|
|
|
|
Traduire
un texte
Dans ce chapitre, tu apprendras ce qu'est un outil de
traduction automatique, comment il fonctionne et tu auras une adresse sur
le web où tu pourras soumettre des textes à traduire ainsi
qu'un autre site où tu pourras faire traduire tes méls.
1. Comment cela marche-t-il?Si tu veux traduire un texte, tu peux le faire avec un outil, dit de traduction automatique, qui se trouve sur le Web. Tu mets ton texte dans un format approprié comme HTML et tu demandes à l'outil de traduction de traduire ton texte. Ensuite tu peux lire ton texte qui a été traduit. Ne t'inquiète pas, il ne sera pas parfait.Normalement, quand tu traduis un texte, tu
Avec la traduction automatique, il en va de même.
Site Systran de Altavista - on peut soit copier le texte à traduire, soit mettre l'URL (adresse Web) de la page à traduire: http://babel.altavista.com/translate.dyn Sous Altavista tu trouveras un outil qui te permettra de traduire ton texte. Cet outil contient des dictionnaires et des outils qui analysent les mots et l'ordre des mots de ta phrase. Il existe deux sortes de dictionnaires:
Dans un dictionnaire français par exemple, chaque entrée contient de l'information sur la morphologie, la grammaire, le sens du mot et sa place dans une phrase. Les entrées contenant plusieurs mots vont d'expressions de divers types jusqu'à des règles contextuelles qui examinent les attributs et les dépendances d'un ou plusieurs ou tous les éléments. Dans un dictionnaire de langue étrangère, la signification d'un mot français est assigné sur la base de critère comme l'équivalent pour la traduction d'un mot jusqu'aux traductions spécifiques obligatoires pour un contexte défini basé sur une expression, une locution, ou sur des conditions contextuelles. La traduction automatique ne fonctionne pas parfaitement car une langue est une sorte d'organisme vivant qui n'est jamais reproduit à l'identique et qui laisse toujours la place à la créativité. 2. Autres sites d'outils de traduction automatiqueSystran (Alta Vista) http://babelfish.altavista.com/Executive Title Translator - traduire les titres des cadres http://www.zehnder.com/titlegam.html 3. Faire traduire ton mél.A l'adresse ci-dessous, tu peux envoyer des méls rédigés dans ta langue maternelle à tes amis.Dans la ligne Cc: envoie une copie de ton message au Universal T-mail Translator. N'utilise pas de parenthèses pour tes énumérations. Cela n'a pas d'importance si tu écris en minuscule ou en majuscule. La machine le traduit pour toi et l'envoie automatiquement à ton ami. N'oublie pas que la traduction est faite par une machine et que celle-ci ne sera pas parfaite. Sur le site, tu peux traduire les langues suivantes:
4. Historique des outils d'aide à la traductionIntroductionDès la mise au point des ordinateurs, on a eu l'idée de les utiliser pour traduire des textes en diverses langues. Ceci provient du fait que le XXe siècle est fortement marqué par les applications des découvertes. L'utilisation de l'ordinateur pour la traduction a été faite lors de la seconde guerre mondiale. Depuis, on a assisté d'une part, à une multiplication des organismes internationaux destinés à maintenir la paix et, d'autre part, à une rivalité due entre camps opposés pour dominer certaines parties du monde. La recherche du dialogue et la compétition réelle entre nations sont deux facteurs politiques qui ont été déterminants pour le développement de la traduction automatique. L'adoption d'une langue commune aux diverses nations aurait pu être la solution à la communication planétaire. Cependant, les peuples ont refusé de modifier leurs traditions linguistiques. Aujourd'hui, le respect de la langue maternelle est devenu un droit inaliénable. C'est pour cette raison que les organismes internationaux doivent publier leurs écrits dans un certain nombre de langues (toutes les langues officielles pour l'Union Européenne, certaines langues pour l'UNESCO, l'ONU, le BIT, etc.) . Certaines personnes ont pensé à créer une langue
artificielle appelée l' espéranto.
Les industriels ont pris conscience de l'enjeu des l'exportation et de l'importation et vendent leurs produits dans la langue de celui qui les achètent. La traduction des modes d'emploi, des manuels de maintenance, des étiquettes est devenue un secteur d'activité important. Avec les autoroutes de l'information, le besoin d'outils linguistiques pour rechercher des informations sur des sites en langue étrangères et de pouvoir les lire dans sa propre langue devient de plus en plus important. Devant cette énorme masse d'informations à traduire, l'ordinateur peut fournir une aide précieuse. Les premiers outils électroniques créés pour faciliter la tâche des traducteurs ont été les dictionnaires informatisés. L'Union Européenne a développé, et développe encore des dictionnaires automatisés dans une base appelée EURODICOTOM http://eurodic.echo.lu/cgi-bin/edicbin/EuroDicWWW.pl. Il s'agit surtout d'un dictionnaire terminologique, c'est à dire, un dictionnaire qui contient des mots appartenant à un domaine spécifique. Ainsi, ce dictionnaire contient des termes appartenant aux diverses branches scientifiques et techniques dont l'Union Européenne est amenée à traduire: physique nucléaire, technologies de l'information, nouveaux matériaux, médecine, biologie, aéronautique, espace, droit et administration. Dans la seconde moitié du XXe siècle, plusieurs phénomènes apparaissent et qui vont entraîner le développement des outils de traduction automatique. Passage vers une société de l'information La circulation de l'information devient une priorité, donc nécessaire. Il faut que celle-ci soit disponible très rapidement sur toute la planète. Les outils de traduction automatique remplissent ces conditions. Culture de l'écran La culture de l'écran s'oppose à celle de l'écrit. La communication tend à ne plus passer par l'écrit (manuscrit ou imprimé) mais par l'électronique (email, centres de documentation; services, etc.). On prend connaissance du message à l'écran et on l'imprime ou non. Les outils de traduction répondent à ce besoin d'immédiateté; de disponibilité et de commodité. Civilisation des grands marchés Les entreprises industrielles et commerciales fonctionnent de plus en plus à l'échelle internationale et la circulation des produits est pratiquement libre. Le savoir des langues qui était autrefois réservé à une "élite" est devenue accessible à tous. Les dictionnaires, les bases de données terminologiques, lexicographiques ou documentaires sont devenues des produits mis à la disposition du grand public. La traduction automatique contribue à la mise en valeur et à l'exploitation des diverses linguistiques. Civilisation et sauvegarde planétaire Actuellement, les nations tentent de mieux collaborer et de s'entraider
le cas échéant. Les organismes publics ou semi-publics internationaux
(par exemple l'ONU, Greenpeace,
Médecins
du Monde) développent leurs actions humanitaires aux quatre
coins du monde. La diversité linguistique ne doit pas être
un obstacle à la coopération.
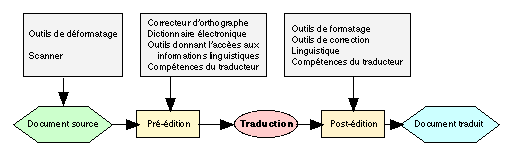
5. L'évolution historique des systèmes d'aide à la traductionL'histoire de la traduction automatique (TA) est marquée par deux étapes qui se distinguent de par l'architecture des systèmes. La première étape voit le développement du système direct, la seconde du système de transfert.Système direct Dans le premier cas, après une analyse morphologique du texte source, la consultation du dictionnaire bilingue fournit mot à mot les équivalences traductiques. Par la suite, des règles locales redéfinissent l'ordre des mots. Finalement, le texte cible est traduit automatiquement. La plupart des systèmes qui ont été créés dans les années 60 comme Systran ont été développés dans cette optique. Ce procédé a toutefois pour inconvénient la production d'un grand nombre de lignes de programmes et de grands dictionnaires. Pour un système bilingue unidirectionnel; l'approche directe conserve en revanche sa validité lorsqu'elle s'accompagne d'un modèle cohérent comme pour le système TAUM-Météo, qui traduit des bulletins météo régionaux du Canada de l'anglais vers le français, avec un vocabulaire très limité (moins de 1000 mots). Le système est très simple et se fonde sur l'identification des différents éléments d'une situation climatique en fonction des caractéristiques syntaxiques des phrases sources: vent, localisation, température, etc. Sa mise en place a permis de résoudre une situation très spécifique: les traducteurs devaient rédiger ces bulletins se plaignaient de la routine de leur travail et démissionnaient rapidement. Système de transfert La deuxième génération des systèmes de TA suppléent aux défaillances de ceux de la première grâce à des modélisations linguistiques plus élaborées qui sont ensuite utilisées pour l'analyse et la génération des langues traitées. Ils distinguent les connaissances et les modules monolingues des multilingues. Ainsi durant les années 70, les systèmes de TA dits de transfert et à interlangue voient le jour. Les systèmes de transfert; tel Metal possèdent 3 modules. En ajout à l'analyse en langue source et à la génération en langue cible, un module de transfert établit les équivalences entre deux langues données. Ces systèmes établissent les liens traductiques grâce à des liens contextuels qui peuvent parfois occasionner des changements d'ordre structural. Par ailleurs, ces systèmes sont caractérisés par des dictionnaires bilingues et des règles d'équivalences lexicales selon le contexte où le mot ou l'expression apparaît. Les systèmes de TA à interlangue présentent deux modules: l'un pour l'analyse, l'autre pour la génération. L'analyse linguistique du texte source permet d'obtenir une représentation intermédiaire indépendante des langues sources et cibles. A cette fin, le système utilise une interlangue en faisant appel soit à des primitives sémantiques ou logiques soit à un modèle du domaine voire à la description des connaissances du monde. La génération du texte en langue cible intervient à partir de cette représentation intermédiaire. D'un point de vue conceptuel; ces systèmes sembleraient être les mieux adaptés pour les systèmes multilingues. Contrairement au systèmes de transfert; une langue supplémentaire n'implique ni la création de nouveaux modules d'analyse ni celle d'un module de génération pour cette langue. Cependant; dans la pratique, l'élaboration de l'interlangue s'avère très difficile car ces éléments extraits du texte et leur placement ralentissent l'analyse linguistique. C'est pour cette raison que la plupart des systèmes dits de deuxième génération sont basés sur une architecture de transfert. Actuellement; on assiste à une convergence entre l'architecture de transfert et l'architecture interlangue. Un avantage dont toute personne qui désire traduire pourrait profiter pourrait à l'avenir tirer profit. Scénario montrant l'utilisation du système de traduction Dans les systèmes de traduction automatiques et semi-automatiques, l'utilisateur peut (et, pour assurer la qualité) doit intervenir à différents moments du processus de la traduction: lors de la préparation et de la désambiguisation du texte source, de la révision du texte cible et lors de la traduction elle-meme en mode traduction assistée. L'utilisateur et l'outil de traduction automatiqueLa figure 1 montre le processus de traduction lorsque celui-ci est effectué avec un outil de traduction automatique. Dans une premiere phase; d'abord le texte source est passé au scanner si celui-ci n'est pas fourni sous forme électronique, ensuite il est passé au correcteur orthographique.
La préédition: intervention avant la traductionA ce stade, le traducteur dialogue avec le système pour adapter le texte source de la traduction soit dans sa forme (correction orthographique, traduction d'un mot qui ne figure pas dans le dictionnaire), soit dans son contenu. Pour ce faire, le traducteur demande au système de comparer les termes contenus dans le texte source avec ceux existant dans la base de terminologie. Le système met en évidence les termes inconnus. Le traducteur rentre les nouveaux termes dans la base. En guise d'exemple, dans le système Metal, une fois le texte enregistré, le traducteur peut annoter et valider la sélection des parties du document à traduire. Il crée ainsi un fichier destiné au module de traduction qui ne contient que les éléments à traduire. Un second fichier mémorise la mise en page du texte source, de façon à ce que celui-ci soit restaurée à la fin de la traduction. Enfin, une phase de préanalyse morphologique identifie les mots inconnus auxquels le traducteur, qui est guidé par un menu, peut associer une description lexicale.La traduction automatique signifie: pas d'intervention au cours du processus. Postédition: intervention massive du traducteurLors de cette phase, l'utilisateur est grandement sollicité, ce mode d'intervention a recours à l'expertise humaine pour résoudre les ambiguïtés. Le système présente à l'utilisateur soit des paraphrases; soit divers sens ou même des référents pour un mot donné. L'utilisateur se heurte à cet égard à deux difficultés supplémentaires: à sa connaissance linguistique limitée ou incomplète, partiellement corrigée par le contrôle du dialogue par menus et aux ambiguïtés produites par le système. Ceci implique l'utilisateur doit avoir une bonne connaissance de ce dernier.Celui-ci doit relire et corriger le texte cible. Pour ce faire, il dispose
d'outils similaires à ceux des prééditeurs (traitement
de texte spécialisé avec accès intégré
à des dictionnaires bilingues, de synonymes, etc.). De surcroît
un outil comme Metal attache une cote de fiabilité à chaque
phrase traduite.
Limitations et avantages des outils de traduction automatique et semi-automatique. Les systèmes de traduction disponibles sur le marché ne peuvent être utiles que pour la traduction de documents structurés et dont le vocabulaire se limite à un domaine précis, comme par exemple des documents scientifiques ou commerciaux. Ils permettent aux traducteurs de se dégager des tâches répétitives et ennuyeuses; comme ce fut le cas dans le cadre de TAUM-Météo. En revanche, ils ne sont guère adaptés aux textes publicitaires ou de marketing et surtout pas à des textes littéraires. Leur rentabilité pourra être garantie si le traducteur a appris à bien les manier et à alimenter le dictionnaire avec sa propre terminologie. C'est la condition sine qua non pour obtenir des résultats satisfaisants, sans omettre le temps nécessaire à la relecture et à la correction. Une fois rodé, il permet d'accélérer le processus de traduction (révision comprise) dès que le nombre de pages traduites atteint quelques milliers. Aujourd'hui, le règne de la seconde génération de systèmes de TA semble révolu. Une nouvelle ère s'ouvre qui conçoit le système de TA comme un outil de communication, quelle qu'en soit la forme (dialogue en ligne; interrogation doucmentaire ou dialogue écrit). Des efforts sont faits pour réutiliser les ressources lexicales et les outils grammaticaux. Il est certain que d'ici quelques années, d'autres entreprises seront en compétition, surtout si l'on tient compte que le marché de la langue et de la traduction atteindra d'ici l'an 2000 un montant de 655 millions de dollars et après l'an 2000 le milliard.
6. Mémoires de traductionLe milieu des années 1980 a vu le début du développement des mémoires de traduction, alors que, avant cela, l'industrie de prenait pas au sérieux l'intégration des outils de traduction dans des ensembles plus larges, notamment lorsqu'il s'agissait de mémoires de traduction. Cependant, aujourd'hui, la situation a changé et la plupart des projets de traduction d'un certain volume prévoient l'application de cette technique. Partant, il faut connaître le fonctionnement les mémoires de traduction, savoir quelle est leur utilité pour le traducteur et observer quels sont les principaux produits disponibles sur le marché.Qu'est-ce qu'une mémoire de traduction? Généralités Une mémoire de traduction est une base de données contenant un grand nombre de phrases et leurs traductions. Le traducteur peut développer cette base de deux façons distinctes: manuellement ou à l'aide de ce qu'il est convenu d'appeler un outil d'alignement; dans le premier cas, il l'alimente au fur et à mesure qu'il traduit, en y incorporant non seulement le texte dans la langue source, mais aussi sa traduction dans la langue cible; dans le second cas, grâce à l'outil, il introduit automatiquement dans la base de données dans textes complets dans les deux langues et le programme se charge de rechercher les correspondances. Cala fait, quand le traducteur introduira dans la base un nouveau texte à traduire contenant des phrases ou des segments de phrases similaires à ceux qui figurent en mémoire avec une traduction donnée, le logiciel lui suggérera la traduction qu'il avait emmagasinée: au traducteur de l'accepter ou non. Toutes les parties non acceptées ou celles pour lesquelles aucune traduction n'existe devront être traduites. Eléments de la mémoire de traduction La mémoire de traduction est généralement composée des éléments suivants:
Listes terminologiquesLa mémoire de traduction permet d'utiliser des listes terminologiques, grâce auxquelles le traducteur recherche ou ignore des termes spécifiques lors de l'établissement des parties de texte à traduire. Ces listes peuvent d'ailleurs être actualisées en cours de traduction.Les mémoires de traduction permettent évidemment de réutiliser la terminologie déjà fixée, mais aussi, ce qui est moins évident, de tirer profit de segments entiers de texte déjà traduit par le biais d'algorithmes de correspondance partielle évolués, afin d'assurer l'homogénéité de l'ensemble. Ainsi, toute correspondance trouvée dans une traduction antérieure peut être récupérée et copiée avec le texte soumis à traduction. Le traducteur peut procéder à tout moment au remplacement automatique des correspondances totales trouvées dans la mémoire de traduction. En cas de textes particulièrement longs, l'utilisateur peut insérer des signets pour marquer l'endroit où il s'est arrêté et pouvoir y revenir ultérieurement. Les listes terminologiques peuvent aussi être utilisées lors de la révision de la traduction au moyen de fonctions de post-édition. Dans ces deux cas, la mise à jour de la mémoire est faite automatiquement à l'issue de chaque session de corrections. Gestionnaire de tâchesLa mémoire de traduction peut être utilisée avec un gestionnaire de tâches et permettre qu'en cas de configuration en réseau local, plusieurs traducteurs utilisent la même mémoire de traduction et la même base de données terminologiques. La procédure d'installation en réseau est relativement simple: on intègre la mémoire de traduction dans le processus de gestion des tâches en plaçant sur un serveur (par exemple sous MS Windows NT 4.0) un démon qui surveille continuellement certaines listes. Dès qu'une demande arrive, elle est traitée automatiquement et le système de gestion des tâches transmet les ordres (connexion, segmentation, pré-traduction automatique) à la mémoire de traduction. Une fois que les données sont préparées à l'intention du traducteur, le système les comprime et les archive, puis recherche quel est le traducteur le plus apte à traduire le texte en question en fonction de divers critères: type de documents, volume du texte, combinaison de langues, disponibilité du traducteur. Puis, le fichier est envoyé au traducteur sélectionné via FTP (que ce soit par modem, réseau, ISDN ou internet). La version de la mémoire de traduction est installée chez le traducteur en configuration "client" du système de gestion des tâches. Celui-ci installe le fichier contenant la commande et envoie un message sur l'écran du traducteur pour le prévenir. Ce dernier n'a qu'à sélectionner la commande et la mémoire de traduction se charge automatiquement avec les paramètres utiles pour la traduction ainsi que les données à traduire. Une fois achevée, la traduction est renvoyée par la même voie, le système de gestion des tâches l'achemine aux réviseurs puis, avant de la faire parvenir au destinataire final, en vérifie automatiquement la consistance terminologique, et contrôle d'autres données purement techniques telles la pagination, l'intégrité de la structure SGML/HTML, etc. Par ailleurs, toutes les traductions effectuées en se servant du gestionnaire de tâches sont archivées automatiquement dans la mémoire de traduction, en vue d'une utilisation ultérieure.
TraductionLors d'une session de traduction, le texte à traduire apparaît dans la fenêtre de traduction: le segment de texte soumis à la traduction est mis en évidence. Le traducteur effectue sa traduction en écrasant le texte source affiché dans cette fenêtre. L'éditeur de traduction offre les fonctionnalités habituellement requises pour une traitement efficace du texte et protège les informations relatives au formatage du texte source. Il permettra aussi de faire des corrections en phase de post-édition.Réutilisation des informationsLa fenêtre de la mémoire de traduction affiche le segment de texte actif et, le cas échéant, une correspondance totale ou partielle dans la langue cible. La mémoire de traduction indique, au fur et à mesure de la traduction, si une partie du texte contient une correspondance partielle ou totale avec ce qui a été traité précédemment: dans ce cas, le traducteur peut réutiliser ces traductions en appuyant sur une combinaison de touches. Il peut également mettre à jour les informations contenues dans la mémoire de traduction et peut même sélectionner le remplacement automatique de toutes les correspondances totales de segments et se concentrer uniquement sur les nouveaux segments, ce qui est particulièrement utile en cas d'actualisation d'un texte.Recherche de termes dans le dictionnaireLa fenêtre du dictionnaire affiche toutes les entrées trouvées dans le dictionnaire pour les termes du segment actif, ce qui garantit l'homogénéité de la terminologie utilisée. Une interface permet également de réutiliser les fonds de terminologie existants.Gestion du projet de traductionIl est possible de mettre toutes les informations relatives à un projet (fichiers et références) dans un dossier en ligne contenant des informations linguistiques (phrases du texte source et leur traduction) et des informations associées à chaque unité de traduction, telles que
Le traducteur peut également conserver d'autres informations, comme par exemple Intégration de traduction antérieures dans la mémoire de traduction Si le traducteur possède des fonds de traductions créés avant l'utilisation d'une mémoire de traduction, il lui est loisible d'établir des liens avec les textes source pour créer un début de mémoire de traduction, grâce à ce qu'on appelle un outil d'alignement. Pour ce faire, il faut mettre en vis-à-vis le texte source et le texte cible et l'outil en question se charge s'établir les correspondances et d'en alimenter la mémoire de traduction. Il est également possible d'inverser les langues contenues dans la mémoire de traduction. Mémoires de traduction existant sur le marché Les principales mémoires de traduction disponibles sur le marché sont celles mises au point par TRADOS AG (Translator's Workbench) http://www.trados.com/products/solution.htm,
Scénario montrant l'utilisation de la mémoire de traduction Le traducteur et la mémoire de traduction Dans ce processus, la phase de préédition identique à celle du processus de traduction avec des outils de traduction automatique. Traduction assistée: intervention avant et en cours de processusDans un premier cas, l'utilisateur veut se servir d'une mémoire de traduction pour sa traduction. Pour cela, il doit la créer. Il peut développer cette base de deux façons distinctes: soit manuellement ou soit à l'aide de ce qu'il est convenu d'appeler un outil d'alignement. Dans le premier cas, il l'alimente au fur et à mesure qu'il traduit, en y incorporant non seulement le texte dans la langue source, mais aussi sa traduction dans la langue cible; dans le second cas, grâce à l'outil, il introduit automatiquement dans la base de données dans textes complets dans les deux langues et le programme se charge de rechercher les correspondances. Cela fait, quand le traducteur introduira dans la base un nouveau texte à traduire contenant des phrases ou des segments de phrases similaires à ceux qui figurent en mémoire avec une traduction donnée, le logiciel lui suggérera la traduction qu'il avait emmagasinée: à l'utilisateur de l'accepter ou non. Toutes les parties non acceptées ou celles pour lesquelles aucune traduction n'existe devront être traduites.Lors d'une session de traduction, le texte à traduire apparaît dans la fenêtre de traduction: le segment de texte soumis à la traduction est mis en évidence. Le traducteur effectue sa traduction en écrasant le texte source affiché dans cette fenêtre. L'éditeur de traduction offre les fonctionnalités habituellement requises pour effectuer un traitement efficace du texte et protège les informations relatives au formatage du texte source. Il permettra aussi de faire des corrections en phase de post-édition. Réutilisation des informationsMaintenant que la mémoire de traduction existe, l'utilisateur peut engagé une session de traduction avec le système. A ce moment là, la fenêtre de la mémoire de traduction affiche le segment de texte actif et, le cas échéant, une correspondance totale ou partielle dans la langue cible. La mémoire de traduction indique, au fur et à mesure de la traduction, si une partie du texte contient une correspondance partielle ou totale avec ce qui a été traité précédemment: dans ce cas, le traducteur peut réutiliser ces traductions en appuyant sur une combinaison de touches.Il peut également mettre à jour les informations contenues dans la mémoire de traduction et peut même sélectionner le remplacement automatique de toutes les correspondances totales de segments et se concentrer uniquement sur les nouveaux segments, ce qui est particulièrement utile en cas d'actualisation d'un texte. Recherche de termes dans le dictionnaireSi la mémoire de traduction est reliée à un dictionnaire éléctronique ou à une base terminologique, le traducteur peut appeler cette ressource linguistique depuis la mémoire de traduction. Ainsi, la fenêtre du dictionnaire affiche toutes les entrées trouvées dans le dictionnaire pour les termes du segment actif, ce qui garantit l'homogénéité de la terminologie utilisée. Une interface permet également de réutiliser les fonds de terminologie existants.Postédition: intervention après traductionA ce stade, le traducteur doit relire son texte au niveau syntaxique, cohérence du texte puis le reformater.Conclusions sur les mémoires de traduction Sans entrer dans des détails purement techniques, voici les points des mémoires de traduction:
|