Tank Wars!
Evolving Steering and Aiming Behaviour for Computer Game Agents
Abstract
This page describes the method used to obtain steering and aiming behaviour in autonomous computer game agents. The agents are tank-shaped vehicles equipped with mobile gun turrets. They learn to avoid collisions and fire each other in a two-dimensional maze environment. The tanks' behaviour is controlled by continuous time recurrent neural networks (CTRNN) [Beer 1996] whose parameters are optimized using genetic algorithms.Introduction
Traditional obstacle avoidance and also discrimination tasks, minimal cognition, short-term memory and selective attention [Beer 1996, Slocum et. al., 2000] are currently achievable by evolutionary robotics. However, to date only simple behaviour can be obtained and there is a long way to go until these techniques can be applied to physical robots in a useful manner. However simple behaviour is precisely what is required in many computer games. For example, playing the famous Tetris or Archanoid games needs nothing more than simple discrimination and sensory-motor coordination.This project explores the suitability of CTRNNs to create artificial opponents or allies for human players in computer games.
Senario
The game scenario consists of two enemy tanks moving about and shooting
in a simple maze. Each tank is equipped with a rotating turret holding
a gun. The tank bodies are equipped with six proximity sensors. Those
sensors inform the tank of the distance to solid objects so that
collision with walls or other tanks can be avoided. In addition, the
tank turrets
are equipped with vision sensors that allow the tank to track its
opponent.
Neural Network
Because the CTRNNs have their own internal dynamics, they are able to
display some memory effect. For example, this memory effect enables the
emergence of object persistence in Beer's orientation experiments [Beer
1996]. In our setup some of the obstacles are in motion and therefore a
network with internal dynamics like a CTRNN is more likely to be able
to take that motion into account, at least to a small extent. The
CTRNNs
used for this project were built with two-layers and encoded using
bilateral symmetry.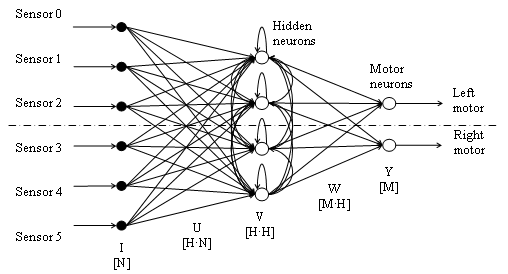
Experiments
A population of genotypes is evolved in an empty arena of 140 x 80
units. After 200 generations, around 15 hours of real time, the
resulting behaviour is obtained. The tanks display fast forward motion,
efficient wall avoidance
and somewhat less efficient tank avoidance. The tanks learned to move
completely straight and to turn in response to sensory activity. 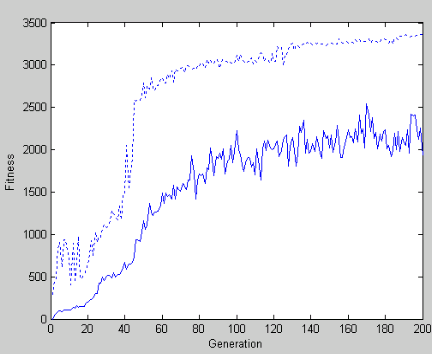
The above picture shows the learning curves of the mean and best individuals of each generation.
The correct aiming behaviour was more difficult to obtain. The task had to be decomposed into several stages of increasing complexity to help the artificial evolution to converge. In the first stage, the tanks were immobile and put in an empty arena, they only had to find each other by rotating the turret. In the second stage the tanks were moving and in the third stage walls were added.
Conclusion
The steering behaviour evolved beyond expectations and was able to
avoid static as well as mobile obstacles. It is however difficult to
say
if this performance was superior to that of a purely reactive system.
To make sure it would be interesting to compare the performance of
evolved feed-forward and CTRNN systems. The aiming behaviour worked
equally fine, but nothing like short-time memory seemed to appear.Downloads Full text & Source code
More info: TankWars.pdf (495 Kb)
Download Videos
DivX-5.0 video: tanks.avi (7 MB)
MPEG-1 video: tanks.mpg (12 MB)
Download Demo
Demo: Click here ! (Win32 .exe file)
Important: when asked, choose [Extract
All] in order to make all files configuration files available to the
executable program.
Instructions
-
+: accelerate simulation
-
-: slow down simulation
-
0-9: Show / Hide track of tank 0-9
-
v: Show / Hide vision sensors rays
-
p: Show / Hide proximity sensor rays
-
F1: Game display mode
-
F2: Neurons display mode
References
R.
D. Beer (1996). Towards the Evolution of Dynamical Neural Networks for
Minimally Cognitive Behavior. In P. Maes, M. Mataric, J. Meyer, J.
Pollack and S. Wilson (Eds.), From animals to animats 4: Proceedings of
the Fourth International Conference on Simulation of Adaptive Behavior
(pp. 421-429). MIT Press.
A. C. Slocum, D. C. Downey, R .D. Beer (2000). Further Experiments in the Evolution of Minimally Cognitive Behavior: From Perceiving Affordances to Selective Attention. In J. Meyer, A. Berthoz, D. Floreano, H. Roitblat and S. Wilson (Eds.), From Animals to Animats 6: Proceedings of the Sixth International Conference on Simulation of Adaptive Behavior. Cambridge, MA: MIT Press.