|
|
 |
 |
 |
 |
 |
- But :
- Distinction entre échantillons indépendants et échantillons appareillés :
Exemple: les groupes d'âge, de sexe ou d'origine sociale différents ou encore la comparaison entre un groupe expérimental et un groupe contrôle.
2) Les échantillons appareillés: On dispose d'un seul groupe d'individus auquel on fait passer deux tâches différentes. On a donc deux groupes de mesures pour chaque individu.
Exemple: pré test, expérience, post test ou bien les effets de traitement
- La méthode du "t" de Student (pour les mesures quantitatives) :
 |
- le résultat de l'échantillon est significatif si la valeur absolue du "t" calculé pour l'échantillon est plus grand ou égal à la valeur du "t" mentionné dans la table (t alpha) en fonction du degré de liberté.
- le résultat de l'échantillon est non significatif si la valeur absolue du "t" calculé pour l'échantillon est plus petit que la valeur du "t" mentionné dans la table (t alpha) en fonction du degré de liberté.
2) Dans un échantillon appareillé: Pour chaque individu, on calcule la différence d des scores obtenus dans les deux tâches passées (entre la les tâches contrôle et expérimentales ou entre le pré test et le post test). Le signe de chaque différence est important. Ensuite, on calcule la moyenne md et la variance des différences, ce qui nous permettra de calculer l'erreur standard de la différence ES(d) essentielle pour trouver la valeur de "t".
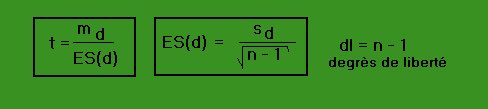 |
-le résultat de l'échantillon est également significatif si la différence des moyennes md est grande.
-le résultat de l'échantillon est également non significatif si la différence des moyennes md est petite
- .L'imprécision :
L'imprécision dépend du nombre de sujets et de la variance des échantillon et nous la connaissons. Il s'agit de l'Erreur standard de la différence ES(d) placée au dénominateur commun de la formule du "t" de Student.
-dans l'application: si on trouve un "t" égal à 5.85, ce résultat indique que la différence observée est 5.8 fois plus grande que l'erreur standard de la différence.
Les conséquences dues aux variations
des paramètres sur le t de Student:
-si la différence des moyennes
augmente, la valeur de "t" augmente
-si l'effectif de l'échantillon
augmente, la valeur de "t" augmente
-si la variance diminue, la valeur de
"t" augmente
- Distinction entre test d'hypothèse bilatéral et test d'hypothèse unilatéral (pour Rho de Spearman, t de Student et r de Bravais-Pearson):
Le test bilatéral sert à comparer la moyenne de deux échantillons dont la différence d peut aller dans les deux sens, c'est-à-dire qu'il prend compte des deux possibilités suivantes: il est soit de signe négatif, soit de signe positif.
Exemple pour la formulation des hypothèses Ho et H1: lors d'un test où on comparerait la moyenne théorique des hommes avec celle des femmes (ou deux groupes d'âges différents) pour une tâche définie, on formulerait les hypothèses suivantes:
-l'hypothèse nulle Ho postulerait que les deux moyennes sont identiques, donc la moyenne des différences md pour la population est égale à zéro (m hommes-m femmes=0).
-l'hypothèse alternative H1 postulerait deux alternatives à choix. La valeur de la moyenne des différences md pour la population peut être positive ou négative mais elle n'est pas égale à zéro (m hommes-m femmes=+x ou -x) (x = ]-infini;0[+]0;+infini[).
Application: dans un test donné, on considère la probabilité liée au t alpha égal à .05 (5% de risque d'erreur acceptable). On répartit donc ces 5% aux deux extrémités de la distribution (2.5% à gauche(-) et 2.5% à droite(+)). Pour trouver la valeur de t alpha en valeur absolue dans la table du "t" de Student on considère la probabilité (1-.05) et le degré de liberté. Cette valeur de t alpha représente les deux limites positive" +t alpha" et négative "-t alpha" à partir desquelles la valeur de t de l'échantillon est considéré comme SIGNIFICATIF.
 |
2) Test d'hypothèse unilatéral (ou test à une queue)
Le test unilatéral sert à comparer la moyenne de deux échantillons où la différence d ne peut aller que dans un sens, c'est-à-dire qu'il prend compte d'une seule possibilité: le résultat ne peut être que positif.
Exemple pour la formulation des hypothèses Ho et H1: lors d'un test où on comparerait la moyenne théorique d'un groupe d'experts avec celle d'un groupe de novices pour une tâche définie, on formulerait les hypothèses suivantes:
-l'hypothèse nulle Ho postulerait que les deux moyennes sont identiques, donc la moyenne des différences md pour la population est égale à zéro (m experts-m novices=0)
-l'hypothèse alternative H1 postulerait une seule solution. La valeur de la moyenne des différences md pour la population ne peut être que positive mais elle n'est pas égale à zéro (m experts-m novices=+x ) (x =]0;+infini[).
Application: pour déterminer le t alpha, le principe est analogue mais pas identique à celui du test bilatéral. La différence se situe au niveau du risque d'erreur indiqué pour trouver la valeur de t dans la table. Lorsqu'on détermine un risque d'erreur alpha égal à .05, on utilise alors la valeur "2 alpha" (on multiplie alpha par deux), c'est-à-dire .10 pour consulter la table. La valeur qui correspond à ce risque d'erreur est nommée "t 2 alpha". Si alpha vaut .02, on consulte la table en considérant la valeur de t à alpha .04 à un degré de liberté préalablement défini.
 |
- Comparaison d'une distribution observée à une norme (pour les valeurs quantitatives):
Méthode: On utilise le t de Student dans une version différente de celle présentée ci-dessus, mais le reste de la procédure reste la même. Les formules sont les suivantes:
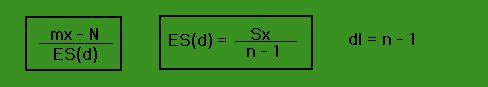 |
-l'hypothèse nulle Ho implique que la moyenne théorique de la population serait égale à la NORME.
-l'hypothèse alternative H1 implique que la moyenne théorique de la population ne serait pas égale à la NORME. Si on soustrait la NORME de la moyenne théorique de la population (Moy.th. -N), le résultat serait positif ou négatif mais pas égal à zéro.
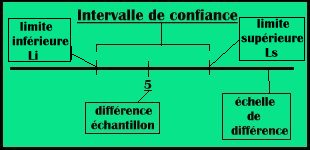
- L'intervalle de confiance pour les échelles de différence :
 |
 |
- L'analyse de la variance :
Le FACTEUR: (à
ne pas confondre avec l'analyse factorielle) est la variable qui préside
à la constitution des groupes qu'on va comparer. Il s'agit de la
variable indépendante. Le FACTEUR peut être un chiffre, l'âge,
ou l'origine sociale par exemple. Il sert à poser une distinction
entre chaque groupe.
La VARIABLE: est le score
de chaque individu. Il s'agit de la variable dépendante. La VARIABLE
peut être un score quelconque, un temps de réaction par exemple.
Il y a donc toujours au moins un FACTEUR et
une VARIABLE dans une analyse de variance.
Méthode: il s'agit de la même méthode que celle du t de Student mais au lieu de calculer t, on calcule l'indice F de Fischer-Snedecor:
 |
-CM(inter), également appelé CM(effet), mesure la différence entrer les groupes, et il varie en fonction de l'effet considéré.
-CM(intra) mesure la différence entre les individus dans les groupes, mais il ne varie pas.
(pour les échantillons appareillés, la variabilité est moindre, car les sujets sont identiques, la variabilité intragroupe (CM(intra)) est donc plus réduite)
La variabilité totale: elle s'obtient
en additionnant la variabilité inter avec la variabilité
intra:V(tot.)=V(inter)+V(intra)=CM(inter)+CM(intra).
La méthode de calcul: on dispose
d'une distribution d'échantillonnage de F, DE(F), et de la loi de
Fischer.
-F est SIGNIFICATIF s'il est nettement
supérieur à 1 et si le risque d'erreur est faible. On peut
alors affirmer que le FACTEUR a un effet systématique sur la VARIABLE.
-F est NON SIGNIFICATIF s'il est égal
à 1 (valeur théorique) on peut alors affirmer que tous les
groupes ont la même moyenne et si le risque d'erreur est élevé,
on renonce à tirer des conclusions.
La signification des résultats dépend
du nombre de groupes en présence et du nombre d'individus dans chaque
groupe.
Si on a plus de deux groupes à analyser,
on définit la moyenne générale de tous les individus,
ensuite la variabilité de toutes ces moyennes autour de la moyenne
générale.
- Analyse de la variance avec un seul FACTEUR (1 V.I.) et une VARIABLE (1 V.D.) :
(ce procédé s'applique à la fois au échantillons appareillés et aux échantillons indépendants)
En considérant deux groupes, contrôle et expérimental, on veut mesurer une VARIABLE (le temps de réaction). On calcule la moyenne de chaque groupe et on veut savoir si la différence entre ces deux moyennes est significative. Pour ce faire, on calcule d'abord le "t" de Student et ensuite le F de Fischer-Snedecor. On remarque que le résultat obtenu pour F est égal au carré du résultat du t de Student, les deux ayant été obtenus avec un même risque d'erreur.
Si dans une même situation on a trois groupes, un groupe contrôle et deux groupes expérimentaux différents, on est obligé d'utiliser l'analyse de la variance pour comparer ces trois derniers. L'hypothèse nulle Ho impliquerait donc que les trois moyennes seraient égales.
Dans ce cas, l'analyse de la variance est un test global, il ne nous indique pas quel groupe diffère de quel autre groupe. Pour entrer dans ces précisions, on procède à la méthode suivante:
# La méthode des comparaisons partielles panifiées:
Cette méthode s'appuie sur l'utilisation du t de Student et elle comporte deux sorte de comparaisons:
1) La comparaison a priori: il s'agit de décider du nombre de comparaisons qu'on va effectuer avant de faire l'analyse globale des comparaisons.
2) La comparaison a posteriori: cette décision se fait après coup.
conclusion: on utilise le t de Student lorsqu'on compare deux groupes et on utilise le F de Fischer-Snedecor lorsqu'on compare plus de deux groupes. Le F est avantageux pour la recherche scientifique, car lorsqu'on constitue deux groupes qu'on souhaite équivalents à tous les points de vue, sauf à celui qu'on veut comparer (ex: le sexe on compare les hommes avec les femmes), on contrôle donc les variables parasites.
- Analyse de la variance avec deux FACTEURS (2 V.I.: FACTEUR 1 et FACTEUR 2)) et une VARIABLE (1 V.D.) :
But: on n'étudie pas chaque FACTEUR séparément, mais on considère les deux FACTEURS et leur action combinée sur la VARIABLE.
La procédure: en premier lieu,
il faut se demander quelles sont les questions auxquelles l'analyse permettra
de répondre. Il est possible de tester d'une part les effets
principaux, et, d'autre part les effets d'interaction.
-les effets principaux: on teste l'effet
de chaque FACTEUR (seul) sur la VARIABLE. Il y a donc autant d'effets principaux
qu'il y a de FACTEURS (ici, on en a deux).
-les effets d'interaction: on test
l'effet dû à l'action combinée, conjointe des deux
FACTEURS sur la VARIABLE. Il y a donc un seul effet d'interaction.
En considérant toutes les combinaisons
possibles entre les modalités des deux FACTEURS, on utilise un tableau
croisé des moyennes de chaque groupe. On fait d'abord la moyenne
pour chaque groupe, ensuite les moyennes marginales du tableau qui correspondent
aux moyennes de chaque modalité et on termine avec la moyenne générale
qui correspond à la moyenne des moyennes marginales. Après
avoir calculé ces trois dernières, on veut répondre
aux trois questions suivantes (2 effets principaux et 1 effet d'interaction):
-1) Voir si les modalités du
FACTEUR 1 ont un effet sur la VARIABLE. Pour ce faire, on fait une comparaison
de leur moyennes marginales.
-2) Voir si les modalités du
FACTEUR 2 ont un effet sur la VARIABLE. Pour ce faire, on fait une comparaison
de leur moyennes marginales.
-3) On considère les moyennes
de chaque groupe et on vérifie si l'écart des scores de la
VARIABLE pour chaque modalité du FACTEUR 1
diffèrent d'un modalité à l'autre pour celles du FACTEUR
2.
Afin de répondre à cette dernière question, on construit un graphique dont l'axe vertical représente les valeurs de la VARIABLE et l'axe horizontal représente les FACTEURS 1 et 2. On trace d'abord la courbe du FACTEUR 1, dont chaque point relié correspond à chacune de ses modalités et on fait de même pour le FACTEUR 2. Ensuite, on constate l'évolution de chaque performance (VARIABLE). Ceci nous permet de répondre à la question concernant l'effet d'interaction. Si les deux tracés sont parallèles, le FACTEUR 1 ne dépend pas du FACTEUR 2. Finalement, on teste les trois résultats obtenus afin de voir s'ils sont SIGNIFICATIF ou non. Il y a donc interaction lorsqu'on s'écarte de la situation de parallélisme, le croisement des deux courbes n'étant pas obligatoire.
Les degrés de liberté:
ils diffèrent en fonction de l'effet considéré:
-a) pour les effets principaux, le
degré de liberté est égal à [dlc=Nc-1],
Nc étant le nombre de modalités du FACTEUR c.
-b) pour les effets d'interaction,
le degré de liberté est égal à [dlca=dlc
x dla], c et a étant les deux FACTEURS mis
en interaction.
-c) pour les carrés moyens intra,
le degré de liberté est égal à [N-1-dlc-dla-dlca],
N étant le nombre total de sujets.
Chaque type de carré moyen CM, (inter) et (intra), possède son degré de liberté. Parfois, on on donne F en n'indiquant que le degré de liberté effet (inter) et le degré de liberté intra : exemple: F(2,24)=11.25, 2 étant le dl effet et 24 le dl intra.
Interprétation des résultats: lorsque les effets principaux et l'effet d'interaction sont significatifs, on interprète d'abord l'effet d'interaction et ensuite les effets principaux afin d'éviter les conclusions incorrectes et les contradictions. Si les trois effets sont significatifs, le FACTEUR 1 a un effet systématique sur le FACTEUR 2 généralisable pour la population.
- Complément théorique :
La variabilité mesurée par la
variance est celle du phénomène qui nous intéresse.
Le but est de déterminer les FACTEURS responsables de cette variabilité,
et dans quelle mesure différents FACTEURS permettent d'expliquer
cette variabilité observée dans les résultats:
-1) l'analyse de la variance permet
de quantifier la variance due au FACTEUR considéré.
-2) l'analyse de la variance quantifie
la part de variance due à l'effet d'un FACTEUR sur un autre (effets
principaux).
-3) l'analyse de la variance quantifie
l'effet conjoint des deux FACTEURS sur les sujets (effet d'interaction).
-4) une fois plusieurs FACTEURS considérés,
il reste toujours une part de variance inexpliquée due au fait que
les individus sont tous différents les uns des autres, même
dans un groupe irréductible à l'appartenance à un
groupe. Il s'agit de la Variance intra-groupe.
1), 2) et 3) sont les sources de variation systématique, car ils sont associés aux FACTEURS contrôlés dans le cadre de l'expérience. Quant à 4),la variance intra-groupe, il s'agit d'une variance aléatoire, d'erreur, car elle est due à la fluctuation aléatoire de l'échantillonnage d'un groupe. Cette méthode permet ainsi de décomposer en différents facteurs qui expliquent cette variabilité.
Si on fait une analyse de la variance avec un seul FACTEUR, le résultat risque d'être NON SIGNIFICATIF, car le carré moyen intragroupe, l'erreur, risque d'être très grand. Et s'il y a trop de FACTEURS , on a une meilleure maîtrise mais trop de mal a interpréter les résultats. La meilleure des procédure consisterait à ne considérer que trois FACTEURS. On peut ainsi procéder à l'analyse de trois effets principaux, des effets de premier ordre, et à un effet d'interaction, l'effet de deuxième ordre.
L'hypothèse nulle:
Si on a un seul FACTEUR possédant plusieurs
modalités, l'hypothèse nulle implique donc que les moyennes
des modalités de ce FACTEUR seraient égales l'une à
l'autre, il n'y aurait aucune différence pour la population.
Si on a deux FACTEURS distincts, dont chacun
possède plusieurs modalités, on considère alors
trois hypothèses nulles Ho, une pour chaque effet (2 principaux
et 1 interaction):
-pour la population, les modalités
relatives au FACTEUR 1 auraient des moyennes marginales qui seraient égales.
(hypothèse nulle testant le
premier effet principal)
-pour la population, les modalités
relatives au FACTEUR 2 auraient des moyennes marginales qui seraient égales.
(hypothèse nulle testant le
deuxième effet principal)
-pour la population, la différence
des moyennes observée dans une des colonnes du tableau serait la
même pour les autres colonnes. (hypothèse
nulle testant l'effet d'interaction)
|
|
|
|
|