Le paradigme GPS
Le titre de l'ouvrage le plus complet sur GPS est "Human Problem Solving" (Newell 1972). Ce titre est significatif car il exprime à la fois l'ambition du projet et son ancrage dans la psychologie cognitive. Les auteurs ne se sont pas contentés de construire un modèle spéculatif sur ordinateur, mais ils ont eu l'ambition de créer un modèle général de la capacité humaine à résoudre des problèmes et d'ancrer ces recherches grâce à des études cliniques avec des sujets. L'optimisme initial des auteurs peut s'exprimer dans les cinq points suivants résumant l'essentiel de leur théorie sur le fonctionnement du "Problem Solver" humain et de sa modélisation. (Newell 72:788)
- Lorsqu'un humain est engagé dans certaines tâches de résolution de problème, on peut le représenter comme un système de traitement de l'information.
- Cette représentation peut être formalisée en détail. On peut simuler un processus de résolution de problème et un problème peut être décrit comme une structure de données manipulée par ce processus.
- Formaliser signifie écrire un système qui implémente l'ensemble du système de traitement de l'information. Un système est une collection de programmes d'ordinateur. Ainsi une simulation peut être à la fois complexe et automatisée.
- Il existe des différences substantielles entre ces programmes en ce qui concerne leur tâche et leur domaine d'application. Ceci est le résultat du fait que les gens s'attaquent aux problèmes de différentes façons et que les problèmes n'ont pas la même structure.
- L'environnement de tâche (angl. "task environment") détermine largement le comportement du "problem solver". C'est avant tout l'environnement qui est complexe. Celui qui résout des problèmes humains doit réduire cette complexité pour être capable de trouver une solutionr.
Un système de traitement de l'information à la Newell et Simon est un engin qui s'adapte à son environnement. En observant un tel engin, on ne peut percevoir que certaines de ses caractéristiques. Un "problem solver" dans cette école de pensée ressemble donc aux systèmes de décision de la théorie de système; à la différence près que les auteurs proposent un vrai langage pour modéliser symboliquement des tâches humaines de résolution de problème. A noter aussi le deuxième parallèle: Simon fait l'hypothèse de travail suivante:
"A man, viewed as a behaving system is quite simple. The apparent complexity of its behavior over time is largely a reflection of the complexity of the environment in which he finds himself" (69/81:65).
Donc, la complexité réside dans l'environnement. Le décideur (suffisamment peu complexe pour être sujet à une modélisation détaillée) arrive à réduire cette entropie à des représentations somme toute assez simples. Cette affirmation est optimiste comme la recherche en IA depuis 1972 l'a amèrement démontré.
Un modèle pour l'architecture de l'esprit humain
Dans les années soixante, les modèles psychologiques du traitement de l'information en vogue semblent être inspirés par l'architecture de l'ordinateur (cf. par exemple Atkinson and Schiffrin), les années cinquante étant sous le règne de la théorie de l'information (Broadbent). Examinons les caractéristiques du système de traitement humain de l'information selon le livre "Human problem solving" (cf. Newell 72:808):
Cette liste qui résume les caractéristiques essentielles du "human problem solver" parle d'elle-même. Elle résume l'attitude optimiste des années de jeunesse de la science cognitive qui visait à construire une théorie précise et parcimonieuse de l'esprit humain. Toutefois, étant donné le grand sérieux avec lequel ces affirmations ont été testées expérimentalement, elles ont toujours une certaine véracité. Seulement, il apparaît que leur portée est plus limitée. L'esprit humain peut effectivement être modélisé comme un processeur sériel ayant les caractéristiques énumérées ci-dessus, mais seulement quand il accomplit un certain genre de tâches. Aujourd'hui, ce modèle possède paradoxalement plutôt une valeur prédictive qu'une valeur homomorphique à la pensée humaine. Certaines sommités en IA comme Minsky (79 et 88) affirment qu'aucun traitement humain n'est effectué en sériel mais qu'il a cette apparence. Il existe des indications empiriques montrant que l'essentiel du raisonnement humain est effectué en parallèle, la reconnaissance de formes ne pouvant pas être faite autrement étant donnée l'immense quantité d'informations à gérer*1. De la reconnaissance de formes, on peut passer au raisonnement analogique, aux associations en général et postuler que le sériel n'est qu'un épiphénomène. Ainsi les symboles de Newell et Simon n'auraient pas d'existence isolée mais ils seraient connectés à des réseaux sous-symboliques complexes. Dès lors, la mémoire ne ressemble pas à un processeur sériel mais certains processus peuvent être décrits comme des flux sériels à un certain niveau d'abstraction.
Enfin, malgré les critiques que l'on peut adresser au modèle de Newell et Simon, cette tradition de recherche garde sa valeur dans les domaines de la résolution de problèmes et de la planification. Parmi toutes les activités cognitives, on peut observer une grande variation des caractéristiques des tâches, comme l'ampleur de l'information à traiter, le taux de transmission de l'information, le temps de réponse observé (et imposé par l'environnement) (cf. Reddy 88: 12). La classe des tâches qui traitent relativement peu d'informations et qui ne nécessitent pas de temps de réponse immédiat peut être modélisée avantageusement par un modèle sériel. Un exemple contraire (beaucoup d'informations et un temps de réponse immédiat) est la vision. Il est important de réaliser que tout algorithme que propose l'IA ou la psychologie comme modèle de résolution de problème est lié à un modèle de l'esprit humain. Pris hors contexte, ces modèles perdent leur statut théorique. Si une telle opération est faite, il faut reconceptualiser leur usage. Il est tout à fait légitime de postuler que l'activité du décideur est séquentielle, que sa capacité de mémoire de travail est limitée, qu'il a de la peine à mémoriser des symboles, etc. si l'on se situe à un niveau d'abstraction théorique plus élevé. Nous nous intéressons à la modélisation des prises de décisions et non pas aux processus actifs dans le cerveau. Newell, peut-être sous l'influence de la critique qui lui a été adressée, a eu très tôt cette même stratégie en déclarant que la priorité appartient à l'analyse de la cognition au "knowledge level". Le niveau du contenu des connaissances symboliques se prête en effet toujours bien à l'école de modélisation née du "human problem solver".
Probablement, le premier programme écrit en IA était le "Logic Theorist" de Newell et Simon. Ce programme état capable de prouver quelques théorèmes de la logique symbolique élémentaire. Cet programme n'était pas très impressionnant en ce qui concernait son "intelligence", mais il a permis la cristallisation des idées qui ont abouti à GPS (1957-1972). Ci-dessus, nous avons présenté une partie de son "infrastructure" théorique. En accord avec les principes généraux auxquels croyaient Newell et Simon, les recherches autour de GPS se sont concentrées sur l'étude des invariants de la capacité humaine de résolution de problème. Il a été montré par les auteurs qu'il existe très peu de connaissances générales de résolution de problème. La très grande majorité de ce type de connaissance est orientée autour des tâches. Ainsi, la puissance d'une "machine" humaine à résoudre un problème ne réside pas dans les mécanismes de raisonnement de base (le mécanisme d'inférence et les heuristiques très générales), mais dans leur façon de stocker et d'utiliser des connaissances. D'où le fameux slogan: "In the knowledge lies the power".
Examinons maintenant la "means-ends analysis" qui est au coeur de GPS. Un problème est la différence entre l'état courant A et l'état désiré B du monde. Le problème génère le but de réduire cette différence, c'est-à-dire de transformer A en B. Ensuite, il faut trouver les moyens. Un problème peut être décrit plus précisément avec des objets (choses à manipuler) et des opérateurs. Les objets sont décrits par leurs attributs et par les différences entre des paires d'objets. Ainsi un problème (une différence entre des attributs d'objets) peut être décomposé en sous-problèmes. Un opérateur est un objet qui peut être appliqué à une classe bien définie d'objets pour les transformer ou pour créer des nouveaux objets. Chaque "problem solver" possède des tables de différence qui indiquent quel opérateur appliquer pour réduire une différence spécifique. Ce type de connaissance dépend beaucoup du type de la tâche à résoudre. Il fait partie de l'environnement de tâche qui contient également la description du problème ainsi que le but. En somme, le formalisme qui se cache derrière l'application d'opérateurs pour réduire la différence ressemble beaucoup au modèle TOTE de Miller et al. déjà discuté dans le chapitre 2. L'idée de base est la même. Pour poursuivre un but, le "problem solver" doit décomposer un problème en sous-problèmes plus simples auxquels il peut appliquer des opérateurs connus. Ce mécanisme forme encore aujourd'hui le pilier des modèles les plus complexes de la planification.
GPS contient trois heuristiques principales de résolution de problème présentées ci-après. Chacune peut être appliquée récursivement, c'est-à-dire qu'elle peut se contenir elle-même comme partie lorsqu'elle est utilisée. Ou autrement dit, lorsqu'on utilise une méthode pour résoudre un problème, on trouve parfois des sous-problèmes auxquels on applique de nouveau la même méthode.
Lorsqu'on donne un problème (une différence) à GPS, le programme d'abord crée le but de transformer un objet A en un objet B. Le programme va s'arrêter s'il ne trouve pas de différence entre A et B. Sinon il va appliquer un opérateur O à l'objet A. Si cette procédure permet de créer un objet A' qui a des attributs identiques à ceux de B, il s'arrête également avec un succès. Si cette simple méthode ne marche pas, ce qui est normalement le cas au début d'un processus de résolution de problème, GPS tente de réduire la différence entre A et B d'une façon graduelle. Autrement dit, le programme essaie de créer un objet A' qui est plus près de B que A. Ensuite, il va tenter d'appliquer le même principe à A' pour créer un objet A" qui est encore plus près de B et ainsi de suite. Cet algorithme possède donc trois types de stratégies opérationnelles: (1) transformer un objet (2) réduire la différence, (3) appliquer un opérateur.
Ce modèle d'application d'opérateurs pour modéliser le raisonnement analytique est encore très répandu. Des programmes de planification comme STRIPS et ses successeurs (Fikes et Nilsson 71) se fondent sur les mêmes principes. Un opérateur peut être appliqué sous certaines conditions, il peut faire certaines choses et produire une certaine classe de résultats. Ces opérateurs constituent les tâches primitives qu'un système peut effectuer. Ensuite, il existe des plans bien plus compliqués. Le planificateur moderne tente de réduire des tâches compliquées à des actions primaires et en règle générale de construire un réseau de tâches exécutables (qui peut être sujet à révision). Dans ce cas, on parle de planification dynamique car elle tient compte des changements de l'environnement. Nous n'allons pas aborder ce sujet en détail. Nous sommes d'avis qu'il faut d'abord tenter d'exploiter des techniques plus simples qui ne nécessitent pas les connaissances considérables qu'il faut pour construire un planificateur qui ne fonctionne que pour un domaine restraint. Nous allons maintenant introduire les systèmes de production qui permettent de programmer des systèmes comme GPS et qui sont à la base de la grande majorité des systèmes expert.
Une règle de réécriture élémentaire prend une chaîne de symboles pour la transformer en une autre chaîne de symboles. Par exemple la règle
(état A) -> (but B)
transforme la chaîne "(état A)" en "(but B)". Une grammaire génératrive est une collection de règles de réécriture qui, par étapes successives, peut transformer une "entrée" en une "sortie". Un bon exemple est donné par les analyseurs syntaxiques qui transforment une chaîne de symboles représentant une phrase en une chaîne axiomatique représentant la structure grammaticale d'une phrase. Il s'agit ici d'une analyse "bottom-up", c'est-à-dire l'analyse va d'un objet non structuré (une chaîne de symboles représentant une phrase) vers l'objet structuré et grammatical. L'analyse peut être effectuée dans l'autre sens. A partir d'un axiome (une grammaire), on peut générer des phrases. Sous une forme modifiée (pour éviter l'explosion des possibilités), on peut effecteur une analyse "top-down". On génère des phrases possibles jusqu'à ce que la phrase que l'on veut analyser corresponde. Les deux types de transformation "haut en bas" et "bas en haut" (ou "gauche à droite" et "droite à gauche" si l'on se réfère au sens de la flèche dans les règles) peuvent être combinés. C'est que fait GPS par exemple pour appliquer des opérateurs. La logique de GPS peut être comparée par quelques aspects à un analyseur syntaxique: il s'agit d'effectuer une transformation symbolique. En effet, une liste de différences à réduire a comme but (formel) de transformer une chaîne d'états d'attributs en une autre.
Les systèmes de production sont une généralisation des règles de réécriture. Les règles peuvent être plus complexes. Ensuite, il existe un mécanisme automatique qui utilise les règles, il s'agit du moteur d'inférence qui applique un jeu de règles aux faits (données) en mémoire. Voici donc les composantes essentielles d'un système de production:
si <SITUATION> alors <ACTION>
Dans le contexte d'un système de production simple à chaînage avant (notion expliquée ci-dessous), une telle règle est utilisée de la façon suivante: quand le moteur découvre une certaine situation (appelée aussi condition) dans la base de faits, la règle est "réveillée" et prête à être utilisée. Donc, la première fonction du moteur est évaluative ou interprétative. Il cherche dans la base de faits afin de trouver des règles qu'il peut appliquer. Dans un moteur élémentaire, si une règle correspond à une situation, elle est exécutée. En règle générale, la partie action de la règle est utilisée pour transformer la base de faits. Donc, au lieu d'utiliser les termes de "situation" et d'"action", l'on peut également utiliser les termes de "si - alors" ou de "condition - conclusion". Il s'agit d'une interprétation plus logique d'une règle de production qui privilègie la fonction du contenu des clauses et non pas la manière dont une règle est manipulée.
si <CONDITION> alors <CONCLUSION>
Examinons deux règles dans la figure 4-4 "Exemple de règles" [p. 135]
Dans un système de production plus sophistiqué, si le moteur trouve plusieurs règles applicables, il doit choisir la meilleure des règles. C'est sa fonction de contrôle. Souvent, il utilisera un autre jeu de règles pour le faire. Dans ce cas, on parlera de sélection heuristique de règles et ces règles de choix sont des méta-règles. Un moteur d'inférence travaille en cycles. Comme on l'a déjà dit, il scrute la base de faits et il essaye de trouver des règles dont les conditions correspondent à un ou plusieurs faits. Ensuite, il exécute la règle qui lui semble être la meilleure. En général, ceci a un effet sur la base de faits: la partie action d'une règle rajoute un fait à la base ou alors elle en enlève un. Par la suite, le moteur regarde de nouveau la base de faits pour y appliquer une règle. Un tel calcul ne peut évidemment pas durer éternellement. Ainsi, il existe toujours au moins une règle qui conclut qu'un problème a été résolu ou que le problème n'a pas de solution. Ces règles commandent au moteur d'arrêter le processus.
Essayons de voir la correspondance postulée entre ce mécanisme informatique et la théorie du processeur de traitement humain d'information. Les jeux de règles font partie de la mémoire à long terme. La base de faits que l'interpréteur utilise représente la mémoire à court terme et le moteur représente le processeur de résolution de problème. Cette architecture simple devient plus puissante si l'on permet au système de transformer les règles ou encore si on inclut un processus pour sélectionner les meilleures règles. Un système capable de varier l'ordre dans lequel il applique les règles peut modéliser un comportement adaptatif, c'est-à-dire que dans une même situation, on fera les choses différemment la prochaine fois. Un système qui peut réécrire ses propres règles (qui traite les règles comme des faits) peut modéliser l'apprentissage.
GPS était programmé avec des règles de production légèrement modifiées. Les opérateurs étaient les règles, seulement au lieu de posséder deux parties "si" et "alors", elles en avait trois: "si", "alors opération" et "alors résultat". Le "alors résultat" servait à sélectionner la meilleure règle. Lors de l'introduction des règles de réécriture, nous avons mentionné qu'une règle peut être utilisée dans les deux sens. Beaucoup de systèmes de production le font. GPS par exemple avait un peu cette capacité et nous allons maintenant approfondir la technique et les conséquences conceptuelles de ces deux modes de chaînage de règles.
RULE 1 decision-yes
IF (person is submitted to authorization regime)
Dans la règle "decision-yes" ci-dessus, nous avons la clause de conclusion "(the system made a final legal conclusion)". Conceptuellement, cette clause peut représenter un but de très haut niveau qui permet au système de déclencher le processus de résolution de problème et de faire tourner le moteur jusqu'à ce que ce but soit satisfait. Pour l'interpréteur, satisfaire ce but veut dire prouver que les faits dans la clause "si" sont aussi justes ("person is submitted to authorization regime" et "person gets an authorization"). Dans ce contexte, prouver signifie que les faits doivent exister dans la base de données. Implicitement, le moteur se crée donc deux sous-buts et il cherche deux règles qui peuvent créer et donc prouver ces deux faits. En traversant la base de règles, il va sans doute trouver la deuxième règle ci-dessous.
RULE 2 authorization-regime-yes
IF (person acquired real estate) (person is foreign)
Il sait maintenant qu'il peut prouver un des sous-buts ci-dessus, mais à condition qu'il arrive à prouver les nouveaux sous-buts: (person acquired real estate) et (person is foreign). Ensuite, il doit continuer de la même façon jusqu'à ce qu'il rencontre les faits qui représentent le problème. Par exemple, on peut imaginer que (person acquired real estate) et (person is foreign) sont déjà dans la base de faits et qu'ils représentent partiellement la description d'une situation juridique à résoudre. Ce processus de recherche téléologique est appelé "chaînage arrière" car le mécanisme part d'un but général, le divise en sous-buts (ou sous-problèmes à résoudre) et ainsi de suite jusqu'à ce qu'il tombe sur des données (faits) qui "prouvent" un sous-but. Dans la plupart des systèmes, l'algorithme de chaînage arrière est plus compliqué, les faits et les règles peuvent contenir des variables et le moteur peut explorer plusieurs hypothèses et faire marche arrière. On peut aussi dire qu'un tel algorithme "descend" un arbre de décision, les noeuds à l'intérieur de l'arbre représentant des conclusions à prouver et les noeuds au bout de l'arbre les faits.
(B) Le chaînage avant fonctionne en sens inverse. Il est "poussé par les faits" (angl. "fact-driven"). Reprenons l'exemple de nos deux règles. Elles peuvent être utilisées pour un chaînage avant. Dans ce cas, le moteur du système est en attente. Si maintenant, on écrit les deux faits "(person is foreign)" et "(person acquired real estate)", le moteur va immédiatement prendre ces deux assertions et les comparer aux conditions des règles. Il trouvera qu'elles correspondent à la partie "si" de la deuxième règle. Cette règle sera appliquée et le système concluera que "(person is submitted to authorization regime"). Imaginons maintenant une troisième règle:
RULE 3 authorization-yes
IF (person is a company)
Si le moteur trouve également dans la base de faits l'assertion que "(person is a company)" et "(real estate is used as production site)", il peut conclure que "(person gets an authorization)". En combinant les deux conclusions intermédiaires gagnées par l'application de ces deux règles, il peut faire se déclencher la première règle et conclure que "(the system made a final legal conclusion)".
Cette petite discussion devrait permettre de comprendre l'essentiel de ces deux mécanismes de base, ainsi que la fonction d'un moteur d'inférence très simple. En réalité, et comme on le verra plus tard, un système à base de règles utilisable pour la modélisation est plus complexe. Il utilise notamment des variables pour faire référence à un type de fait au lieu d'un fait très concret. Sinon, on ne pourrait jamais appliquer une base de règles à un ensemble varié de faits. Ainsi, on pourrait réécrire la règle 2 de la façon suivante:
RULE 2b authorization-regime-yes
IF (?person acquired real estate)
Le symbole ?person représente une variable. On peut la remplacer par n'importe quel autre symbole. Un fait dans la base de faits correspond maintenant à une clause d'une règle si une correspondance structurelle (ou "terme à terme", angl. "match") peut être établie. Ainsi on peut faire correspondre le fait "(Dupont is foreign)" à "(?person is foreign)". En chaînage avant, la règle va se déclencher si les deux clauses de la condition ont trouvé une correspondance et si les variables peuvent être unifiées. Ceci signifie que toutes les variables du même nom dans toutes les clauses doivent être liées au même symbole. Dans l'exemple, si "?person" est "Dupont" pour la première clause et ?person" est "Dunant" dans la deuxième, la règle ne va pas se déclencher puisqu'il ne s'agit pas de la même personne. Un raisonnement analogue s'applique au chaînage arrière.
SOAR est bâti sur deux concepts importants: (1) la méthode faible universelle (angl. "universal weak method") qui intègre toutes les méthodes universelles connues et (2) le "sub-goaling" universel qui structure la résolution d'un problème difficile en tâches gérables. En plus, Soar possède une capacité d'apprentissage. Il peut se souvenir des séquences de résolution de problème ayant eu du succèrs et les réutiliser dans les nouvelles situations.
Sans entrer dans les détails de l'architecture Soar qui aujourd'hui a fait un grand nombre d'adeptes dans le monde, il est intéressant de noter que le principe de recherche heuristique, déjà rencontré dans GPS, semble toujours posséder sa valeur. La principale différence vient du constat qu'il existe un grand nombre de méthodes de résolution de problèmes qu'il faut savoir coordonner. Ce modèle intègre également l'apprentissage qui, par le biais du "chunking" extrait des connaissances abstraites à partir d'une expérience et les associe à des types de buts. Dans les cas où un "chunk" appris ne fonctionne pas, le système peut introduire des variantes dans la séquence de résolution de problème. Lorsqu'une variante "marche", l'ancienne séquence est adaptée et aura plus de chances d'être utile dans l'avenir.
GPS était le précurseur direct ou indirect des systèmes de production qui sont utilisés pour faire des systèmes expert. Un ingénieur de connaissances (cognicien) s'intéresse au raisonnement humain seulement dans la mesure où il veut créer un programme qui exécute une tâche intelligente et, à la limite, dans la mesure où il désire comparer le savoir dans l'esprit humain et le savoir dans la machine. Un système expert possède donc une certaine affinité avec le raisonnement humain et il peut servir de modèle analytique pour modéliser un décideur.
Revenons maintenant sur les deux concepts de chaînage avant et arrière et résumons leur utilité pour la modélisation. Les deux méthodes de raisonnement correspondent plus ou moins à des aspects importants de l'activité de l'esprit humain. L'usage que l'on a fait des trois règles ci-dessus illustre le fait qu'une activité de résolution de problème est guidée à la fois par un raisonnement plus logique qui cherche à prouver une intention, une théorie, etc. et par un raisonnement plus immédiat qui propage ses conclusions à partir de faits vers l'avant.
Examinons les mécanismes de recherche arrière et en avant sous un angle un peu différent mais connexe: on pourrait modéliser un décideur par une simple base de faits (mémoire à court terme), des règles de production (mémoire à long terme) et un moteur d'inférence (processeur analytique). Pour simuler la perception d'un fait, on insère un fait dans la base de faits. Pour modéliser la réaction du décideur, on utilise un mécanisme de chaînage avant qui déclenche des règles. Ces règles aboutissent à des conclusions qui, à leur tour, déclencheront des règles, etc. Cette méthode corrsepond à la modélisation d'un type de raisonnement spontané, rapide ou routinier.
Le mécanisme du chaînage avant peut également être utilisé pour modéliser la création de buts, le partage d'un problème en sous-buts, ainsi que la poursuite simple de buts. C'est un peu le mécanisme de base de GPS. Etant donné un but compliqué, on peut faire appel à une règle qui nous dit comment substituer à ce but un ensemble de buts plus simples. Autrement dit, on écrit un certain nombre de faits qui représentent des buts dans la base de données. Maintenant, on peut utiliser des règles ayant pour condition une clause qui représente le but et d'autres règles qui représentent les faits nécessaires pour résoudre le but. Une fois que la règle est déclenchée et qu'elle a tiré des conclusions, elle se chargera d'ôter de la base de faits le but qui a permis de la déclencher. On utilise donc un mécanisme de chaînage avant pour simuler un chaînage arrière sur le plan conceptuel. Ceci dans le sens où le raisonnement part avec un but qu'il faut ensuite décortiquer en sous-buts pour arriver à des faits que l'on peut transformer peu à peu afin de les résoudre. On pourrait donc modéliser un raisonnement plus déductif du décideur avec cette stratégie des buts et des sous-buts. Toutefois, pour modéliser par exemple les situations où le décideur veut simplement savoir si une affirmation est juste, le chaînage arrière peut être plus élégant. Si le décideur veut savoir si une hypothèse est juste et s'il ne trouve pas le fait correspondant dans la mémoire, il essayera d'appliquer des règles jusqu'à ce qu'il puisse la prouver ou alors qu'il sache que c'est une tâche impossible.
Donc, de façon générale, on peut dire que l'on fait des inférences en avant lorsque l'on perçoit quelque chose (des faits sont insérés dans la base de faits) et on fait des inférences en arrière lorsque nous "cherchons" quelque chose. Ces processus peuvent être mélangés de plusieurs façons.
Nous avons déjà pu montrer l'usage multiple que l'on peut faire des règles. Malgré cette richesse que nous allons exploiter dans les chapitres suivants, il serait faux de réduire l'intelligence artificielle et la science cognitive computationnelle à des modèles utilisant des règles. Dans la sous-section suivante, nous allons survoler des mécanismes de représentation de connaissances alternatifs. Toutefois, l'essentiel de la partie pratique de ce travail est fondé sur l'usage de règles car cette technique, aujourd'hui, est totalement maîtrisée et bien disponible.
Generated with WebMaker
Le modèle GPS
Au début de la modélisation de la résolution de problème, on trouve l'approche "generate and test". "Générer et tester" signifie que le problème était défini en tant qu'ensemble de solutions possibles que l'on pouvait générer facilement. Le programme devait "simplement" choisir la meilleure réponse. La première contribution systématique de l'IA était de définir des méthodes de recherche s'appliquant à de larges espaces de solutions. On peut résoudre un problème de ce type en appliquant un algorithme qui génère la bonne solution, car elle existe même si elle est difficile à trouver. Toutefois, même pour certains problèmes simples, il existe une très grande quantité de solutions utiles, et le programme ne pourrait pas terminer sa recherche en temps utile. La résolution heuristique de problème consistait à trouver des algorithmes exécutables en temps utile mais ne garantissant pas la solution. Les heuristiques sont donc nées du besoin de réduire la complexité de l'environnement de problème.
Un opérateur peut affecter quelques attributs de l'objet et laisser d'autres inchangé. Ainsi on peut décrire un opérateur par les changements qu'il peut produire. Un opérateur de GPS a trois composantes:
La première composante indique si un opérateur est applicable. La fonction de transformation effectue la transformation de l'objet A en l'objet A'. La liste des différences réductibles est utilisée pour choisir le meilleur opérateur. La méthode de réduction cherche d'abord à réduire les différences les plus importantes et elle cherche l'opérateur le plus prometteur. Il peut arriver que la méthode de réduction trouve un opérateur pour les différences à réduire mais qu'il soit inapplicable, c'est-à-dire que ses préconditions ne correspondent pas à l'état (aux attributs) actuel de l'objet. Dans ce cas, GPS peut appliquer la méthode de transformation sur l'objet actuel A pour créer un objet A" qui permet d'appliquer le premier opérateur qui permet alors de produire A'. Il s'agit ici d'une sorte de raisonnement déductif. Finalement, GPS peut revenir en arrière sur ses décisions (angl. "backtracking") s'il s'engage dans une voie sans issue. Etant donné qu'il produit toujours un nouvel objet à partir d'un objet à transformer, ceci ne pose pas de problème. On peut chercher un ancien objet dans la mémoire et essayer d'appliquer un autre opérateur que celui qui l'a mené vers une impasse. Les systèmes de production
Un système de production est un algorithme computationnel pour manipuler des structures symboliques. Au coeur d'un tel programme se trouvent des règles de réécriture. Ces règles sont également utilisées à d'autres fins, par exemple pour définir des grammaires en linguistique ou en informatique. Ainsi nous allons d'abord donner une définition générale des concepts de réécriture et de grammaire générative.
Dans sa forme la plus simple, une règle de production possède la forme suivante: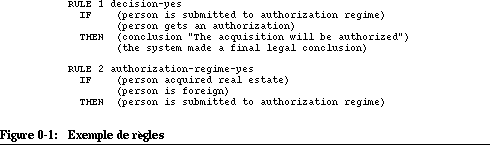
. L'exemple est inspiré d'une modélisation que nous allons discuter dans le chapitre 4. Pour le moment, il n'est pas nécessaire de comprendre les détails, mais juste de voir l'utilité générale d'une règle de production. Imaginez que l'on puisse décrire une situation de problème par un jeu de faits simples que l'on met dans une base de faits. On peut maintenant postuler l'existence d'un certain nombre de règles qui permettent de résoudre le problème, c'est-à-dire de prendre une décision légale à partir de ces faits. Chaque règle possède un nom, une partie "si" et une partie "alors". La première règle qui a comme nom le symbole "decision-yes" possède deux conditions: (person is submitted to authorization regime) et (person gets an authorization). Si ces deux conditions sont remplies par l'existence de ces deux faits dans la base de faits, on peut déclencher la règle et écrire dans cette base les conclusions de la règle. En l'occurrence, on conclut par exemple que "(The acquisition will be authorized)". La deuxième règle a son utilité par rapport à la première. Elle permet en effet de créer un fait (person is submitted to the authorization regime) qui sera utilisé comme condition par la première règle.
(person gets an authorization)
THEN (conclusion "The acquisition will be authorized")
(the system made a final legal conclusion)
THEN (person is submitted to authorization regime)
(real estate is used as production site)
THEN (person gets an authorization)
(?person is foreign)
THEN (?person is submitted to authorization regime) SOAR
Dans le livre "Universal Subgoaling and Chunking" de Laird, Rosenbloom et Newell (1986), l'architecture Soar est introduite. Venant de la tradition de Carnegie-Mellon et donc de GPS, il s'agit de nouveau d'un système de résolution de problème universel centré sur la recherche heuristique des espaces de problèmes. (Laird et al. 86: 286). Partant d'un état initial, le système tente d'appliquer un certain nombre d'opérateurs pour arriver à l'état désiré. Lorsque le programme rencontre une difficulté, il crée un sous-but et le traite comme problème indépendant à résoudre. Il définit donc des hiérarchies de buts ayant des espaces de problèmes indépendents. Contrairement à GPS, le système choisit des méthodes de résolution différentes selon la nature du problème. Laird et al. proposent dix sept méthodes de recherches heuristiques parmi lesquelles figure GPS. Discussion
La brève présentation de GPS et de quelques principes des systèmes de production qui peuvent être utilisés pour programmer un tel système montre bien l'esprit et le problème des pionniers de l'intelligence artificielle. La discussion des principes de la "means-ends analysis" et l'introduction des concepts liés aux systèmes de production peuvent donner une idée de la manière dont fonctionne GPS. Cette architecture permet de résoudre quelques beaux problèmes, par exemple de la cryptarithmétique. Cette réussite les a conduits à affirmer que les quelques principes de raisonnement qui fonctionnaient dans ces modélisations étaient plus ou moins les mêmes pour toutes sortes de problème. Ils pensaient que toute la difficulté dans l'avenir allait résider essentiellement dans le contenu des règles qu'il fallait mettre dans GPS. Citons de nouveau le fameux "In the knowledge lies the power" de Newell. Aujourd'hui, on a besoin d'une grande variété de méthodes de représentation des connaissances épistémiques et heuristiques. Nous allons en présenter quelques unes dans la sous-section suivante. On sait aussi que la puissance du raisonnement humain ne réside pas seulement dans les contenus isolés des connaissances, mais également dans l'organisation associative de sa mémoire et dans sa capacité d'apprentissage très étonnante. Toutefois, beaucoup d'idées pour la première fois mises en oeuvre dans cette modélisation qu'était GPS, persistent et restent valables. Seulement, leur portée a diminué.
THESE présentée par Daniel Schneider - 19 OCT 94

