En règle générale, la sélection aléatoire est plus facile a programmer que la génération aléatoire, mes elle implique bien sûr de prévoir tous les données possibles. Dans Authorware, la sélection aléatoire repose sur l'icône de décision. Celle-ci permet notamment de préciser si le même choix peut-être réalisé plusieurs fois. La génération aléatoire repose sur l'utilisation de la fonction 'random' dans une icône de calcul. Cette fonction permet de fixer la borne inférieure et supérieure de l'intervalle à l'intérieur duquel le nombre sera choisi, et de déterminer le 'pas' (si ce pas est inférieur à 1, Authorware génère des nombres décimaux).
Dans le domaine de l'EAO, les logiciels sont souvent classifiés par rapport à la balance entre le contrôle exercé par l'élève et celui exercé par le système. On utilise malheureusement le terme ambigu de "contrôle de l'élève" pour désigner en réalité le contrôle de l'interaction par l'élève. Lorsque la balance de contrôle est plus ou moins équilibrée, on parle de "système à initiative mixte". Parmi les systèmes à initiative mixte, on compte par exemple les systèmes dans lesquels le sujet peut soit répondre à des questions ou poser certaines questions et décider quand il passe d'un mode à l'autre. On compte également des systèmes plus complexes, dans lesquels l'élève résout par exemple une équation. L'élève peut utiliser la stratégie qu'il souhaite, mais, s'il s'écarte trop du cheminement correct, le système intervient pour l'aider ou le corriger.
Comme l'illustre la figure 7.1, les systèmes dans lesquels les actions de l'utilisateur sont soit totalement libres, soit totalement contraintes sont les plus faciles à concevoir et à implémenter. Par contre, les systèmes à initiative mixte sont difficiles à réaliser car le programme doit "suivre" l'utilisateur, le "comprendre", afin de déterminer s'il est opportun d'intervenir ou s'il convient au contraire de laisser l'élève persévérer et afin de proposer une aide pertinente.
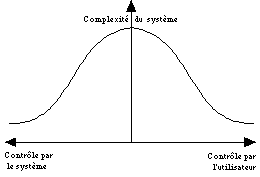
Figure 7.1. Variation du niveau de complexité d'un programme selon la balance du contrôle.
(Section à développer - voir Woods & Roth, 1988, p 23.) Cette section touche à une question fondamentale dans la relation homme-machine: l'automatisation. Quelle partie est prise en charge par la machine et quelle partie est réalisée par l'utilisateur? La distribution optimale de la tâche entre le système et l'utilisateur vise à exploiter leur spécificité respective, c'est-à-dire à attribuer à chacun les tâches pour lesquelles il est le plus performant. Les systèmes informatiques traitent efficacement les aspects syntaxiques de l'information. L'être humain leur est supérieur dans toute tâche qui fait appel aux aspects sémantiques de l'information, qui exige du bon sens ou des connaissances générales, ou encore qui comporte des situations imprévues. Par contre, les performances humaines sont plus sensibles aux aspects quantitatifs de l'information et en sont affectées par le caractère répétitif de certaines tâches. Les techniques d'intelligence artificielle ne remettent pas en cause cette différentiation des rôles. Certes, ces techniques ont permis de traiter formellement des tâches qui apparaissaient à première vue comme intuitives, en y détectant des règles de raisonnement et des heuristiques. Néanmoins, ces travaux n'ont pas permis de traiter les aspects purement sémantiques du raisonnement, ce qui explique d'ailleurs la stagnation des recherches sur la compréhension du langage naturel.
Cette distribution de la tâche apparaît spontanément dans la collaboration entre personnes (Myake, 1986). Par exemple, si les deux collaborateurs utilisent un programme, celui qui tient la souris a tendance à s'occuper des détails de la tâche alors que son partenaire, dégagé de ces détails, se consacre davantage aux aspects plus stratégiques de la tâche (Blaye et al., 1991). Cette distribution n'est pas figée. Elle varie selon la tâche et selon le moment.
La question la plus difficile dans l'automatisation n'est cependant pas de savoir comment partager la tâche, mais comment maintenir une bonne coordination malgré le partage de la tâche. Si le système prend en charge certains aspects répétitifs et que l'utilisateur gère les décisions plus stratégiques, il faut que ces deux parties du traitement soient totalement en correspondance, que l'utilisateur comprenne ce que fait la machine et que le système traite les données comme l'utilisateur l'a spécifié. L'utilisateur doit avoir confiance dans le traitement réalisé par la machine, ce qui est particulièrement important lorsque la tâche est critique (par exemple, les pilotes automatiques). Il doit anticiper les réactions du système et les annuler s'il n'est pas d'accord. Par exemple, dans les systèmes qui permettent de contrôler automatiquement la vitesse d'un véhicule ('cruise control'), le pilote confie au système la tâche de contrôler la pédale des gaz, mais dès que le pilote touche la pédale de frein, le système lui rend le contrôle de la vitesse.
Une approche intéressante consiste à considérer l'utilisateur et le système comme un seul système cognitif dont on cherche à accroître la performance globale (Woods et Roth, 1988; Dillenbourg, sous presse). Ce système distribue le traitement cognitif sur ses participants: le ou les utilisateurs, le ou les processeurs. On peut par exemple considérer l'écran comme une extension de la mémoire de travail de l'utilisateur, en y maintenant les informations nécessaires à la résolution du problème. On parle dans ce cas du système comme une prothèse cognitive de l'utilisateur.