
chapitre 7 Epistémologie et méthodes de la modélisation IA
"Representation is a stylized version of the world. Depending on how it is to be used, a representation can be quite simple, or quite complex".
Dans le contexte du génie cognitif, les représentations ont une fonction technique et utilitaire. Il s'agit d'un moyen pour exprimer de façon modulaire et structurée des connaissances. Une représentation encode un savoir analytique et non pas une connaissance au sens "Verstehen" du terme. Comme toute construction artificielle, un système de représentation possède des limites en ce qui concerne la représentation des compétences de l'objet modélisé. Dans notre contexte, un langage de représentation a deux fonctions principales: (1) la représentation des connaissances que l'on possède sur des acteurs politiques de façon à pouvoir faire (2) des inférences qui amènent vers des nouvelles représentations*1.
Une expression ou une liste d'expressions représentent un savoir formalisé. Prenons, par exemple, la phrase simple:
Une personne a acheté une maisonElle pourrait se traduire par le triplet:
(bought person house)Cette formule possède une lacune conceptuelle car elle ne fait pas la distinction entre la définition abstraite (comme: "une personne quelconque a acheté une maison quelconque, quelque temps dans le passé") et la définition concrète (comme: "un homme X a acheté une maison X à un moment T"). La formule ci-dessus représente donc plutôt un savoir intensionnel*2 résidant dans la mémoire sémantique tandis que des formules comme:
(bought-1 person-1 house-1) (bought yesterday person Muller house "No 311a")représentent des instantiations de la mémoire épisodique. Il existe donc une différence importante entre des descriptions de classes (types) de connaissances et des instantiations concrètes
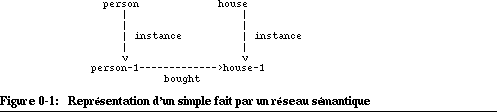
Lorsqu'une formule affirme un fait, on parle d'une proposition ou d'une assertion. Une assertion doit être unique. La façon dont on veut représenter une assertion ou encore un ensemble de savoir sémantique dépend des buts du modéliseur. Reprenons notre exemple simple d'une personne qui a acheté une maison. On peut représenter ce fait par un réseau sémantique comme dans la figure 7-4 "Représentation d'un simple fait par un réseau sémantique" [p. 304]. Ce réseau sera exprimé par les expressions suivantes:
(instance person person-1) (instance house house-1) (bought person-1 house-1)Cette formule possède deux inconvénients: Primo, il faut se souvenir de la signification des positions dans chaque représentation pour pouvoir l'interpréter. Secundo, elle ne met pas suffisamment en valeur le fait qu'il s'agit d'un ensemble. Pour remédier à ce dernier problème, on peut adopter une notation qui rajoute une référence commune "transaction":
(instance transaction-13 transaction) (actor transaction-13 person-1) (object transaction-13 house-1) (instance person person-1) (instance house house-1)Nous préférons en règle générale la notation "frame" ou "slot and filler" dont nous donnons la grammaire dans la figure 7-5. Elle accentue l'ensemble par rapport aux éléments. Par cette notation, on pourrait représenter le type abstrait de "transaction" comme

(transaction (actor person?) (object house?))Cette expression définit des relations entre des classes de symboles. Son instantiation pourrait être représentée comme:
transaction-13 = (transaction (actor person-1) (object house-1))En utilisant des éléments "slot-filler" comme "(actor person?)" on peut facilement interpréter le sens d'une expression sans être trop verbeux. Les sous-expressions comme "(actor person-1)" signifient implicitement quelque chose comme "(actor transaction-xx person-1)". Finalement pour représenter dans la mémoire d'un système l'événement d'une transaction, on peut employer une "event-token representation" comme:
(event event-1 (transaction (actor person?) (object house?)))La notation "frame" ou des variantes sont parfois utilisées avec des moteurs d'inférence de type "chaînage avant". Toutefois, pour des raisons d'économie de calcul, on simplifie les expressions en laissant de côté le "slot". Dans ce cas, le sens du "filler" est déterminé par sa position dans l'expression*3. Ce type de notation plus claire est populaire dans des modélisations utilisant des représentations et/ou des méthodes de raisonnement complexe comme par exemple l'école de "Yale" dont nous avons brièvement discuté le système "Politics" (page 156). Cette notation est proche des objets structurés de la programmation orientée objets qui se marie d'ailleurs très bien avec les systèmes de production*4.
Le but de cette section n'était pas de donner une introduction à la représentation des connaissances, après tout il s'agit du problème central de toute l'IA symbolique, mais de sensibiliser le lecteur au fait qu'il existe des conventions plus ou moins simples à lire et à utiliser mais dont il faut connaître la grammaire d'encodage. Il est également important de savoir distinguer entre un "type" qui représente une connaissance ou une relation abstraite et une "instance" qui représente un fait. Cette distinction existe dans tous les systèmes IA même si elle n'est pas rendue explicite.
"Cyc" (Guha 90) et le "Knowledge Sharing Effort" (Fikes et al. 91) sont deux projets majeurs en IA essayant de fournir des bases communes au génie cognitif. Cyc tente de construire une très large base de connaissances humaines essentielles (angl. "common sens knowledge base"), une sorte d'ontologie sur laquelle on pourrait bâtir de nombreuses entreprises du génie cognitif. Le "Knowledge Sharing Effort" est un consortium pour développer des conventions qui permettront de partager et de réutiliser des bases de connaissances et même des systèmes à bases de connaissances.
Il serait idéal, si en science politique, on pouvait mettre sur pied un groupe de travail chargé de développer des langages communs pour tout type de modélisation et si nécessaire des passerelles entre ces langages. Les systèmes de représentation constituent la pierre angulaire des systèmes à bases de connaissances et l'expressivité d'un dispositif de modélisation en dépend fortement. Des langages standardisés nous permettraient de créer des bases de données communes (comme c'est déjà le cas en relations internationales) et d'échanger des "briques" de modélisation entre chercheurs.

Generated with WebMaker