victor est le fils d'Eugène
Au cycle suivant, les faits F1 et F6 permettent d'activer la règle R1 (X=Jean, Y=Victor et Z= Eugène) et d'en déduire que "Jean est le petit-fils de d'Eugène", ce que l'on cherchait à prouver. Le système qui choisit les règles et les instancie s'appelle un moteur d'inférence. Dans l'exemple ci-dessus le moteur fonctionne en 'chaînage avant': il part des faits et déduit de nouveaux faits jusqu'au moment où il atteint son but. Cette méthode est illustrée par la figure 8.1.
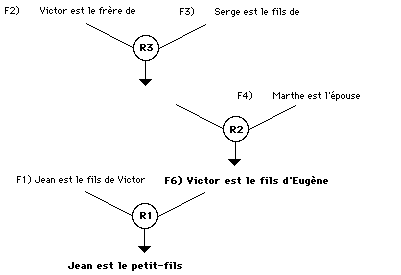
Figure 8.1 Exemple de chaînage avant (les faits en gras ont été créés en cours d'exécution)
D'autres systèmes fonctionnent en chaînage arrière. Ils partent du but et découvrent que les conclusions de R1 correspondent au but si on remplace X par "Jean" et Z par "Eugène". Le moteur unifie alors les conditions en leur donnant les valeurs prises par les variables dans les conclusions. Grâce à R1, le système déduit que pour prouver que "Jean est le petit-fils d'Eugène", il doit prouver que "Jean est le fils de Z" et que "Z est le fils d'Eugène". Ces deux énoncés deviennent ses nouveaux sous-buts. Si il instancie Z par "Victor", le fait F1 prouve le premier sous-but. Il lui reste à prouver le second sous-but: "Victor est le fils d'Eugène". Il va chercher une règle dont la conclusion correspond à ce sous-but et répéter le processus jusqu'au moment où il utilise une règle dont toutes les conditions sont satisfaites par la base de faits. Cette méthode de recherche est illustrée dans la figure 8.2.
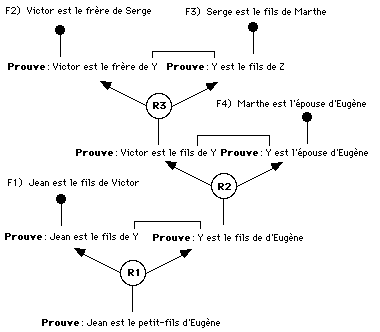
Figure 8.2 Exemple de chaînage arrière
En chaînage arrière, le système doit maintenir en mémoire la liste des buts et sous-buts qui lui reste à prouver. Cette agenda de ce qu'il lui reste à faire est géré comme une pile de livres: on peut uniquement ajouter un élément au sommet de la pile ou retirer celui du sommet. Cette pile de buts est souvent comparée à la mémoire de travail d'un utilisateur. La hauteur de la pile des buts (c'est-à-dire le nombre de choses qu'il lui reste à prouver) est alors considérée comme une estimation (très élémentaire) de sa charge cognitive.
Comment le programme décide-t-il de donner telle valeur à telle variable? Pourquoi donner à X la valeur Victor, plutôt que Serge ou Marthe ? En fait, le système ne choisit pas, mais teste toutes les valeurs possibles. Il utilise simplement des techniques qui lui permet de tester systématiquement toutes les combinaisons possibles. Par exemple, pour unifier la condition 'X est le frère de Y' avec le fait 'Victor est le frère de Serge', il va générer toutes les combinaisons de deux prénoms, jusqu'au moment où l'une d'entre elles correspond à un fait (voir figure 8.3). Cette recherche aveugle pose des problèmes 'd'explosion combinatoire': si une règle contient 10 variables et que celles-ci peuvent prendre 20 valeurs différentes, cela donne 2000 millions de combinaisons possibles ! Dans le cas illustré, on peut optimiser la recherche. Par exemple, dès que la variable X a été instanciée par 'Jean', on peut déjà tester si un fait commence par 'Jean est le frère de'. Si oui, on cherchera la valeur pour Y. Sinon, on passera directement à une autre valeur de X.
La sélection des règles se fait grosso mode de la même manière. A chaque pas, on teste toutes les règles. Au pas N, si une règle est applicable, on l'applique et on recommence la même chose au pas N+1. Si aucune règle n'est applicable, on revient au pas N-1 et on considère les règles qui non pas encore été appliquées à ce pas. C'est ce qu'on appelle la recherche en profondeur dans un arbre: après avoir considéré un noeud N, on considère d'abord ses fils (les noeud subordonnés), et seulement si cela ne donne rien, on considère des frères (les noeuds issues du même noeud super-ordonné).
Sachant qu'un programme comporte généralement plusieurs centaines de règles différentes, la recherche de la solution soulève également des problèmes d'explosion combinatoire. Comment décider s'il vaut mieux essayer d'abord la règle R2 ou une autre? Le système utilise des heuristiques pour choisir entre des règles concurrentes. Certains moteurs d'inférence préfèrent toujours les règles qui comprennent plus de conditions car elles sont plus spécifiques au problème traité. Certains systèmes associent un facteur de priorité aux règles, ce qui leur permet de dire 'cette règle est généralement plus importante'. D'autres systèmes ont un second étage de règles: les règles du deuxième étage (appelées meta-règles) permettent de choisir entre plusieurs règles du premier étage.
Nous n'entamerons pas ici un débat sur la fidélité psychologique des techniques de l'intelligence artificielle. Les techniques décrites ci-dessus ne sont pas -ou ne sont plus- proposées comme des descriptions de la façon dont un humain résout les problèmes. Plus modestement, ces techniques permettent de réfléchir de manière systématique sur les connaissances nécessaires pour réaliser une tâche. Parce que les connaissances exprimées sont exécutables, l'auteur du système peut observer les comportements générés par les connaissances fournies. La comparaison homme-machine se limite généralement à prétendre que plus le modèle computationel est complexe, plus le travail de l'utilisateur sera complexe (ce qui n'est pas toujours le cas). Ceci n'implique pas nécessairement que le système et l'utilisateur accomplissent la tâche de la même manière. Ce qui est vraiment évalué est donc la complexité de la tâche. Un autre point intéressant est que ces connaissances sont représentées de façon modulaire. L'auteur peut observer les solutions que propose le système si on lui retire certains règles ou si on lui ajoute des règles erronées. Ces possibilités ont été largement utilisées pour la modélisation de l'utilisateur.
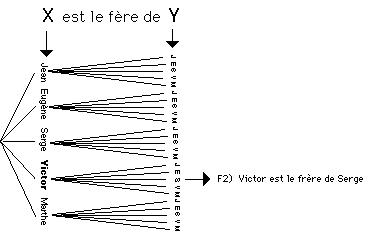
Figure 8.3 Instanciation d'une expression contenant des variables