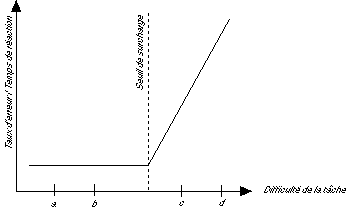
Figure 2.7: En situation de surcharge cognitive, toute augmentation de la difficulté de la tâche conduit à une détérioration des performances. (Adapté de Eggemeier, 1988)
Au sein des travaux relatifs à la mesure de la charge mentale, deux éléments sont pertinents pour les concepteurs de logiciels interactifs. Le premier élément concerne la relation entre les différentes mesures, plus précisément le fait que les mesures subjectives (auto-évaluation) sont fortement corrélées avec les mesures objectives (performances) (Miller and Hart, 1984, cités part Meshkati & Lowenthal, 1988; Reid & Nygren, 1988). Si les sujets sont capables d'auto-estimer de façon relativement fiable leur charge mentale, il ne serait pas inutile d'intégrer cette information dans nos systèmes. L'auteur peut par exemple donner à l'utilisateur la possibilité de modifier directement le système en réglant certains paramètres, par exemple la vitesse de présentation des informations ou le nombre d'informations présentées simultanément.
Nous reviendrons sur ces diverses formes d'adaptation dans le module 8. Wierwille (1988) indique cependant que les sujets de ses expériences expriment souvent le besoin de baser leur jugement sur un compte-rendu de leurs performances. En d'autres termes, le concepteur doit garder à l'esprit que la qualité de l'auto-évaluation sera fortement influencée par la précision des feed-back concernant les performances de l'utilisateur.
Le second point intéressant dans ces études réside dans le fait que, pour amener le sujet à franchir le seuil de surcharge cognitive, les expérimentateurs demandent généralement au sujet de réaliser une deuxième tâche, simultanément à la première. Par exemple, ils leur demande de compter à rebours tout en dessinant des formes géométriques sur l'écran. Or, l'utilisateur d'un logiciel informatique, réalise en général aux moins deux activités simultanées: la tâche elle-même et l'utilisation du logiciel. Par exemple, l'utilisateur d'un traitement de texte doit à la fois penser à la rédaction du texte (comme il le ferait s'il écrivait sur papier) et gérer les outils offerts par le logiciel. Certes, l'objectif d'un concepteur de logiciels est de rendre son logiciel 'transparent', c'est-à-dire de permettre à l'utilisateur de concentrer sur la tâche, sans se soucier du logiciel. Cet idéal est cependant rarement atteint, l'utilisateur ayant à traduire ses intentions en termes de commandes offertes par le logiciel.
Certains auteurs proposent l'idée que nous disposons de multiples processeurs, relativement indépendants les uns des autres, et qui possèdent chacun des capacités limitées (Wickens, 1987; Eggemeier, 1988). Il serait donc possible d'être en surcharge pour un aspect de la tâche et de disposer de ressources cognitives pour un autre aspect. Selon cette théorie, l'utilisateur pourrait traiter simultanément des stimuli visuels et sonores, ou produire des comportements sonores et moteurs (chanter en frappant un rythme), car ceux-ci font appel à des registres différents. Par contre, il serait moins efficace de coordonner deux comportements moteurs (frapper des rythmes différents avec chaque main). Pour Eggemeier (1988), les sujets seraient capables de traiter en parallèle des stimuli visuels et auditifs (input), des informations spatiales et symboliques (raisonnement) et des actes manuels et vocaux (output). Si l'évolution actuelle des sciences cognitives confirme l'existence de processus multiples, il n'est pas clair qu'elle aboutisse à l'identification des mêmes composantes. Le débat concerne notamment la définition des catégories de stimuli prises en charge par un même processeur ou un même sous-système cognitif. Par exemple, tous les stimuli visuels ne sont pas traités de la même manière. La répartition des ressources serait moins liée à la nature des inputs qu'au type de traitement de ces stimuli. Il ne nous est pas possible d'entamer ici un débat sur l'architecture cognitive de l'homme. Le concepteur retiendra le principe selon lequel deux tâches qui mettent en oeuvre une même fonction cognitive rentrent en concurrence pour l'allocation des ressources propres à cette fonction.
Ce principe général doit cependant - une fois de plus - être nuancé. En effet, si deux sous-tâches partagent certaines caractéristiques fonctionnelles, l'utilisateur peut économiser la partie redondante du traitement (Wickens, 1987). Par exemple, si deux graphes juxtaposés utilisent la même légende, l'utilisateur ne doit interpréter qu'une courbe et peut comprendre la seconde directement par rapport à la première. En outre, l'exécution de tâches parallèles semble meilleure si les deux éléments à traiter sont intégrés au sein d'un objet d'ordre supérieur, en particulier si la tâche implique une comparaison entre les composantes (Wickens, 1987).
Une autre façon de réduire la charge mentale imposée par une tâche multiple consiste à automatiser certaines sous-tâches. Lorsqu'une tâche est bien automatisée, elle requiert des ressources limitées. On peut alors ajouter une autre tâche sans grande détérioration des performances (Fisk, Ackerman & Schneider, 1987). Nous sommes par exemple capables de conduire, de sortir notre carte de parking tout en continuant la conversation avec le passager. L'exercice répété d'une même tâche permet son automatisation. Nous avons précédemment utilisé l'exemple de l'utilisateur du traitement de texte qui réalise en parallèle deux tâches, exprimer ses idées et utiliser le logiciel. Il est probable que lorsque cet utilisateur aura totalement automatisé l'utilisation du système, celle-ci ne représentera plus qu'une charge minimale. Le système deviendra 'transparent'. L'utilisateur pourra consacrer toutes ses ressources à la rédaction.
Certes, la pratique intensive d'une démarche ne donne pas toujours lieu à une automatisation. L'automatisation repose sur l'induction d'invariants entre les situations rencontrées à travers un même programme. Elle dépend donc du degré de cohérence entre les situations. Si les conventions changent au cours de l'interaction, l'utilisateur ne peut induire d'invariants puisque ceux-ci n'existent pas. Nous verrons dans le module 6 que la cohérence est la qualité primordiale d'un langage d'interaction. Toutefois, l'inverse de ce principe possède également une certaine vérité: il arrive que l'exercice répété d'une compétence conduise à décroître les performances, effet dû à la lassitude (Fisk, Ackerman & Schneider, 1987). Signalons enfin que la question de l'automatisation prend une dimension particulière dans l'interaction personne-machine: si l'utilisateur peut automatiser une activité, pourquoi le système ne pourrait-il prendre cette activité en charge? Cette question doit être considérée sérieusement au moment de partager les tâches entre le système et l'utilisateur.