0. Introduction
Ce cours concerne l'étude de l'interaction entre une personne et un
système informatique. La littérature anglo-saxonne désigne
cette discipline sous le nom de 'human-computer interaction'. L'objet
d'étude ne se limite pas à l'interface (ou aux écrans). Il
couvre l'interactivité dans son ensemble, y compris le traitement des
messages par le système. Le but social de ces études consiste
à rendre les logiciels plus conviviaux, plus efficaces et d'en faciliter
l'apprentissage. Leur but scientifique est de déterminer quels aspects
du système cognitif humain expliquent les variations de performance d'un
logiciel à l'autre et d'un individu à l'autre.
J'ai tenté de couvrir un large spectre de logiciels interactifs:
didacticiels, jeux, traitements de texte, bases de données, ... Le cours
concerne également les logiciels utilisés dans les bornes
interactives, des distributeurs de billets ou encore les photocopieuses.
Néanmoins, j'ai privilégié les logiciels les plus
pertinent par rapport au cursus des étudiants en psychologie ou en
sciences de l'éducation: didacticiels, tests, expériences
interactives,...
La conception de systèmes interactifs n'est pas un processus
déductif qui, à partir de lois générales, permette
de construire le système idéal. Il s'agit d'un processus
créatif au cours duquel le concepteur recherche une solution optimale
à un ensemble de contraintes partiellement contradictoires. Une partie
de ces contraintes sont déterminées par les choix technologiques
(hardware et software). D'autres contraintes sont liées aux
caractéristiques du système cognitif humain. Enfin, la nature de
la tâche définit certaines contraintes, de même que
l'environnement physique et humain dans lequel le logiciel est utilisé.
L'étude de l'interaction personne-machine constitue donc un domaine
multi-disciplinaire qui recouvre des dimensions psychologiques, des aspects
informatiques et, dans certains cas, des aspects pédagogiques. Ce cours
ne fournit pas de recettes pour le design de logiciels interactifs. Il propose
des concepts et des principes au moyen desquels le concepteur peut construire
des solutions.
Ce cours propose également l'apprentissage du langage-auteur Authorware.
Celui-ci permet de construire un logiciel interactif même si on ne
dispose pas de compétences avancées en informatique. Il s'agit
d'un des outils les plus performants actuellement sur le marché. Il
offre en outre l'avantage d'être disponible sur les plates-formes
Macintosh et Windows. D'autres outils performants existent et de nouveaux
outils de plus en plus performants apparaissent régulièrement. Le
but n'est pas d'enseigner Authorware per se, mais de mettre en rapport les
concepts théoriques étudiés et une démarche
concrète de réalisation de logiciel interactif. Ce cours ne se
substitue pas au mode d'emploi d'Authorware. Il traite plus de l'exploitation
de ce langage que de son apprentissage.
Le cours est provisoirement structuré en 10 modules. Chaque module
comporte trois parties. La première partie permet d'expérimenter
sur soi certains aspects de l'interaction personne-machine, le plus souvent en
comparant plusieurs variantes d'un même programme. La seconde partie
passe en revue les modèles théoriques et/ou les connaissances
techniques en rapport avec le thème du module. La troisième
partie considère la réalisation au moyen d'Authorware de
procédés interactifs décrits dans la partie
précédente. Lorsque c'est pertinent, elle est accompagnée
de quelques exercices sur l'utilisation d'Authorware. Les exemples
utilisés dans chaque module et les programmes correspondant aux
exercices sont disponibles sur le serveur de la faculté.
Il s'agit de notes provisoires. Elles contiennent certainement des lacunes,
des erreurs de fond et des erreurs de forme. Tout commentaire ou toute remarque
sont les bienvenus (voir adresse ci-dessous). Prière de ne pas
diffuser de document sans l'autorisation de l'auteur. Merci à
François Lombard pour ses commentaires.
P. Dillenbourg, FPSE, Université de Genève, 9 Route de Drize,
1227 Carouge.
Courrier électronique: pdillen@divsun.unige.ch
1. Espace de Conception
L'espace de conception des systèmes interactifs est l'ensemble des
systèmes qui pourraient être théoriquement construits. Cet
espace est défini par les technologies disponibles pour construire un
logiciel interactif et limité par l'imagination des concepteurs.
L'objectif de ce module est de fournir une connaissance générale
de ces technologies. Sur le plan matériel, le concepteur doit pouvoir
estimer les contraintes liées au choix d'une configuration informatique
(type d'écran, type de souris, espace disque, temps de
réponse,...). Sur le plan logiciel, il doit être à
même de penser une interaction en terme d'objets de haut niveau: curseur,
icône, fenêtre, scrolling bar,...
1.1 Exploration
L'activité proposée dans ce premier module consiste à se
familiariser avec les objets logiciels qui composent l'alphabet du concepteur
de logiciels interactifs. Il s'agit donc de choisir un logiciel inconnu ou des
fonctionnalités inexplorées d'un logiciel familier et de noter
les difficultés rencontrées. Cette activité permettra de
prendre conscience les difficultés que peut rencontrer un sujet qui
découvre un nouveau logiciel. Nous suggérons par exemple
d'utiliser un logiciel de dessin et, soit de tenter de reproduire les formes
qui se trouvent dans le fichier module-1/dessins, soit de tenter de
répondre aux questions suivantes:
- comment faire tourner un rectangle d'un angle de 17 degrés?
- comment dessiner un pentagone régulier et un irrégulier ?
- comment assembler les pentagones et le rectangle oblique en un seul objet
et l'allonger ?
- comment aligner verticalement 3 cercles?
- comment dessiner une demi-lune?
- comment écrire son nom manuellement (sans entrer les
caractères au clavier) ?
L'utilisation d'un programme de dessin
permet notamment de comprendre les avantages et inconvénients des
différents modes de représentation des objets graphiques.
Imaginons que l'utilisateur crée une ellipse (voir figure 1.1). A
l'écran apparaissent un certain nombre de points noirs et blanc. En mode
bitmap ou pixel, le système représente l'état de
l'écran par un ensemble de points noirs et blancs. La machine n'a pas de
représentation de l'objet cercle. Dans ce mode, l'interaction ressemble
au dessin naturel: lorsqu'un point est déposé, il peut-être
manipulé en tant que point, mais non en tant qu'élément
d'un objet. En mode vectoriel, le cercle est représenté de
manière interne en tant qu'objet doté de
propriétés: position, rayon, épaisseur, pattern,
couleur,... Du point de vue du système, le mode vectoriel est plus
économique, car plus synthétique. Du point de vue de
l'utilisateur, le principal avantage du mode vectoriel est que les objets
peuvent être modifiés, assemblés, déplacés,
etc. Un autre avantage apparaît à l'impression. Si le dessin est
en mode bitmap, l'imprimante reproduira sur le papier un ensemble de points
semblable à celui affiché sur l'écran, y compris tous les
défauts liés à la taille du pixel (voir figure 1.1). Si le
dessin est réalisé en mode vectoriel, il pourra être
traduit en commandes et bénéficier pleinement de la
résolution de l'imprimante (généralement supérieure
à celle de l'écran).

Figure 2.1 Impression d'une ellipse créée en mode bitmap
(à gauche) et vectoriel (à droite)
En mode vectoriel, l'utilisateur doit créer son dessin à partir
d'un ensemble limité d'objets de base. Cet ensemble d'objets peut certes
être enrichi par la mise à disposition de librairies d'objets,
mais il n'offre pas la liberté du traitement pixel par pixel (mode
bitmap). Certains logiciels travaillent uniquement dans un des deux modes,
d'autres offrent les deux modes ainsi que des outils permettant de
transférer un graphique d'un mode vers l'autre. Le plus
célèbre de ces outils est la 'baguette magique' utilisée
dans les logiciels d'édition d'image pour identifier en tant qu'objet
une zone de pixels de couleur homogène (le degré
d'homogénéité étant précisé par
l'utilisateur).
1.2 Les composantes matérielles
La figure 1.2. présente un modèle simple d'interaction entre deux
agents: le terme interaction indique, d'une part, que les signaux émis
par un agent sont perçus par l'autre agent, et d'autre part, que les
signaux émis par un agent sont (partiellement) déterminés
par ceux qu'il a perçus.
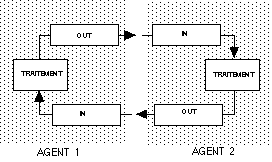
Figure 2.2 Modèle simple d'interaction entre deux agents
Nous nous intéressons à une classe particulière
d'interactions dans lesquelles l'un des agents est un utilisateur humain et
l'autre est un système automatique (ordinateur, cafetière,
réveil, ...). La figure 1.3 détaille le modèle
général dans le cas particulier de l'interaction entre un
utilisateur humain et un ordinateur.
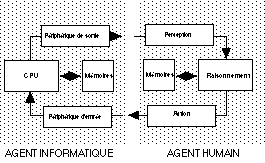
Figure 2.3 : Modèle simple d'interaction personne-machine
La figure 1.4 fait un 'zoom' sur l'agent informatqiue et ses différents
composantes. On distingue généralement l'unité centrale et
les périphériques. La première comprend le
microprocesseur, les mémoires, les bus (câbles qui conduisent
l'information à l'intérieur du système) et diverses cartes
(extensions mémoires, pré-traitement de certaines informations,
...). Les périphériques d'entrée transmettent à
l'unité centrale les informations stockées sur support
magnétique ou optique, ainsi que les informations provenant de
l'utilisateur (clavier, souris, ...). Les périphériques de sortie
écrivent ces informations sur support magnétique ou les
transmettent à l'utilisateur (écran, imprimante). Les autres
machines qui nous intéressent (cafetière, caisse de parking, ...)
comprennent au moins une partie de ces composantes, même si celles ci
sont très spécialisées (la fonction de programmation d'un
magnétoscope n'a pas besoin de 5 mégaoctets de mémoire
vive, la photocopieuse dispose d'un écran 'minimaliste', ...).
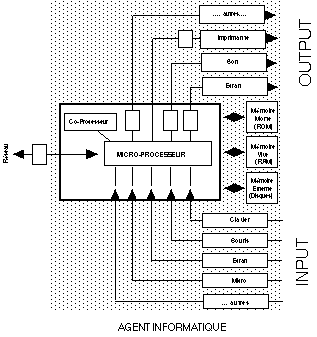
Figure 2.4 : Modèle simplifié d'un ordinateur
Ce module étudie les composantes de l'agent informatique dans la mesure
où elles influencent l'interaction avec l'utilisateur. Il ne s'agit donc
pas de décrire la technologie per se, mais de faire apparaître
l'influence d'un choix technique sur les modalités d'interaction.
1.2.1 Perception des actions de l'utilisateur (input)
On utilise généralement le terme de périphérique
d'entrée pour désigner à la fois les composantes qui
permettent à l'utilisateur de communiquer avec la machine et les
dispositifs de stockage de l'information (supports magnétiques ou
optiques). Ces derniers influencent l'interaction dans la mesure où
l'accroissement rapide des capacités de stockage permet
d'intégrer des objets qui occupent beaucoup de place en mémoire,
en particulier le son et les images. Nous nous intéressons ici aux
périphériques de communication personne-machine. Ceux-ci ont subi
en quelques décennies une évolution vertigineuse, depuis les
cartes perforées jusqu'aux 'dataglove' utilisés dans les
systèmes de 'réalité virtuelle'.
1.2.1.1 Systèmes permettant d'entrer un texte
1.2.1.1.1 Le clavier
Bien que l'avenir proche accordera certainement un rôle central aux
systèmes à commande vocale, le clavier reste actuellement
le principal canal de communication entre l'utilisateur et le système.
Lorsqu'une touche est pressée, le clavier transmet un signal au
système, généralement un nombre (code ASCII) correspondant
au caractère pressé. Le nombre de signaux qui peuvent être
émis est supérieur au nombre de touches du clavier car plusieurs
touches peuvent être enfoncées simultanément, par exemple
la touche 'majuscule' et une touche caractère. Un clavier comporte cinq
types de touches:
- Les touches 'caractère' correspondent au clavier d'une machine
à écrire. Le clavier en comporte généralement moins
de cinquante, ce qui couvre une utilisation standard, dans une langue
donnée. Les caractères inhabituels dans une langue (par exemple
le ü ou le ç dans un clavier américain) et autres symboles
rares (par exemple, certains signes mathématiques), sont
généralement disponibles en pressant simultanément une
touche 'caractère' et une touche 'spéciale'.
- Les touches 'spéciales' telles 'majuscule' (ou 'shift'), 'option' ,
'contrôle', 'pomme' ou 'meta' (selon les claviers) modifient le signal
associé à une touche particulière, soit afin de lui
associer un autre caractère, soit afin de communiquer une commande.
L'adjonction de telles touches permet de réduire le nombre de touches
dans un clavier. En réduisant le nombre de touches (jusqu'à une
certaine limite), on réduit la distance que doivent parcourir les
doigts. Par contre, on augmente les exigences quant à la coordination
des mouvements de doigts et la difficulté d'apprentissage du clavier.
Ainsi, Hammond et Barnard (1984) ont testé un langage de commandes
comprenant de nombreux caractères qui nécessitent l'utilisation
de la touche 'shift'. Ils rapportent que dans la moitié des erreurs le
sujet avait pressé la bonne touche du clavier, mais avait omis de
presser 'shift' ou, inversement, qu'il l'avait pressé alors qu'ils
n'aurait pas dû.
- Les touches 'fonction' transmettent au logiciel des commandes telles que
'imprimer', 'justifier', 'faire passer l'objet en arrière plan'. Sur
certaines touches figure le nom de la commande (par exemple 'print screen'). Un
ensemble de touches, généralement séparées du
clavier principal, portent un nom neutre (F1,F2,...). Leur effet varie de
programme en programme. Certains systèmes permettent à
l'utilisateur d'associer une nouvelle fonction ou séquence de fonctions
(macro) à une touche. Un cache en papier peut être placé
près de ces touches afin d'en indiquer les effets. Ces touches
étant en nombre limité, elles sont généralement
réservées aux fonctions le plus fréquemment
utilisées. Dans de nombreuses applications, d'autres commandes peuvent
être transmises en combinant d'une touche 'spéciale' avec une
touche 'caractère' (par exemple sur Mac, option + C signifie "coller").
Lorsque cette combinaison active une commande par ailleurs disponible dans un
menu, elle porte le nom de 'raccourci-clavier'.
- Le pavé numérique comprend les touches d'une calculette: les
chiffres, la virgule ou le point, et les opérations arithmétiques
fondamentales. Il s'avère plus efficace que les touches du clavier
normal lorsque l'utilisateur doit introduire une longue série de
nombres. On peut ajouter un pavé numérique indépendant du
clavier principal.
- Les touches 'curseur' qui permettent le déplacement du curseur.
Nous en parlons dans la section suivante.
- Afin de faciliter la frappe, certains ergonomes ont imaginé des
claviers arrondis ou des supports permettant de poser la base de la paume de la
main. L'inclinaison de certains claviers est réglable par l'utilisateur.
Les études empiriques n'ont cependant pas pu mettre en évidence
que l'inclinaison (Emmons & Hirsch, 1982) ou la hauteur du clavier (Suther
& McTyre, 1982) aient un effet significatif sur l'entrée de texte.
Tout ce qu'on a pu montrer est que les préférences des
utilisateurs varient, notamment selon leur taille et la longueur de leur main
(Potosnak, 1988). Pour permettre ces variations, l'angle du clavier doit
pouvoir varier de 15% (ibidem.).
Lorsque les touches n'offrent pas un
feed-back tactile (touches à effleurement), il est utile de
prévoir un feed-back sonore ou visuel. Les téléphones
actuels combinent même souvent le feed-back tactile, auditif et visuel.
Le son de la touche peut être soit mécanique (comme dans un
clavier normal), soit généré par le système. Dans
ce cas, il est intéressant que l'utilisateur puisse régler le
volume du feed-back sonore, en particulier si d'autres personnes travaillent
autour de lui. L'efficacité de ce feed-back sonore est réduite si
le délai entre la pression du touche et la perception de feed-back
(sonore ou visuel) est trop longue, et elle est moindre pour les utilisateurs
disposant de bonnes compétences dactylographiques (Potosnak, 1988). Dans
l'exemple du téléphone, la présence du feed-back sonore
immédiat modifie le rôle du feed-back visuel, lequel devient
surtout utile pour vérifier le numéro a posteriori.
Une différence importante entre les claviers réside dans la
disposition des lettres. Ces différentes dispositions, décrites
par les 6 premières touches du clavier (en haut à gauche) ont
donné lieu à beaucoup de controverses. La disposition actuelle du
clavier QWERTY (ou QWERTZ en Suisse) ne se justifie pas par des facteurs
ergonomiques. Le choix de cette disposition remonte à 1878, au temps des
premières machines à écrire mécaniques: les lettres
fréquemment juxtaposées dans un texte avaient alors
été éloignées sur le clavier afin d'éviter
que les bras portant les caractères ne se coincent mutuellement.
D'autres distributions des lettres ont été
étudiées. La disposition des lettres en ordre alphabétique
semble ne pas donner de résultats supérieurs au clavier QWERTY
(Potosnak, 1988). La disposition Dvorak (du nom de son auteur) place au centre
de chaque main les lettres les plus fréquentes de telle sorte qu'il y
ait alternance des mains. Les études comparant ce clavier et le clavier
QWERTY indiquent un gain de vitesse qui varie de 2,3 à ... 50%!
(Potosnak, 1988). Néanmoins, le fait que des millions de personnes
connaissent le clavier QWERTY constitue une force d'inertie plus puissante que
les facteurs purement ergonomiques. Cette anecdote est intéressante car
elle montre que les problèmes ergonomiques peuvent sortir du cadre
technologique et psychologique qui est le nôtre et se heurter à
des obstacles de nature sociologique. En ce qui concerne la disposition des
touches du pavé numérique, il semble que la disposition de type
'téléphone' (la ligne '1 2 3' en haut) soit
légèrement supérieure à la disposition de type
'calculette' (la ligne '7 8 9' en haut) (Potosnak, 1988), probablement parce
que la plupart des sujets sont plus familiers avec un téléphone
qu'avec une calculette.
1.2.1.1.2 La tablette graphique
Le clavier ne constitue pas la seule manière d'entrer du texte. Une
autre manière consiste à transmettre une texte écrit via
une tablette ou un texte écrit ou dactylographié via un
scanner. La reconnaissance de l'écriture manuelle n'est pas encore une
technologie à toute épreuve, mais elle progresse rapidement (cfr
le Newton(TM) d'Apple). Les tablettes graphiques détectent un point soit
par contact entre des feuilles superposées, soit en détectant un
signal magnétique ou sonore émis par un crayon spécial.
Elles sont intéressantes pour entrer des dessins à main
levée, des signatures ou pour étudier l'écriture manuelle.
Si ces technologies sont séduisantes et s'avèrent parfois
pertinentes, il faut néanmoins savoir que la vitesse d'une bonne dactylo
est environ deux fois supérieure à la vitesse moyenne
d'écriture manuelle (Dix et al, 1993). Ce n'est cependant pas le cas de
tous les utilisateurs. De nos jours l'usage clavier n'est plus l'apanage de
ceux qui disposent de compétences dactylographiques.
1.2.1.1.3 Le scanner
Le scanner permet de digitaliser des dessins, images ou du texte.
L'image est analysée en balayant le document au moyen d'un rayon
lumineux et en mesurant l'intensité de la réflexion. Comme les
imprimantes (voir ci-après), la résolution d'un scanner varie de
200 'points par pouce' à 1500 (pour les outils professionnels
d'édition). Pour de petits documents, le défilement du scanner
sur le papier peut être réalisé manuellement (scanners
à main). Pour de plus grands documents, il faut préférer
les scanners plus onéreux dans lesquels le document est introduit comme
dans une photocopieuse. Lorsqu'un texte est introduit au moyen d'un scanner, sa
représentation en machine n'est qu'un ensemble de points. Pour
transformer celui-ci en fichier texte (utilisable par un traitement de texte),
il faut utiliser un logiciel de reconnaissance de caractères (optical
character recognition - OCR). Ceci permet l'archivage rapide et
économique de documents dactylographiés. Ces logiciels produisent
cependant encore un nombre d'erreurs non négligeable et exigent donc une
correction manuelle.
1.2.1.1.4 Le micro
Enfin, il est aujourd'hui possible de transmettre du texte oral à
l'ordinateur via un microphone. Celui-ci, après avoir appris
à reconnaître les particularités phonétiques de son
interlocuteur, est capable de reconnaître des phrases
élémentaires. Au-delà de quelques mots, cette technique se
heurte cependant aux insurmontables difficultés du traitement du langage
naturel (voir module 4). En outre, ces technologies posent des problèmes
de confidentialité ainsi que d'augmentation du bruit dans un bureau (Dix
et al, 1993). Elles s'avèrent pertinentes lorsque l'utilisateur
désire transmettre une commande alors qu'il a les mains occupées
au clavier ou par une autre tâche (par exemple, un dentiste, un pilote),
qu'il a les mains sales (par exemple un garagiste) ou qu'il ne dispose pas de
la dextérité manuelle suffisantes (handicapés)
1.2.1.2 Dispositifs de pointage
Un dispositif de pointage permet de déplacer un curseur vers une
destination précise de l'écran afin de déplacer un objet,
cliquer sur un bouton, etc. Certains programmes différencient le
curseur et le pointeur. Le pointeur texte (un "|") indique où
apparaîtra le prochain caractère typé au clavier. Alors que
le curseur se déplace librement à l'écran, le pointeur ne
peut occuper qu'une position 'légale' du texte. Dans de nombreux
logiciels de traitement de texte par exemple, un 'click' sur la souris
déplace le pointeur vers la plus proche position du curseur disponible
pour l'insertion d'un caractère.
1.2.1.2.1 Modes de contrôle
Ce qui se passe pendant le déplacement du curseur (simple
déplacement, tracé d'un trait, ...) et/ou au terme du
déplacement est déterminé par le programme. La tâche
du périphérique d'entrée se limite à fournir une ou
plusieurs coordonnées (x,y) de points d'écran. Le mode de
contrôle du curseur désigne le rapport entre les actions de
l'utilisateur sur le périphérique et les déplacement du
curseur. On distingue deux modes de contrôle du curseur:
- en mode absolu, la position du curseur sur l'écran
correspond à la position de l'élément mobile du
périphérique (par exemple, la position du stylo sur une tablette,
du doigt sur un écran tactile);
- en mode relatif, les déplacements du curseur à
l'écran correspondent aux déplacements transmis au
périphérique (par exemple, déplacer une icône au
moyen de la souris).
Le mode relatif n'est pas naturel, il requiert un
apprentissage, même si celui-ci est rapide par exemple dans le cas de la
manipulation de la souris. Certains périphériques, tels que les
tablettes graphiques ou le joystick, peuvent fonctionner en mode relatif ou
absolu.
1.2.1.2.2 Echelle affichage/contrôle
Un autre paramètre commun aux dispositifs de pointage est
l'échelle affichage/contrôle ('display/control
gain')(Greenstein & Arnaut, 1988). Cette échelle vaut 1 si un trait
de 7 cm sur une tablette crée un trait de 7 cm à l'écran,
ou si un déplacement de la souris sur 12 cm correspond à un
déplacement identique du curseur. Une échelle inférieure
à 1 (effet sur écran < action sur périphérique)
offre une grande précision dans le dessin et les manipulations. Une
échelle supérieure à 1 (effet sur écran > action
sur périphérique) permet de dessiner et déplacer
rapidement des objets. Si le curseur est contrôlé en mode absolu
et que l'écran est plus grand (ou plus petit) que la surface
d'utilisation du périphérique (par exemple, la taille de la
tablette graphique), l'échelle affichage/contrôle est directement
déterminée par le rapport entre la taille de l'écran et
l'espace de déplacement de la main de l'utilisateur. En mode relatif,
l'échelle est indépendante de la taille de cet espace.
Avant l'utilisation de la souris, le déplacement du curseur se faisait
au moyen des touches du clavier illustrées dans la figure 1.5. La
traduction de mouvements en une séquence de touches est facilitée
lorsque la disposition des touches sur le clavier est cohérente avec les
déplacements associés à chaque touche. La figure 1.2
compare six dispositions de ces touches, les trois premières
étant plus cohérentes que les trois suivantes.
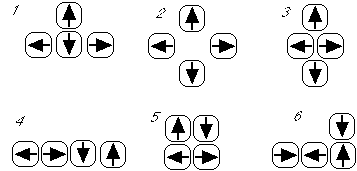
Figure 2.5 : Disposition cohérentes (1-3) ou non (4-6) des touches de
déplacement du curseur.
1.2.1.2.3 Souris
Aujourd'hui le dispositif de pointage le plus utilisé est la
souris, inventée en 1964 par Douglas C. Engelbart. Le
déplacement de la souris sur un plan horizontal provoque le roulement de
la boule située sous la souris. Ce roulement active des
potentiomètres ou autres systèmes de comptage (magnétique
ou optique) qui traduisent le déplacement en cordonnées
horizontales et verticales. Le mode du contrôle du curseur est relatif.
L'échelle contrôle/affichage est contrôlée - et donc
modifiable - par le logiciel. Le succès de la souris s'explique par
l'analogie presque directe entre le déplacement de la souris et celui du
curseur. Cette analogie est cependant affaiblie par certains facteurs: le plan
de déplacement de la souris est perpendiculaire au plan de
déplacement du curseur, le déplacement de la souris sans contact
avec le plan du bureau ne provoque aucun déplacement du curseur, ...
Nous reviendrons prochainement sur ces difficultés. Les
déplacements de la souris sont plus rapides lorsque le sujet
sélectionne un objet situé dans un coin de l'écran que si
l'objet se trouve en milieu d'écran, probablement parce que les bords de
l'écran guident le pointage (Blankenberger & Hahn, 1991).
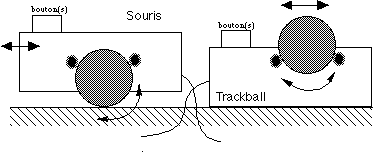
Figure 2.6 : Le 'trackball' est une souris inversée.
L'utilisation de la souris ne comprend pas uniquement le déplacement de
la main de l'utilisateur, mais également l'action de cette main en un
point particulier: pousser un bouton, saisir un objet, le relâcher,
l'ouvrir,... L'utilisateur indique l'action choisie en 'cliquant' sur le ou les
boutons présents sur le dos de la souris. La signification d'un simple
ou d'un double 'click', accompagné ou non d'un déplacement de la
souris, résulte de conventions qui sont encodées dans le
logiciel, nous y reviendrons dans la section 1.3. Les souris disposant de
plusieurs boutons permettent d'entrer plus rapidement des commandes que des
souris mono-bouton pour lesquelles certaines commandes requièrent un
double-click (Price & Cordova, 1983).
Le déplacement de la souris exige un espace non glissant (d'où
l'utilité de tapis) et assez important (au moins 20 cm de
côté). Lorsque cet espace n'est pas disponible, par exemple pour
les ordinateurs portables, il existe une autre version de la souris: le
'trackball'. Sorte de souris à l'envers, l'utilisateur manipule
directement une balle dont la grandeur varie selon les modèles. Dans ce
cas, l'analogie entre déplacement du curseur et l'action de
l'utilisateur est cependant affaiblie. La manipulation efficace d'un
'trackball' nécessite un apprentissage plus important que la
manipulation d'une souris.
De nombreux travaux ont été réalisés afin
d'améliorer l'ergonomie de la souris:
- La forme de la souris est légèrement arrondie afin de mieux
se loger dans la paume; des formes différentes sont
proposées aux gauchers et aux droitiers.
- Les souris sans fil suppriment les difficultés liés à
l'enchevêtrement du câble liant la souris à la machine.
- Les souris optiques (voir figure 1.7) fonctionnent en envoyant un message
lumineux sur une grille réfléchissante et en enregistrant le
déplacement grâce au reflet. Ces souris évitent les
problèmes d'usure et de salissure de la boule, mais exigent de disposer
d'un support approprié.

Figure 2.7 : Souris optique
Un autre inconvénient de la souris est qu'elle mobilise une main de
l'utilisateur, ce qui perturbe fortement la frappe au clavier. Une solution
consiste à remplacer les commandes les plus fréquentes transmises
par la souris par des combinaisons de touche clavier (des 'raccourci-clavier').
D'autres utilisateurs s'entraînent à manipuler la souris de la
main gauche afin de garder leur 'bonne main' pour des opérations plus
complexes. Après tout, les guitaristes droitiers parviennent bien
à des manipulations complexes de la main gauche lorsqu'ils jouent les
accords sur la manche de l'instrument. Il existe également des souris
pour pied ('footmouse'). Il s'agit en réalité de pédales
qui peuvent s'incliner de gauche à droite et d'avant en arrière
et fonctionnent en quelque sorte comme un joystick.
Nous avons évoqué le problème de la
perpendicularité du plan de déplacement de la souris par rapport
au plan de l'écran. Un autre problème est la dissociation des
champs: le champ visuel de l'utilisateur couvre soit le déplacement du
curseur sur l'écran, soit le déplacement de la souris mais ne
peut couvrir les deux simultanément (voir figure 1.8). Ce
problème est particulièrement important lorsque le sujet veut
dessiner un trait en se référant à d'autres objets
présents à l'écran. Tout utilisateur d'un logiciel
graphique a expérimenté par exemple la difficulté
d'écrire son nom avec la souris (et l'outil crayon) comme on le ferait
avec un véritable crayon. Lorsqu'un sujet dessine au moyen d'un
véritable crayon, il perçoit simultanément la naissance du
trait et le déplacement du crayon ce qui permet une régulation
immédiate du mouvement de la main. L'utilisation de la souris implique
une dissociation du plan de trait et du plan de l'outil, ce qui
détériore les possibilités de régulation. Ce
problème concerne particulièrement les outils de dessin qui ont
un effet immédiat sur le document: le crayon, la brosse, le lasso. Il
est moins important pour les outils dont l'effet est différé, par
exemple lorsqu'il s'agit de dessiner une droite: celle-ci n'est tracée
qu'au moment où l'utilisateur relâche le bouton de la souris. Tant
qu'il maintient ce bouton enfoncé, il peut tâtonner. Cette
convention accorde donc à l'utilisateur la possibilité de
réguler son mouvement. D'autres solutions aident la régulation du
mouvement dans le dessin: choix de contraintes sur le tracé ou le
déplacement (horizontal ou vertical uniquement), choix de contraintes
sur les positions (définition d'une grille d'écran),
possibilité de modifier des portions du trait (p.ex. le rayon de
courbure), de lisser une courbe, d'afficher les coordonnées du curseur
ou les dimensions d'un objet, ou encore de générer une courbe en
partant d'une équation ou d'un polygone.
Malgré ces difficultés, Crook (1993) observe qu'après
seulement 5 séances d'entraînement des élèves de 6
ou 7 ans manipulent la souris aussi efficacement que des adultes
débutants. Il observe des performances équivalentes pour les
garçons et les filles. La principale difficulté pour les enfants
surgit lorsqu'il est nécessaire de déplacer la souris en la
soulevant, c'est-à-dire sans déplacer le curseur, afin de
continuer un mouvement.
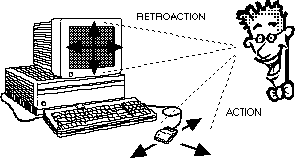
Figure 2.8 : Dissociation des champs moteur et visuel
Nous verrons en outre que la souris peut également servir de
périphérique de sortie.
1.2.1.2.4 Joystick
D'autres dispositifs permettent d'indiquer une position ou un
déplacement. Le joystick a été essentiellement
utilisé dans les jeux. Certains joystick fonctionnent de fonction
isométrique, c'est-à-dire transmettent un signal proportionnel
à la force appliquée au manche. En mode de contrôle absolu
du curseur, étant donné le rapport entre l'espace de manipulation
du manche et la taille de l'écran, l'utilisation d'un joystick exige une
échelle affichage/contrôle de l'ordre 5 à 10. Ces rapports
posent des problèmes de précision du positionnement. Il est alors
préférable de fonctionner en mode relatif (dans lequel,
rappelons-le, le choix de l'échelle dépend du concepteur). Mais
en règle générale, l'utilisation du joystick n'est pas
recommandée pour les tâches de précision.
1.2.1.2.5 Les écrans tactiles
Les écrans tactiles permettent au sujet de désigner un
point sur l'écran, soit avec le doigt, soit avec un stylet. Pour
certains écrans, la pression du doigt met en contact deux grilles
perpendiculaires qui permettent de détecter la position (X,Y) du point
d'impact. D'autres écrans tactiles fonctionnent par réflexion
d'un rayon infrarouge ou ultrason qui balaie l'écran, ces derniers ayant
une moins bonne résolution que les premiers (voir la définition
de ce concept plus bas). A l'inverse, avec un écran normal, le sujet
peut utiliser un stylo lumineux (light pen). Celui-ci détecte le
passage du rayon lumineux qui balaie l'écran. La position du stylo est
déterminée par la durée nécessaire au rayon pour
atteindre le stylo. Ces techniques de pointage (et éventuellement de
déplacement ou de dessin) suppriment toute étape
intermédiaire dans la désignation d'un objet, telle que le
problème de perpendiculaire des plans. La différence est notoire
pour les jeunes enfants et pour les personnes souffrant de certains handicaps.
Les écrans tactiles sont largement utilisés dans les bornes
interactives disposées dans les musées, gares, offices
touristiques,.. brefs des dispositifs exposés à un large public.
En effet, le clavier et la souris constituent des interfaces plus fragiles
qu'un écran encastré dans un meuble. Les écrans tactiles
sont également pertinents lorsqu'il est essentiel que l'opérateur
ne quitte pas l'écran des yeux pour effectuer une commande
(systèmes de contrôle, radars, ...). Toutefois, l'utilisation
prolongée d'un écran tactile est assez fatigante car
l'utilisateur doit maintenir le bras levé. Selon Dix et al. (1993), si
l'utilisation de l'écran tactile s'avère indispensable, il est
souhaitable de l'incliner, de le coucher presque, l'angle idéal
étant 15 degrés par rapport à l'horizontale. En outre, le
doigt n'est pas un moyen très précis de pointer un objet. Le
crayon lumineux ou le stylet offrent plus de précision.
Etant donné que ces écrans comportent en général
une vitre au-dessus du verre de l'écran proprement dit, la distance
entre les deux verres pose parfois des problèmes précision, en
particulier lorsque l'utilisateur ne se trouve pas bien en face de l'objet
désigné. Ces problèmes sont accrus lorsque l'objet se
trouve sur le bord de l'écran et que la vitre du moniteur est arrondie.
Sear et Schneiderman (1991) observent que, lorsque l'objet-cible est petit, le
pourcentage d'erreur et le temps nécessaire pour sélectionner un
objet sont moins élevés lorsque le sujet utilise une souris que
lorsqu'il utilise un écran tactile. Il semble que la dimension verticale
de l'objet contribue davantage à réduire les erreurs que la
dimension horizontale. Ceci est peut-être lié au biais
observé qui consiste à viser un peu trop haut par rapport
à l'objet (Greenstein & Arnaut, 1988). Enfin, un dernier
inconvénient lié aux écrans tactiles est la
possibilité que la main ou le bras masque partiellement les informations
affichées.
1.2.1.2.6 Tablette graphique
Lorsque le dessin à main levée joue un rôle essentiel, deux
solutions peuvent être envisagées: le scanner, déjà
décrit précédemment, et la tablette graphique. Le
problème de la dissociation entre l'apparition du trait et le mouvement
de la main disparaît si l'utilisateur peut placer une feuille de papier
sur la tablette et voir son dessin se créer normalement sur ce papier
sans devoir se référer à l'écran. Cette solution
favorise les tablettes qui fonctionnent en créant un contact entre deux
couches: on peut dans ce cas utiliser un crayon normal sur une feuille de
papier posée sur la tablette (ce qui n'est pas le cas des tablettes
exigeant un stylet électrique ou lumineux). Les tablettes utilisent de
préférence un mode de contrôle du curseur 'absolu', car
celui-ci donne à la tablette graphique sa ressemblance avec le dessin
sur papier. Le mode relatif est cependant utile lorsque les dimensions de la
tablette sont inférieures à celles de l'écran. Une
échelle affichage/contrôle inférieure à 1 fournit
une bonne précision mais ralentit le trait. Une solution de compromis
entre vitesse et précision a été mise au point sur des
tablettes dont l'échelle augmente lorsque le déplacement
s'accélère: par exemple, un déplacement rapide du doigt
sur 3 centimètres donnera lieu à un tracé à
l'écran de 6 cm (échelle a/c = 2), alors qu'un déplacement
lent sur 3 centimètres donnera lieu à un tracé de 3
centimètres (échelle a/c = 1) (Greenstein & Arnaut, 1988).
La tablette doit disposer d'un système permettant de signifier à
la machine la fin d'un input (et donc son traitement), comme la touche "return"
au clavier ou le bouton sur la souris. Diverses conventions peuvent être
choisies pour définir ce que nous appellerons un 'signal
d'émission de réponse' (cfr module 5):
- le stylo est équipé d'un bouton;
- l'input est traité dès que le sujet lève son doigt ou
son stylo;
- l'input est traité lorsque le sujet pointe dans une zone
spécifique de la tablette définie comme l'équivalent d'un
bouton "ok";
- l'input est traité lorsque le sujet presse une touche
spécifique du clavier (ou tout autre périphérique que le
clavier);
- toute combinaison des trois conventions précédentes
Il
existe encore d'autres dispositifs de pointage. Par exemple, certains
systèmes montés sur un casque (ou sur un appareil photo)
permettent de détecter le point de visée de l'oeil. La technique
utilisée consiste à lancer un faible rayon laser sur la
rétine et à mesurer son point de réflexion. Souvent, ces
systèmes sophistiqués et coûteux sont utilisés pour
des applications militaires.
Enfin, une limite fondamentale des périphériques décrits
réside dans le fait qu'elle ne transmet que des déplacements dans
un espace à deux dimensions. La construction d'objets tridimensionnels
relève alors de l'utilisation de conventions syntaxiques qui permettent
de préciser dans quel plan se situe chaque action. Certaines souris
permettent de désigner des points dans un espace à trois
dimensions (par rapport à trois récepteurs disposés dans
l'espace). L'avenir réside certainement dans des techniques telles que
le 'dataglove' qui permet d'exprimer directement toutes les manipulations
tridimensionnelles réalisables au moyen de ses dix doigts.
1.2.2 Actions du système (output)
1.2.2.1 Feedback tactile et moteur (dataglove, joystick, souris)
Commençons par ce point original: la souris peut également servir
de périphérique de sortie, transmettant des messages tactiles ou
moteurs. Dans les années 70, Bliss et ses collègues (1970)
développent un périphérique de lecture pour non-voyants
(appelé " Octacon ": il s'agit d'une matrice de 24 X 6
micro-aiguilles qui reproduit la forme exacte des caractères (il ne
s'agit pas d'écriture Braille) et sur laquelle le sujet pose le doigt.
Après 20 heures d'apprentissage, ils observent des vitesses de lecture
allant jusqu'à 70 mots par minute.
Le principe de feedback tactile a été développé en
outre pour les `dataglove': des transmetteurs sont placés au bout des
gants afin de fournir au sujet la sensation de saisir l'objet. Toutefois, comme
le signalent Akamatsu et ses collègues (1995), au moyen de ces gants, le
sujets peut encore passer `à travers' l'objet, ce qui n'est pas
très réaliste.
D'autres systèmes permettent de transmettre des messages tactiles:
Logitech a mis sur le marché un joystick qui tremble en cas d'alerte;
Akamatsu et ses collègues (1994a) décrivent une souris dont le
déplacement sur une plaque métallique peut être
freiné par des électro-aimants (placés dans la souris et
contrôlés par le système): l'intensité de la
résistance au déplacement informe l'utilisateur sur la texture
sur laquelle le curseur se déplace à l'écran.
Les travaux les plus précis concernent l'utilisation de la souris comme
feedback tactile. Comme nous l'avons dit plus haut, dans l'utilisation de la
souris, l'espace de déplacement moteur et l'espace de régulation
visuelle sont dissociés. Dans la vie quotidienne, selon la tâche
que nous réalisons, la vision n'assure que partiellement la
régulation du mouvement, l'action motrice étant davantage
régulée par des sensations tactiles et kinesthésiques: on
peut, tout en gardant les yeux fermés, porter une tasse de thé
à la bouche, faire son lacet ou jouer de la guitare, ... Dans certains
cas, la `préhension' d'un objet au moyen de la souris implique une forte
charge visuelle: c'est particulièrement le cas lorsqu'il faut
`sélectionner' une ligne dont l'épaisseur n'est que de 1 pixel.
Göbel et ses collègues (1995) rapportent des expériences
réalisées au moyen d'un souris dotée de quatre
éléments `vibrant', deux éléments placés sur
les côtés de la souris, deux éléments placés
sous les boutons normaux de la souris. Ces éléments se mettent
à vibrer lorsque le curseur approche un objet de l'écran. Ils
observent que cette information tactile conduit à une
détérioration de la performance pour des tâches dans
lesquelles le sujet devait poursuivre un objet à l'écran. Par
contre, le feed-back tactile a permis un gain de temps de près de 20%
pour les tâches de positionnement d'un objet et de sélection d'un
objet (tâches plus fréquentes pour un utilisateur moyen), et ce
malgré que les sujets aient disposé d'un faible temps
d'apprentissage. Les auteurs concluent que l'efficacité de la souris
comme périphérique fournissant un feed-back tactile dépend
d'un réglage fin de la relation entre, d'une part, la distance entre le
curseur et l'objet-cible, et d'autre part, le signal tactile transmis à
l'utilisateur. Akamatsu et ses collègues (1994b) obtiennent des
résultats semblables ( gain de temps de 12%) avec un autre feed-back
tactile: une petite pointe en aluminium, située à
l'intérieur d'un des boutons de la souris, entre en contact avec le
doigt lorsque le curseur entre en contact avec un objet. Ils observent que ce
gain du temps provient d'une réduction de la distance moyenne entre la
position du curseur au moment où le sujet clique et le centre de
l'objet: sans feed-back tactile les sujets on tendance à clique au
centre de l'objet, avec le feed-back tactile, ils cliquent dès qu'ils
`sentent' l'objet du bout de leur doigt. Notons en outre que, dans une autre
étude, Akamatsu et ses collègues (1994a) montrent que lorsque le
feed-back tactile était combiné à un feed-back sonore et
visuel, le gain de temps n'était pas supérieur à
l'utilisation du feed-back tactile seul.
1.2.2.2 Les écrans
La plupart des écrans sont basés sur la technique du tube
cathodique: un canon à électrons émet un rayon
d'électrons, dirigé par des champs magnétiques. Les points
de l'écran ('pixels') contiennent des éléments
phosphorescents qui émettent de la lumière lorsqu'ils sont
frappés par le rayon d'électrons. Ce rayon 'balaie' (scan)
l'écran de gauche à droite, ligne par ligne, du haut de
l'écran vers le bas. Grâce à la persistance de l'image
rétinienne, l'oeil humain ne perçoit pas ce balayage pour autant
qu'il soit effectué à une vitesse importante (environ 60 fois par
seconde). L'augmentation de cette fréquence permet de réduire
l'effet de scintillement. Cet effet reste cependant perceptible lorsqu'on tente
de filmer un écran au moyen d'une caméra vidéo dont la
propre vitesse de balayage (le même principe, mais inversé) n'est
pas synchronisée avec celle du moniteur. Certains écrans
rafraîchissent alternativement les lignes impaires et paires, ce qui
diminue encore le scintillement, mais détériore la qualité
de l'image (ceci est utilisé uniquement dans des écrans bon
marché).
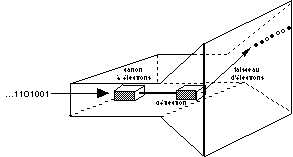
Figure 2.9 : Fonctionnement d'un écran cathodique
Certains écrans permettent d'afficher différents niveaux de
gris en variant l'intensité du rayon d'électrons. Les
écrans couleur émettent trois rayons d'électrons
à destination de pixels rouges, bleus et vert. Le blanc s'obtient en
activant ces trois pixels simultanément. Ces trois points
phosphorescents sont groupés pour apparaître comme formant un
point unique, ce qui explique que les écrans couleur ne produisent pas
la même précision dans l'image que les écrans noir et
blanc. C'est au concepteur de décider si cette légère
perte de précision est justifiée par l'information
supplémentaire qu'apporte la couleur (sachant qu'en outre les
écrans couleur sont beaucoup plus chers et exigent davantage de
mémoire).
La définition d'un écran est le nombre de points qu'il
peut afficher: elle varie actuellement entre 640 X 480 (norme appelée
'VGA') et 1600 X 1200 (voire davantage mais à des prix inabordables).
Jusqu'à un certain degré, la définition n'est pas
liée à la taille de l'écran: un petit écran peut
afficher un grand nombre de pixels si ceux-ci sont plus petits. La dimension
d'un écran s'exprime généralement par la longueur de la
diagonale (en pouces). Une écran de type A4 correspond environ à
15 pouces. Le rapport entre ces deux mesures, la définition et la
taille, déterminent la résolution de l'écran,
c'est-à-dire le nombre de pixels par pouce carré (dots per inch =
dpi). Cette notation est également utilisée pour les imprimantes
et les scanners. Une résolution moyenne pour un écran est de
l'ordre de 70 dpi.
La qualité de l'image ne dépend pas uniquement de la
qualité de l'écran mais également de l'information
graphique transmise. Par profondeur de pixel, on désigne le
nombre de bits d'information fournis pour chaque point de l'écran. Si
chaque pixel est décrit par un seul bit (0 ou 1), ce pixel ne
peut-être que noir ou blanc. Avec deux bits, on peut définir 4
modes d'affichage d'un point (4 niveaux de gris). Avec N bits, on peut
définir 2N niveaux de gris pour un même point. Pour
obtenir de la couleur, il faut multiplier cette information par trois (une fois
pour le bleu, une pour le rouge et une pour le jaune). Le traitement de cette
information est généralement pris en charge par des cartes
graphiques. Dans la gamme des PC-compatibles, ces cartes portent le nom de EGA,
VGA, Super-VGA, etc.
La taille et la résolution d'un écran, ainsi que la profondeur du
pixel sont des paramètres importants pour le concepteur de logiciel
interactif. En voici trois exemples:
- Lorsque la résolution d'écran et/ou la profondeur de pixel
conduisent à une médiocre lisibilité de l'image, il est
préférable d'utiliser un schéma clair plutôt que de
s'entêter à présenter une image embrouillée.
- La conception d'un programme doit tenir compte de l'espace disponible. Si
l'utilisateur travaille sur un document (texte, dessin, fichier), reste-t-il
assez d'espace libre pour afficher certains outils? Si c'est le cas, ces outils
seront utilisables en parallèle avec l'édition du document.
Sinon, les outils doivent être superposés au document. Le
concepteur doit alors prévoir le cas où l'outil cache de
l'information utile et doit donc pouvoir etre déplacé ou
caché. La présence simultanée de l'outil et du document ou
leur alternance peuvent modifier en profondeur l'interaction, par exemple au
niveau des contraintes mnémoniques imposées à
l'utilisateur.
- Un des problèmes bien connus de cette technique de balayage est la
discontinuité des lignes obliques ('jaggies'). Ce problème est
d'autant plus perceptible que la résolution de l'écran est basse.
Il ne s'agit pas seulement d'une question d'esthétique: il est parfois
difficile pour le sujet de savoir s'il doit voir une seule ligne mal
affichée ou deux lignes juxtaposées. Ce problème peut
être réduit en complétant la ligne par des points gris
(voir figure 1.10). Cette technique s'appelle anti-aliasing (Dix et al,
1993).
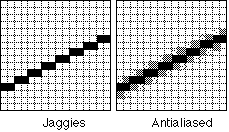
Figure 2.10 : Jaggies et Anti-aliasing
Etant donné que les écrans cathodiques reposent sur la projection
d'électrons, plus l'écran est grand, plus il doit être
profond. Certaines techniques peu répandues utilisent un canon à
rayon perpendiculaire, ce qui permet un écran plat. On trouve maintenant
beaucoup d'écrans à cristaux liquides (LCD = liquid crystal
display), surtout pour les ordinateurs portables. Ces écrans souffrent
cependant encore de certains problèmes, en particulier une
définition maximale de 640 X 480, ainsi que la nécessité
d'être face à l'écran pour percevoir l'image correctement.
Ceci rend par exemple difficile la collaboration entre deux utilisateurs face
à une seule machine. Néanmoins, ce problème tend à
disparaître avec les écrans les plus récents.
L'utilisation intensive d'un écran d'ordinateur peut
générer des troubles de la santé, dus à la
présence de champs électrostatiques et
électromagnétiques (surtout à l'arrière de
l'écran) ainsi qu'à l'émission de rayons-X. Ces recherches
sont soumises à de nombreuses polémiques et ne concernent
qu'indirectement le concepteur de logiciel interactif. Néanmoins, Dix et
al. (1993) recommandent de:
- ne pas s'asseoir trop près de l'écran;
- ne pas utiliser de trop petites polices de caractère;
- ne pas regarder l'écran trop longtemps sans interruption;
- faire attention aux reflets;
- -ne pas travailler face à une fenêtre recevant beaucoup de
lumière.
Récemment la société ICL(TM) a mis sur
le marché un écran qui est équipé de capteurs
devant et derrière l'écran pour calculer la répartition de
la lumière et adapter en conséquence les réglages de
l'écran. Il dispose même d'un équipement qui permet de
régler l'éclairage de la pièce (si cet éclairage
est réglée par infrarouges).
1.2.2.3 Son
Alors que la technologie de traitement des sons numériques est fortement
développée, le son est probablement l'aspect le moins
exploité de l'interaction personne-machine. Depuis peu, certains
ordinateurs sont dotés (de série) d'un microphone, de cartes
'son' et d'amplificateurs de qualité. Cette limitation est moins due
à des aspects techniques que conceptuels, à savoir quel
rôle joue le son dans l'interaction. Dans la plupart des cas, le
rôle du son se limite à une version du 'bip' qui attire
l'attention de l'utilisateur. Toutefois, le développent rapide des
techniques du multimédia et l'utilisation de supports identiques pour le
son, l'image ou le texte laisse envisager un développement très
rapide des interfaces sonores. Nous y revenons dans le module 9.
La numérisation du son repose sur deux facteurs comparables à
ceux utilisés pour l'image. Pour représenter la courbe continue
d'un son en une série de nombre, on procède à un
échantillonnage: on prélève une série de points
dans la courbe. Par exemple, dans un CD-audio, l'échantillonnage est de
44100 points par second (44,1 MHz), alors qu'il est de 8 MHz pour la voix
téléphonique. Cette 'densité' d'information correspond
à la résolution d'une image. Pour chaque point de la courbe, on
mémorise une information comprise qui occupe 8 bits pour la voix et 16
bits la musique CD. La norme MIDI est une convention de représentation
des sons mise au point pour standardiser la communication entre les ordinateurs
et les instruments de musique.
1.2.2.4 Imprimantes
La technologie des imprimantes et leur coût ont rapidement
évolué au cours des dernières années. On distingue
plusieurs type d'imprimantes:
- Les imprimantes à caractères préformés ont
presque disparu aujourd'hui. Elle frappent un caractère à la fois
parmi ceux disponibles sur une marguerite ou une boule. Ce caractère
percute le papier à travers un ruban à encre. Ces boules
étant interchangeables, il est possible de travailler avec plusieurs
polices de caractères, mais pour chaque changement de police, il faut
interrompre l'impression. En outre, ces imprimantes sont bruyantes et ne
supportent que le texte (pas le graphisme).
- Les imprimantes matricielles impriment point par point le texte et le
graphisme: un sous-ensemble d'une matrice d'aiguilles percute le papier
à travers un ruban à encre. Elles produisent un texte de
qualité inférieure aux autres imprimantes. Leur résolution
varie de 80 à 120 dpi. Bruyantes mais bon marché, elles sont
encore utilisées lorsque l'utilisateur a peu d'exigences quant à
la qualité du produit (brouillons, listings,...). Pendant de nombreuses
années, le papier était bordé de bandes perforées
afin que les roues à picots de l'imprimante entraînent le papier.
- Dans les imprimantes à jet d'encre (ink-jet ou bubble-jet), la
tête d'écriture projette des gouttes d'encre sur le papier. Ces
imprimantes sont silencieuses, et approchent la résolution d'une
imprimante laser (300 dpi) pour un prix généralement
inférieur.
- Les imprimantes thermiques ont une tête d'écriture qui
chauffe un papier réagissant à la chaleur. Ce papier de type
'fax' est moins agréable que le papier normal. Ces imprimantes ont
cependant plusieurs avantages. Elles sont plus simples que les autres du point
de vue mécanique et requièrent moins de fournitures (d'où
leur utilisation dans les grandes centrales d'impression). En outre, elles sont
plus facilement miniaturisables (pour portables, fax,...). Leur
résolution est de 80 à 120 dpi (comme les imprimantes
matricielles).
- Les imprimantes à laser bombardent de points
électrostatiques un rouleau qui est en contact avec une poudre noire
('toner'). Cette poudre se fixe aux points du rouleau qui sont chargés
électrostatiquement. Lorsqu'une feuille blanche s'engage dans le
rouleau, ces points de toner se déposent sur la papier. Celui-ci est
ensuite chauffé afin de fixer le toner. Aujourd'hui (janvier 1994), la
résolution d'une imprimante laser est en moyenne de 300 dpi, bien que
les imprimantes professionnelles utilisées par les éditeurs
aillent jusqu'à 1200 dpi.
La technologie des imprimantes influence
moins directement l'interaction personne-machine, puisque l'impression
intervient généralement dans la phase finale de
l'élaboration du produit. Cette affirmation doit cependant être
nuancée si on considère la relation entre l'affichage d'un
document à l'écran et son impression sur papier. En dehors des
nostalgiques de formateurs tels que NROFF ou LATEX, la philosophie dominante en
matière de traitement de texte, de dessin ou de publication est connue
sous l'acronyme 'WYSIWIG": "What you see is what you get"... ce qui
signifie que ce que l'utilisateur voit à l'écran devrait
correspondre exactement à ce qu'il obtiendra sur papier. Cet
isomorphisme est difficile à obtenir car la précision de
l'imprimante est généralement supérieure à celle de
l'écran: en moyenne, la résolution d'une imprimante laser est de
300 dpi alors que celle d'un écran tourne autour de 70 dpi. Lorsque
l'utilisateur justifie un texte, le système calcule l'espace entre les
mots de telle sorte que cet espace soit régulier sur la ligne. Le calcul
se base sur la résolution de l'imprimante, admettons qu'il calcule que
l'espace sera de neuf points. Cet espace ne peut être
réalisé sur l'écran, puisqu'un pixel écran
correspond à six points-papier. Une solution consiste à
intercaler une fois six points, une fois douze. Le texte à
l'écran sera donc quelque peu différent de celui qui sera produit
sur papier. L'utilisateur doit dans ce cas avoir la possibilité de
pré-visualiser l'apparence de son document sur papier.
Il existe d'autres différences entre l'affichage d'un objet sur
l'écran et son impression sur papier. Lorsque l'écran est
inférieur à la taille du papier, l'utilisateur doit pouvoir
disposer le contenu de plusieurs écrans sur une même feuille et
visualiser le résultat. Certaines différences entre la version
à l'écran et la version sur papier sont liées au mode de
communication entre l'ordinateur et l'imprimante: soit celui-ci transmet
directement l'image à imprimer en tant qu'ensemble de points (bitmap),
soit l'ordinateur décrit la page à imprimer au moyen d'un langage
de description. Ces langages ne sont pas compris par toutes les imprimantes, le
plus connu d'entre eux est le postscript. Ces langages décrivent
les actions qui permettent à l'imprimante de reconstruire les objets:
afficher le mot 'Introduction' dans la police 'helvetica', taille 10, en gras;
dessine un cercle de centre (300,470), de diamètre 30 et
d'épaisseur 7. En mode bitmap, un cercle souffrira des mêmes
problèmes que sur l'écran (jaggies). Par contre, en mode
postscript, pour autant qu'il ait été créé en mode
objet et non en mode point, le cercle sera dessiné selon la
résolution de l'imprimante.
1.2.3 Le traitement de l'information par la machine
Les périphériques d'entrée transmettent un signal à
la machine. Celle-ci traite ce signal afin de produire un output. Le traitement
est réalisé par le processeur central et ses divers
collaborateurs (co-processeurs arithmétiques, cartes graphiques, ...).
Le traitement proprement dit est déterminé par le logiciel, mais
ses performances sont influencées par des facteurs matériels
(mémoire, fréquence,...)
1.2.3.1 La mémoire
L'unité de mesure de la mémoire est le byte, lequel permet de
stocker un caractère alphanumérique ou un petit nombre. On
exprime la taille d'une mémoire en kilobytes (milliers de bytes ou Kb),
megabytes (millions de bytes ou Mb), gigabytes (milliards de bytes ou Gb) ou
terabyte (mille milliards). La vitesse d'accès est exprimée en Mb
par seconde ou baud. Comme dans l'étude de la mémoire humaine, on
distingue différentes mémoires, qui remplissent
différentes fonctions:
- La mémoire sensorielle permet de stocker les inputs du clavier ou
de la souris dans des 'buffers' en attendant leur traitement.
- La mémoire de travail s'appelle mémoire vive (ou random
access memory - RAM). Elle permet à l'ordinateur de stocker des
informations pendant qu'il travaille. Ces informations sont perdues lorsqu'on
éteint l'ordinateur.
- La vitesse d'accès aux informations contenues en mémoire
vive varie de 10 à 120 Mb par seconde selon la technique utilisée.
- Comme mémoire à long terme, l'ordinateur utilise les
supports magnétiques ou optiques. Les supports magnétiques
incluent les disquettes souples ou dures (stockage: 800 Kb à 1,4 Mb),
les disques durs (stockage: entre 40 Mb et 2 Gb) et les bandes
magnétiques. Celles-ci servent surtout à l'archivage de copies de
sécurité car leur temps de lecture est plus long. Les supports
optiques permettent de stocker plusieurs gigabytes.
Les limites de
mémoire influencent les fonctionnalités que le concepteur peut
offrir: combien d'états intermédiaires du document peuvent
être mémorisés en vue de multiples 'undo', combien de
documents ou d'applications peuvent être ouverts simultanément ?
La taille des mémoires influence également la vitesse
d'exécution des programmes. En effet, lorsque l'ensemble des
informations nécessaires ne peuvent être maintenues
simultanément en mémoire vive, l'excédent d'information
est écrit provisoirement sur le disque dur ('paging'). Par exemple,
certains logiciels de traitement de texte ne chargent en mémoire vive
que les pages affichées à l'écran. Au moment d'afficher la
page suivante, le logiciel lit celle-ci sur le disque, ce qui ralentit
l'interaction.
Il est important de souligner que, malgré l'utilisation de techniques de
compression des données (voir module 9), l'insertion d'images
digitalisées ou de séquences vidéo implique des
capacités de stockage très importantes, qui dépassent les
capacités habituelles des disques magnétiques actuels.
1.2.3.2 Microprocesseur
La vitesse de fonctionnement est influencée par plusieurs facteurs: le
processeur, le type d'instructions, le nombre d'instructions
simultanées, l'efficacité des bus (canaux d'information
internes), la mémoire (et les caches), la présence d'un
co-processeur arithmétique, la puissance des cartes graphiques,... et la
cadence de l'horloge interne du microprocesseur (en megaHertz). Cette cadence
et l'architecture du processeur déterminent le nombre d'instructions que
l'ordinateur peut traiter par seconde (million of instructions par seconds =
Mips). La vitesse actuelle est de l'ordre de 10 mips mais ce nombre devrait
croître vers 100 Mips dans un proche avenir. Le nombre de Mips ne
détermine pas nécessairement la vitesse de réaction.
D'autres facteurs en en ligne de compte, en particulier le type de processeur.
Le concepteur retiendra qu'il est nécessaire de tester son programme sur
la machine-type sur laquelle il sera distribué et d'être attentif
à certains nombre de problèmes qui peuvent naître d'une
lenteur d'exécution:
- Lorsque le sujet clique sur une icône ou un bouton, il arrive que
l'ordinateur ne réponde pas immédiatement parce qu'il effectue un
calcul quelconque. Dans ce cas, le sujet pensant que l'ordinateur n'a pas
perçu son action, clique souvent une deuxième fois sur le
même objet ou sur un autre sans se rendre compte qu'il demande en fait
plusieurs actions. Celles-ci sont stockées dans le buffer
d'entrées, mémoire dans laquelle les inputs sont stockés
jusqu'au moment où ils sont lus par le processeur. Ces actions sont
ensuite transmises sans que le sujet puisse les arrêter. Une solution
consiste à vider le buffer. Une autre solution consiste à
signaler à l'utilisateur que sa commande a été
reçue et est en cours d'exécution en affichant un message du type
'quelques secondes de patience' ou un symbole graphique équivalent (par
exemple, le curseur prenant la forme d'une montre ou d'un sablier).
- Lorsque la machine ne peut réaliser le déplacement d'un
objet à la vitesse imposée par le programme, certains
systèmes 'sautent' les étapes intermédiaires du dessin,
c'est-à-dire dessinent l'objet tous les N pixels au lieu de le
redessiner à chaque pixel. La course de l'objet apparaît alors
comme saccadée. Si l'utilisateur doit cliquer sur l'objet en mouvement,
ces saccades rendront sa tâche difficile, voire impossible. Pour
contourner ce problème, certains systèmes se contentent de
n'afficher que le contour de l'objet en cours de déplacement.
- Certains systèmes distribuent les différentes tâches
à différents processus internes. Des conflits peuvent
apparaître du fait que certains processus sont trop lents et se font
dépasser par des processus qu'ils auraient dû
précéder (par exemple, l'ouverture d'une fenêtre se fait
dépasser par l'écriture du contenu de la fenêtre).
- Certains modes d'interaction sont limités par la capacité du
sujet à maintenir en mémoire des informations utiles à
l'interaction. C'est le cas par exemple lorsque le système réagit
à une action du sujet que celui-ci a déjà oubliée.
Si ce risque existe, le concepteur devra modifier l'interaction, par exemple
dans ce cas en rappelant l'action concernée.
- Si la lenteur pose des problèmes, la vitesse soulève
également des problèmes, même si ceux-ci sont moins graves
et moins fréquents. Par exemple, imaginons que le concepteur ait
prévu d'afficher un message 'Patience, je travaille' pendant les
quelques secondes nécessaires pour effectuer une opération. Si
cette même opération ne dure qu'une fraction de seconde sur une
machine plus puissante, l'utilisateur verra apparaître un message sans
avoir le temps de le lire. Bien souvent, ce sujet sera anxieux d'avoir
manqué un message dont il ignore l'importance.
Ce dernier point
illustre un aspect difficile de la tâche du concepteur: celui-ci doit non
seulement éviter les problèmes de lenteur et de vitesse sur sa
machine, mais il doit en outre anticiper les problèmes liés
à l'utilisation de son programme sur des machines plus lentes ou moins
lentes. Aujourd'hui, tout programme est destiné a fonctionner sur une
gamme de machines qui, même à l'intérieur d'une marque,
peuvent grandement varier en performance. Le cas le plus fréquent est
que le développeur possède une machine plus puissante que celles
du public-cible. Une solution consiste à déterminer les
caractéristiques des machines qui affectent significativement le
fonctionnement du logiciel et de concevoir un programme qui s'adapte à
ces caractéristiques (soit en vérifiant directement des aspects
tels que la taille mémoire, soit en interrogeant l'utilisateur sur ces
caractéristiques).
1.3 Les 'objets logiciels'
Le matériel informatique détermine les bornes de l'espace que le
concepteur explore à la recherche d'un design. Cet espace est vaste et
non structuré. Si on considère uniquement la sortie vidéo,
l'espace brut du concepteur se constitue des milliards de combinaisons de N
points (N = définition d'écran) que l'on puisse former en
attribuant à chaque point une couleur parmi les M couleurs possibles (M
dépend de la profondeur du pixel). Heureusement, le concepteur dispose
d'un ensemble de concepts de plus haut niveau qui lui permettent de structurer
cet ensemble de points en objets graphiques: fenêtres, icônes,
menus,... La plupart des outils de développement permettent au
concepteur de s'exprimer directement au moyen de ces concepts et de ne
descendre au niveau du pixel que lorsque les concepts offerts au niveau
supérieur ne correspondent pas à ce qu'il cherche. Nous
décrivons brièvement les objets les plus communs:
- Le curseur: petit objet graphique qui se déplace à
l'écran et indique la position de la prochaine action. Le curseur est
l'équivalent électronique de la main de l'utilisateur
(Billingsley, 1988). Les curseurs les plus fréquents sont la barre
verticale pour indiquer la prochaine opération sur un texte, la
flèche pour désigner un objet, la croix pour dessiner un pixel
individuel, la gomme pour effacer un ensemble de pixels, la loupe, la montre,
etc. La forme du curseur renseigne l'utilisateur sur la nature de
l'opération qu'il va effectuer ou qu'il est en train d'exécuter.
La relation métaphorique entre la forme du curseur et l'opération
peut cependant induire certaines ambiguïtés (par exemple, le
rôle du curseur en forme de main).
- Les icônes: objets graphiques qui représentent un
fichier, un programme, un outil ou une opération. Le symbole graphique
est éventuellement complété par un mot. La relation
sémantique entre une icône et l'objet ou la commande qui lui est
associé s'appelle 'distance articulatoire' (Blankenberger & Hahn,
1991). Lodding (1983) distingue les icônes figuratives (par exemple, une
imprimante), les icônes abstraites (par exemple, une feuille de papier
qui représente un fichier) et les icônes arbitraires (pas de lien
évident entre l'icône et sa signification). Certaines icônes
animées permettent de représenter l'état ou la
transformation d'état de l'objet: lorsque l'icône de la poubelle
gonfle, elle indique qu'au moins un fichier est en attente d'effacement;
lorsque l'icône 'facteur' trépigne, elle indique qu'un message est
en attente, etc. Parmi les conventions établies, on notera qu'une
icône apparaissant en contraste inversé indique que l'objet
correspondant a été sélectionné et une icône
apparaissant en gris signale généralement que cet objet est
ouvert ou en fonction (donc non disponible). Blankenberger & Hahn (1991)
comparent des représentations iconiques et textuelles d'un jeu de
commandes de traitement de texte. Les deux modes de représentation ne se
différencient pas quant au taux d'erreur, mais les
représentations iconiques conduisent en général à
des temps de réaction plus courts (sauf si la représentation
textuelle a des qualités graphiques particulières). La
supériorité des icônes est accrue si celles-ci apparaissent
à des positions fixes.
- Les fenêtres: sous-espaces de l'écran
indépendants les uns des autres, que l'on peut considérer comme
des écrans dans l'écran. L'utilisateur peut
généralement les fermer, les déplacer, les agrandir ou les
rétrécir au moyen de 'poignées' (boutons particuliers
décrits ci-après) ou de commandes figurant dans les menus. Au
sens large, toute zone d'écran (y compris un menu) est une
fenêtre. Au sens devenu plus habituel, une fenêtre constitue une
ouverture à travers laquelle l'utilisateur aperçoit une partie
d'un document, d'un fichier ou peut entrer des commandes. Il existe deux
manières de faire défiler le contenu d'une fenêtre au moyen
des barres de défilement (scrollbars): déplacer le contenu dans
la fenêtre ou la fenêtre sur le contenu. Dans le second cas,
abaisser l'ascenseur (ou slider - le symbole représentant la position de
la fenêtre dans le document) provoque donc un défilement du
document vers le haut. Cette différence est souvent source d'erreurs de
manipulation chez le débutant. Certains 'sliders' varient en longueur
afin d'indiquer le rapport entre la quantité d'information
présentée dans la fenêtre et celle disponible dans le
fichier. On pourrait imaginer que chaque page d'un document soit
affichée dans une fenêtre différente, poussant en cela
jusqu'au bout la célèbre métaphore du bureau. Toutefois,
en n'ouvrant qu'une fenêtre par document (et en obligeant donc
l'utilisateur à 'scroller' à l'intérieur de cette
fenêtre pour accéder aux diverses pages du document), on a pu
réduire fortement la complexité des interfaces (Billingsley,
1988). Fermer une fenêtre consiste soit à la faire
disparaître de l'écran, soit à la réduire à
la taille d'une icône ('iconify'). L'utilisation de systèmes
multi-fenêtres a un impact significatif sur les méthodes de
travail (pour autant que l'écran soit suffisamment grand), car cela
permet à l'utilisateur de travailler sur plusieurs documents ou
programmes simultanément, de passer d'une tâche à une autre
pour un coût très faible (cliquer dans la bonne fenêtre)
(Billingsley, 1988). On distingue les systèmes dans lesquels les
fenêtres sont juxtaposées ('tiling') et superposées
('overlapping'). Dans les premiers, l'écran est divisé en N
fenêtres par le système ou par l'utilisateur. L'espace propre
à chaque fenêtre est relativement limité. Dans les
systèmes à superposition, la taille de chaque fenêtre est
indépendante de la taille des autres fenêtres. L'utilisateur doit
utiliser diverses commandes pour faire passer une fenêtre devant ou
derrière une autre. En d'autres termes, les systèmes de
fenêtres juxtaposées sont bi-dimensionnels (Billingsley, 1988),
alors que les systèmes à fenêtres superposées
ajoutent une troisième dimension, la profondeur de l'écran. La
fenêtre active, celle qui est au-dessus de toutes les autres, est
généralement affichée dans un graphisme différent
(bords surlignés, couleur différentes ou autre effet visuel).
- Les menus désignent en réalité toute question
à choix multiple intervenant en cours d'interaction. On distingue les
menus de type 'pop-up' qui sont affichés en plein écran au cours
de l'interaction et les menus permanents qui se trouvent en haut de
l'écran ou d'une fenêtre et s'ouvrent lorsque le sujet clique sur
le titre du menu et tire ensuite la souris vers le bas (d'où le nom
'pull-down' menu). Certains menus sont hiérarchisés,
c'est-à-dire comprennent des sous-menus.
Le terme WIMP
désigne les interfaces basés sur ces quatre
éléments (windows, icons, menus and pointers). D'autres objets
sont généralement associés:
- Les boutons simples transmettent une commande au système,
les boutons 'radio' permettent de choisir une option parmi un choix d'options
exclusives et les 'check-box' permettent de sélectionner plusieurs
options complémentaires au sein d'une liste.
- Les palettes présentent un jeu d'icônes qui ont des
fonctions similaires, par exemple un ensemble d'outils de dessin, un ensemble
de patterns de remplissage de forme,...
- Les boîtes de dialogue sont des fenêtres de type
'pop-up', généralement ni déplaçables ni
modifiables, utilisées pour communiquer une information brève
à l'utilisateur. Leur utilisation ponctuelle est souvent liée
à une clarification de l'interaction personne-machine. Leur affichage
au-dessus de toute autre fenêtre interrompt momentanément
l'activité du sujet. L'usage abusif de ces interruptions peut irriter
l'utilisateur.
L'alphabet du concepteur de logiciels interactif comporte en
outre un certain nombre d'objets de base dont les propriétés ont
été progressivement standardisées:
- des lignes droites, courbes ou brisées et autres arcs de cercle
dont l'utilisateur peut déterminer l'épaisseur, le motif
(pattern) de remplissage, le pattern du trait, la couleur, la présence
d'une flèche à une ou aux deux extrémités, ...
- des polygones réguliers ou irréguliers dont l'utilisateur
peut arrondir les angles, épaissir les côtés, fixer le
pattern et la couleur, la transparence;
- des paragraphes dont le sujet peut choisir la police de caractère,
la taille, le style (gras, italique,...), la justification, l'espacement des
lignes, les tabulations, les bordures, la position, le dictionnaire
associé, la numérotation, l'hyphénation, ...
- les bitmaps, c'est-à-dire des ensembles de pixels,
créés soit par des outils de dessin (dont le fameux 'spray' qui
permet les dégradés) ou par numérisation (scanning) d'un
document;
- les objets complexes construits à partir de plusieurs des objets
élémentaires décrits ci-dessus, selon un ordre de plans
déterminé par l'utilisateur;
- les objets résultant de la déformation des objets
élémentaires décrits ci-dessus: rotation, agrandissement,
réduction, déformation selon un axe, étirement à
partir d'un sommet, ...
- ...
Deux remarques importantes doivent être formulées
ici, l'une concerne l'utilisateur novice, l'autre l'utilisateur
expérimenté. Le premier éprouve parfois des
difficultés à 'penser' son document en termes de ces objets. Par
exemple, il n'existe pas d'outil de dessin qui construise un disque avec un
large trou au centre. Le dessinateur doit donc penser à créer un
disque plein et puis à y superposer un disque blanc. Un autre exemple
concerne la difficulté des novices à concevoir un paragraphe
comme un objet en tant que tel, avec un certain nombre de
propriétés attachées, plutôt que comme une
séquence de lignes (séparées par une ligne blanche de la
séquence suivante).
A l'opposé, un utilisateur familier maîtrise la manipulation
directe et la métaphore du bureau. Par exemple, lorsqu'il déplace
une icône fichier d'une fenêtre vers une autre, il se concentre
uniquement sur le déplacement du fichier d'un répertoire vers un
autre. En réalité, sur le plan informatique, il demande au
système d'éteindre et d'allumer certains pixels de telle sorte
que l'ensemble des points de l'icône représentant un 'fichier'
soient, au prochain balayage de l'écran par le canon à
électrons, redessiné un pixel plus a droite, et cela un grand
nombre de fois consécutivement. Cependant, grâce à la
vitesse du procédé, l'utilisateur a vraiment l'impression de
déplacer un objet. Il en arrive facilement à concevoir un curseur
ou une fenêtre presque comme des objets physiques, qu'il
déplacerait réellement. C'est cette illusion qui définit
la manipulation directe. Toutefois, en tant que concepteur, il faut rester
conscient que seul le programme traduit les actions de la souris en actions
à l'écran. C'est le programme (ou la superposition des couches
logicielles) qui définit quels points afficher à l'écran,
quels écritures réaliser sur le disque, etc. Le rôle du
concepteur est de concevoir ces mécanismes de réponse du
système, non de les ignorer.
Voici quelques exemples de mécanismes qui définissent la syntaxe
et la sémantique implicites de la manipulation directe:
- cliquer sur un objet le sélectionne en vue d'une opération
future;
- cliquer deux fois rapidement sur un objet vise à 'ouvrir' cet
objet, c'est-à-dire à lancer l'application associée
à cet objet (si ce n'est pas déjà le cas et d'ouvrir le
document au sein de cette application (le délai entre deux 'clicks'
successifs devant être considérés comme formant un
double-click est généralement réglable);
- cliquer sur le corps d'un objet, garder le bouton enfoncé tout en
bougeant la souris déplace l'objet préalablement
sélectionné, ce déplacement pouvant créer une trace
(par exemple si l'objet est un crayon);
- cliquer sur une 'poignée' d'un objet (généralement un
petit rectangle placé sur un sommet ou sur un côté de
l'objet) et garder le bouton enfoncé tout en bougeant la souris,
déplace ce point de l'objet sans déplacer les autres
'poignées', ce qui déforme l'objet (allongement,
rétrécissement, ...) ;
- lorsqu'un objet est sélectionné, on peut en
sélectionner un second en enfonçant la touche majuscule (ou
'contrôle') au moment où on sélectionne sur l'objet suivant;
- cliquer â côté d'un objet et déplacer la souris,
sélectionnera tout objet dans le rectangle fictif (parfois
matérialisé à l'écran par un contour en
pointillé) dont le déplacement de la souris forme la diagonale;
- la touche 'majuscule' crée généralement des
contraintes sur le dessin construit: la droite dessinée ne peut
être que verticale, horizontale, ou à 45 degrés par rapport
à l'horizontale, l'objet sélectionné ne peut être
déplacé que verticalement ou horizontalement, le polygone en
cours de création sera régulier (côtés
isométriques); ...
En réalité, ces mécanismes
sont aujourd'hui devenus des 'standards'. D'une part, ils sont fortement
intégrés dans l'architecture des systèmes, à un
niveau auquel le concepteur ne désire généralement pas
intervenir. D'autre part, ils sont devenus part entière de la culture
informatique de base et créent de ce fait une inertie semblable à
celle du clavier QWERTY. Ce succès remarquable dans l'histoire des
interfaces s'explique de deux manières complémentaires. En
premier lieu, les métaphores utilisées sont simples et
intuitives. Par exemple, ouvrir un objet (double click) exige une intention
plus forte que de le désigner (simple click); déplacer un objet
peut se percevoir comme 'le garder suspendu', etc... Toutefois, ces conventions
conservent - par définition - un caractère arbitraire. Aussi, la
seconde raison de leur succès est liée à leur utilisation
homogène à travers un grand nombre de programmes (politique
imposée par Apple(TM) aux sociétés développant du
logiciel pour le Macintosh(TM)).
1.4 Du matériel ou de l'imagination?
J'aimerais ici formuler une remarque quant à la 'souplesse' du
concepteur. Lorsque les contraintes techniques imposées par le hardware
sont incompatibles avec le projet du concepteur, il est tentant de penser
à acquérir du matériel complémentaire. Il est
opportun de considérer d'abord les possibilités de créer
avec le matériel disponible une forme d'interaction fonctionnellement
équivalente à la forme initialement prévue. Il faut
comparer ce qu'on perd en changeant l'interaction avec ce que coûterait
l'acquisition du matériel complémentaire. Par exemple, le
'dataglove' permet au sujet de déplacer des dossiers tridimensionnels.
Cependant, vu le coût de cet interface, il convient de s'interroger sur
les bénéfices réels de l'ajout de la troisième
dimension et, en cas de réponse négative, de se contenter de
représentations planes (manipulables au moyen de la souris).
Prenons un autre exemple. J'ai souvent rencontré le problème
suivant. Un concepteur a utilisé ou a vu un programme écrit dans
un langage X ou fonctionnant sur une machine Y. Il désire transposer ce
programme sur une machine Z et dans un langage W. Certaines des
fonctionnalités offertes par le tandem X-Y ne sont pas disponibles dans
le tandem Z-W et vice-versa. Au lieu de s'entêter à reproduire
à tout prix les détails de telle interaction, présente
dans le programme original, mais non supportée par Z-W, et d'y consacrer
des heures de programmation, il faut exploiter ce qui dans le nouveau langage
permettra de construire une interaction fonctionnellement
équivalente. Le terme 'fonctionnellement' signifie que cette
interaction transmet la même information à l'utilisateur ou de
l'utilisateur, qu'elle sollicite la même activité cognitive chez
l'utilisateur.
1.5 L'interface d'Authorware
Authorware exploite largement les concepts et objets décrits dans ce
module, tant au niveau de l'interface entre le programme créé et
l'utilisateur qu'au niveau de l'interface entre le concepteur et Authorware
lui-même. Il convient de distinguer les fenêtres 'auteur' et les
fenêtres 'élève'. Les premières contiennent le
'code' graphique composé par l'auteur. Les secondes correspondent
à ce que l'utilisateur verra à l'écran. L'auteur dispose
les fenêtres 'élève' dans les fenêtres 'auteur' sous
la forme d'icône de présentation.
1.5.1 Dessiner son organigramme.
Construire un programme dans la fenêtre 'auteur' consiste à
prélever des icônes dans une palette et à les
déposer sur une ligne. Cette ligne représente le
déroulement chronologique du programme (à lire de haut en bas).
Elle constitue la colonne vertébrale de l'organigramme du logiciel. Cet
organigramme est assez proche des organigrammes généralement
réalisés sur papier. L'auteur ne dessine pas directement les
traits entre les icônes. Ces traits sont générés par
Authorware selon l'endroit où l'icône a été
déposée et selon certaines options, spécifiques à
l'icône déposée et modifiables par l'auteur. L'interface
auteur-Authorware s'inspire donc directement des principes de la manipulation
directe.
1.5.2 L'icône de présentation.
Elle permet de créer un écran tel qu'il apparaîtra
à l'utilisateur. En double-cliquant sur cette icône, l'auteur peut
en composer le contenu. Par exemple, s'il veut qu'un cercle rouge apparaisse
dans le coin supérieur droit, il y dessine simplement ce cercle rouge.
Dans un langage moins évolué, il devrait décrire cette
action plutôt que de la faire, en entrant une commande du genre "
drawcircle (top window, red, 2344,233,65) ". Cette approche s'apparente
également à la manipulation directe et hérite donc de ses
limites, par exemple lorsque si l'auteur désire afficher un cercle dont
la taille n'est déterminée qu'en cours d'exécution du
programme (par exemple, le cercle rétrécit lorsque les
réserves d'oxygène du vaisseau spatial s'épuisent). Nous
verrons que Authorware supporte également cette approche (utilisation de
fonctions de dessin dans l'icône de calcul).
1.5.3 Outils graphiques.
Lors de l'édition de l'icône de présentation, une seconde
palette apparaît. Elle constitue une version réduite de ce
qu'offrent les logiciels de dessin. Les outils offerts sont
complétés par plusieurs menus qui permettent de déterminer
la couleur des objets, leur transparence, leur position, leur épaisseur,
le motif de remplissage, etc... Ces fonctionnalités sont relativement
standard et documentées dans le guide de l'utilisateur. Certaines
d'entre elles seront étudiées ultérieurement, telles que
la possibilité de positionner un objet de façon variable ou
d'intégrer la valeur d'une variable dans un texte. Si les
capacités de dessin intégrées dans Authorware ne suffisent
pas, il convient de créer (ou traiter) le dessin (ou l'image) dans un
logiciel spécialisé et de le transférer via le
presse-papier. Nous conseillons à l'apprenti-auteur qui n'aurait aucune
expérience avec un logiciel de dessin de s'exercer au préalable
avec ce genre d'outils afin d'être familiarisé avec les outils et
les objets graphiques.
1.5.4 Mode vectoriel
Authorware fonctionne en mode vectoriel pour l'auteur et en mode 'calque' pour
l'utilisateur. Les différents objets affichés sur un écran
peuvent être modifiés individuellement par l'auteur lorsqu'il
édite cet écran. Par contre, lors de l'exécution du
programme, les opérations programmées (effacement, animation,
sélection d'objets) portent sur l'ensemble des objets d'une même
icône de présentation. Lorsqu'on désire animer deux objets
selon des trajectoires diverses ou à des vitesses différentes, ou
effacer deux objets à deux moments différents, la seule
façon de rendre deux objets indépendants pendant
l'exécution consiste à les créer dans des icônes
différentes. Si ces icônes se succèdent sans effacement
intermédiaire, les deux objets apparaîtront simultanément
à l'écran.
1.5.5 La fenêtre 'élève'.
Authorware repose sur le postulat d'une fenêtre 'élève'
unique. L'auteur spécifie la dimension de la fenêtre dans laquelle
le programme sera exécuté (option 'file setup' dans le menu
file). Le choix comporte notamment les standards EGA et VGA cités dans
ce module. Il est important d'effectuer ce choix dès le début de
la réalisation d'un programme. En effet, modifier la taille de la
fenêtre ultérieurement peut condamner le réalisateur
à réagencer l'ensemble des écrans qu'il aura construits au
préalable. Nous conseillons toutefois à l'auteur, débutant
lorsqu'il construit uniquement des programmes pour son propre apprentissage
d'Authorware, de travailler avec le format de fenêtre 'variable'. Il peut
alors réduire celle-ci de telle sorte que il puisse voir en
arrière-plan la fenêtre dans laquelle il construit son programme
et en avant plan le résultat de l'exécution.
2. La présentation des informations visuelles
Ce module concerne la présentation des informations à
l'écran de l'ordinateur. Cette présentation est contrainte par
plusieurs facteurs: la nature de la tâche que l'utilisateur veut
réaliser, les caractéristiques techniques du système
utilisé (voir module 1) et les particularités de notre
système cognitif. Ce module se penche surtout sur les aspects cognitifs.
Il met en relation différents paramètres de présentation
de l'information avec les composantes de notre système cognitif
impliquées dans le traitement de ces informations (perception,
mémoire, charge de travail, attention,...).
2.1 Exploration
Imaginons que vous deviez concevoir un logiciel interactif expliquant le
fonctionnement d'une écluse. Ce système pourrait être
placé dans une borne interactive à usage touristique ou
être exploité par un enseignant dans le cadre du cours de
géographie. Votre point de départ serait par exemple le texte
suivant:
"La péniche arrive par le bassin amont. Le niveau du sas de
l'écluse est bas. Il convient en premier lieu de l'élever. On
ouvre pour cela les vannes de la porte amont. Le niveau du sas
s'élève à la même hauteur que le plan d'eau amont.
L'équilibration des niveaux d'eau de part et d'autre de la porte amont
permet d'ouvrir celle-ci. La péniche peut donc s'introduire à
l'intérieur de l'écluse. On referme ensuite la porte amont et on
ouvre les vannes de la porte aval. L'eau du sas s'écoule doucement vers
le plan aval jusqu'au moment où le niveau du sas est égal
à celui du bassin inférieur. L'équilibration des niveaux
en aval permet à présent d'ouvrir celle-ci. La péniche
peut donc quitter le sas et continuer sa route sur le bassin
inférieur."
La séquence des programmes "Ecluse" (voir module 2) illustre le
processus de design d'un logiciel (faiblement) interactif.
- Dans la version 1, le temps de lecture pour chaque écran est
fixé d'avance. L'utilisateur n'a pas le temps de lire le texte. Il est
certes possible d'augmenter le temps de telle sorte que tout utilisateur puisse
le lire. Dans ce cas, le temps peut être trop long pour les lecteurs
rapides. En outre, cette solution ne résout pas le problème de
l'utilisateur qui interrompt la lecture pour observer une écluse, pour
parler avec quelqu'un ou pour toute autre raison.
- La version 2 compense ce défaut en présentant un bouton du
type "presse ici pour continuer". On s'assure de cette manière que
l'utilisateur a eu le temps de lire le texte avant qu'il soit effacé.
Par contre, la présentation de ce texte entier sur un seul écran
demeure nettement indigeste.
- Aussi, dans la version 3, le texte a été
découpé en plusieurs morceaux. La granularité du
découpage n'est pas extrême puisque certains écrans
comportent plusieurs phrases. Le critère de découpage
était de garder ensemble les informations concernant une même
phase du fonctionnement de l'écluse. Nous traiterons dans ce module du
problème de la quantité d'informations présentées.
- La version 4 cherche à enrichir la version 3 par des
procédés typographiques d'emphase visuelle: caractères
gras, soulignés, italiques, polices variées,... Cette version
souffre cependant de l'utilisation excessive de ces procédés. Une
utilisation abuse des modes de mise en évidence nuit à leur
efficacité.
- La version 5 accompagne chaque étape de graphiques qui illustrent
le texte présenté. La granularité du découpage a
été augmentée: l'information est maintenant
distillée au compte-gouttes.
- Vu que le texte décrit un processus dynamique, nous avons
animé les schémas dans la version 6. La quantité
d'information comprise dans ces schémas animés inverse le rapport
image/texte: alors que dans la version 5, le schéma était au
service du texte, dans la version 6, c'est le texte qui est subordonné
à l'image. Ce n'est pas le graphique qui illustre le texte, mais le
texte qui commente le graphique. La quantité de texte est d'ailleurs
réduite par rapport au texte de départ.
- Enfin, la version 7 agrémente le scénario d'un certain
nombre de bruits. Ceux-ci ne jouent probablement qu'une rôle mineur dans
la compréhension du fonctionnement d'un écluse.
Ces sept
versions du programme illustrent - de façon un peu caricaturale - le
processus de design d'un logiciel interactif. Le point de départ
était l'information contenue dans le texte décrivant le
fonctionnement des écluses. Le résultat est un logiciel dont
l'aspect extérieur est assez éloigné du matériel de
départ. Ce logiciel est certes faiblement interactif. Nous aurions pu
prévoir des situations dans lesquelles le sujet déplace le
bateau, commande l'ouverture des portes, etc. Dans ce module, nous nous
limitons cependant à la présentation (et l'effacement)
d'informations. Les modes d'interaction feront l'objet des modules suivants.
Le processus de design peut se comparer au travail d'un architecte. Il
n'existe pas d'algorithme qui parte d'un jeu d'intentions, y applique un
ensemble de lois universelles et génère de façon
déductive les spécifications précises d'un
édifice/d'un logiciel. Comme en architecture, le design est un processus
créatif qui consiste à rechercher une solution qui satisfasse un
grand nombre de contraintes partiellement contradictoires. Une partie de
ces contraintes proviennent de la technologie utilisée. Nous les avons
abordées dans le module précédent. Certaines contraintes
sont liées à la tâche réalisée par
l'utilisateur au moyen du logiciel développé et au contexte
physique et social de l'utilisation du système. D'autres contraintes
résultent des limites de capacité et de traitement de
l'utilisateur. Ce module considère certaines propriétés du
système cognitif humain: perception, mémoire, charge mentale,...
Ce module concerne la présentation d'informations visuelles. Toutefois,
le rôle de la perception dans l'interaction personne-machine ne se limite
évidemment pas à la vision. Le son est de plus en plus
utilisé, bien qu'actuellement, il s'agit le plus souvent d'utilisations
assez rudimentaires. Nous reviendrons sur l'exploitation du son dans le module
9. D'autres mécanismes perceptifs entrent en jeu. Par exemple, la
perception de la position des segments de notre corps est indispensable
à l'utilisation du clavier et à la manipulation de la souris.
Elle ne fait pas l'objet d'une grande attention de la part des chercheurs, mais
devrait attirer un intérêt plus important lorsque des
périphériques tels que le 'dataglove' seront plus répandus.
2.2 Perception visuelle
La perception des messages visuels dépend de l'acuité visuelle du
sujet, c'est-à-dire sa capacité à percevoir des objets
selon le rapport entre la grandeur de l'objet et la distance entre l'oeil et
l'écran. Pour décrire les dimensions d'un objet
indépendamment de la distance oeil-écran, on précise
l'amplitude de l'angle visuel. Le concepteur peut tenir compte de
problèmes d'acuité visuelle en jouant sur la taille des objets
présentés. D'autres facteurs influencent la perception: la
couleur, la brillance et le contraste.
La perception de la couleur repose sur la longueur d'onde, allant du bleu pour
les ondes les plus courtes au rouge pour les plus longues. Notre oeil
perçoit les ondes entre 400 et 700 nanomètres (nm). En dessous de
400 nm, on parle d'ultraviolet et au-dessus de 700 nm on parle d'infrarouges.
Entre 400 et 700 nm, notre oeil discrimine environ 128 longueurs d'onde
différentes. La perception des couleurs est plus fine pour les zones
'jaune' et 'bleu-vert' (Thomson P, 1984). Pourtant, l'oeil est capable de
discriminer environ 7 millions de couleurs (Dix. et al, 1993), car sa
perception est également influencée par deux autres facteurs, la
saturation et la brillance.
La saturation est la quantité de blanc ajoutée à une
couleur, le rose étant par exemple un rouge non-saturé. La
brillance est un concept psychologique, c'est une réponse subjective
à la lumière. La luminosité est une mesure
objective de la lumière reflétée par une surface. La
brillance devrait être proportionnelle à la luminosité mais
elle est influencée notamment par des effets de contraste (voir figure
2.1). Le contraste est définit par la formule suivante (Thomson P,
1984):
Contraste = (Lmax + Lmin) / (Lmax - Lin)
où Lmax et Lmin représentent les luminosités maximale et
minimale.

Figure 3.1 : Effet du contraste sur la perception de la brillance (les deux
carrés centraux ont la même brillance) (selon Thomson, 1984).
Il ne faut pas confondre la capacité de l'oeil à percevoir une
différence de couleur entre 2 pixels (afin de détacher par
exemple un objet du fond de l'image) et la capacité cognitive à
nommer une couleur. La première capacité permet de
différencier plusieurs millions de couleurs, la seconde une dizaine
(Thomson, 1984).
Environ 8% des hommes et 1% des femmes ne peuvent discriminer le rouge et le
vert (Dix et al., 1993). Cela ne signifie pas qu'il faille éliminer ces
couleurs d'un logiciel. Cependant, dans le cas où la discrimination de
ces couleurs jouent un rôle important dans le logiciel, il n'est pas
inutile d'associer une autre code a chaque couleur. Cette information sera
redondante pour la plupart des utilisateurs, sauf pour les daltoniens. C'est le
cas de feux rouges: confondre le rouge et le vert serait dramatique si ces
couleurs n'étaient pas placées à des positions bien
différentes.
La luminosité augmente l'acuité visuelle, la profondeur de champ
(par réduction du diamètre de la pupille) et diminue les
problèmes de reflet. Elle augmente par contre la perception du
scintillement de l'écran (Thomson P., 1984). Lorsqu'une lumière
apparaît et disparaît très vite, l'homme la perçoit
comme constante sauf si la fréquence d'affichage est inférieure
à 50 Hz (voir fonctionnement des écrans dans le module
précédent). Il arrive que le sujet perçoive le
scintillement d'un écran dont la fréquence dépasse 50 Hz
lorsque la luminescence est très forte. En outre, la sensibilité
au scintillement est plus forte dans la vision périphérique, ce
qui explique que l'on perçoive plus de scintillement dans les grands
écrans.
L'information perçue est stockée pendant une très
brève durée dans la mémoire sensorielle, un
registre propre à chaque modalité sensorielle (vue, ouïe ou
toucher). L'information visuelle y reste environ 0,5 seconde. Par
conséquent, un objet présenté à deux endroits
différents de l'écran en moins de 0,5 seconde sera perçu
comme présent simultanément à deux endroits (Dix et al.,
1993). A la différence du buffer dont disposent certains
périphériques d'entrée, les stimuli stockés en
mémoire sensorielle ne sont pas nécessairement traités
dans l'ordre de leur entrée. On observe par exemple un effet de
'backward making': un son est plus difficile à identifier lorsqu'il est
suivi par une son semblable que lorsqu'il est suivi d'un silence (Thomson N.,
1984). La capacité de stockage de la mémoire sensorielle ne
serait pas déterminée par une quantité maximale
d'information, mais par le temps nécessaire pour traiter cette
information (Thomson, 1984). Par exemple, un sujet parlant vite arrive à
retenir de plus longues séquences de chiffres. Il semble que la
mémoire sensorielle serve tant de 'buffer' d'entrée que de
'buffer' de sortie, notamment au niveau de la parole et du mouvement des doigts
(dactylographie). La mémoire sensorielle ne doit pas être
confondue avec la mémoire à court terme au sein de laquelle
l'information peut être conservée de façon volontaire.
2.3 Lisibilité des écrans
Une grande partie des informations est présentée à
l'écran sous forme de texte. De nombreuses études se sont
intéressées à la lisibilité des écrans.
Selon Muter et al. (1982), la lecture est plus lente (+ 28.5%) sur
l'écran que dans un livre. Toutefois, dans ces expériences les
lignes de texte affichées à l'écran ne comprenaient que 39
caractères alors que les lignes de texte imprimées en contenaient
60. Or, une étude de Duchnicky et Kolers (1983) montre que la vitesse de
lecture est plus lente lorsque les lignes comprennent 26 caractères que
lorsqu'elle en comprennent 78 (par contre, ils n'observent pas de
différence entre les longueur de lignes de 52 et 78 caractères).
En d'autres termes, il est difficile de comparer la lecture sur papier et la
lecture sur écran car dans les deux cas la disposition du texte sur
le médium peut avoir un impact supérieur au
propriétés intrinsèques du médium (Hulme,
1984). En outre, la qualité des écrans et des cartes graphiques
évolue rapidement. Les résultats expérimentaux obtenus
avec un type d'écran particulier sont rapidement
périmés.
Bien qu'il soit difficile de tirer des lois générales, les
utilisateurs se forgent pourtant des habitudes qui reflètent les
problèmes de lisibilité d'écran. Par exemple, un
utilisateur intensif de courrier électronique lira sur l'écran
les messages ne dépassant pas la page, mais il préférera
imprimer les messages plus longs ou ceux qui demandent plus de
réflexion. De même, lorsque l'utilisateur d'un traitement de texte
désire relire un document de plusieurs pages, seule la version papier
lui permet de retrouver toutes les erreurs. Intuitivement, ces utilisateurs
savent que lire un long texte est plus éprouvant sur l'écran que
sur papier.
La question de lisibilité nous conduit à prendre en
considération la quantité d'information présentée
à l'utilisateur. Tous les auteurs s'accordent pour recommander de
minimiser la quantité d'information affichée à
l'écran. On parle de densité d'information pour
désigner le rapport entre la quantité d'information
présentée et l'espace disponible. La NASA (1980) recommande par
exemple de ne pas dépasser une densité de 60%. Cette mesure de la
densité s'effectue en comptant les espaces de l'écran qui sont
occupés par un caractère et ceux qui restent libres. Cette mesure
est réaliste si on se préoccupe de perception. Elle est
relativement simpliste du point de vue cybernétique car la même
information peut être exprimée par un nombre très variable
de caractères. Plus simplement, il convient d'éviter de
surcharger l'écran avec des informations qui ne sont pas strictement
nécessaires à l'accomplissement de la tâche (sauf bien
sûr dans des logiciels, notamment certains logiciels de jeu qui
présentent délibérément des informations inutiles
et attendent de l'utilisateur qu'il fasse le tri). Certaines informations ne
sont nécessaires qu'occasionnellement, par exemple au début, ou
en cas de problème. Elles peuvent être déplacées
dans un autre écran, accessible via un menu ou un bouton. En appliquant
ce principe systématiquement, on en arrive à la notion
d'hypertexte (voir module 10): les informations principales sont
découpées en unités simples, mais connectées
à des exemples, à des détails ou à cas analogues,
présentés dans d'autres pages.
Le principe d'information minimale concerne non seulement l'information
textuelle, mais aussi les autres formats de présentation: tableaux,
images fixes et animées, graphiques, schémas,... Par exemple, une
photographie comprend généralement plus d'information qu'un
schéma. Il convient de s'assurer que ces informations
supplémentaires soient utiles, permettent une meilleure perception de
l'objet ou du phénomène observé. Si ce n'est pas le cas,
un schéma dépourvu du 'bruit' de l'image peut être
préférable. Ce n'est pas parce que la technologie permet de
présenter des images de plus en plus riches qu'il faut
nécessairement présenter l'image la plus riche possible: le mieux
est parfois l'ennemi du bien.
Comme tous les principes que nous évoquerons, le principe d'information
minimale doit être nuancé en fonction du type d'utilisateur
(Schneiderman, 1992). En effet, les logiciels tels que les systèmes de
réservation de billets d'avion ou de transactions boursières
utilisent des écrans fortement chargés en information. Certes,
seule l'information utile est présentée, mais certaines
tâches nécessitent la présentation d'une information
abondante. En outre, dans de nombreux systèmes, une partie de cette
information est codée (abréviations, acronymes, numéros
d'identification,...) afin de réduire l'espace nécessaire pour
chaque information et de pouvoir donc en afficher davantage. Les
abréviations augmentent la densité d'information. Ces
écrans surchargés s'adressent à des utilisateurs 'experts'
(voir module 6). Il s'agit de personnes qui utilisent quotidiennement le
système. Ils connaissent bien la structure de l'écran et sont
capables, malgré la haute densité d'information, de trouver
directement une information précise et de percevoir rapidement un
changement dans une donnée pertinente.
Si les efforts de quantification de l'information ont donné peu de
résultats convaincants (Tullis, 1988), on trouve des études
intéressantes sur l'espacement entre les mots et entre les lignes. Ces
variables constituent une façon indirecte d'estimer la quantité
d'information.
- Espacement entre les mots et justification. Dans un système
qui ne dispose pas de polices de caractères à largeur variable
(aussi appelées polices proportionnelles), si l'utilisateur
désire justifier le texte, le système devra espacer les mots de
façon variable afin d'obtenir un alignement du bord droit du texte.
Plusieurs études ont montré que l'espacement irrégulier
des mots avait un effet négatif sur les temps de lecture, plus
négatif que le non-alignement de la fin de chaque ligne (Tullis, 1988).
- Espacement entre les lignes. Intuitivement, chacun sait qu'un trop
faible espacement entre les lignes rend un texte moins lisible. Cette
observation est confirmée par des études empiriques qui
recommandent que l'espace entre deux lignes soit égal ou
légèrement supérieur à la hauteur des
caractères utilisés (Tullis, 1988). Cet espacement est d'autant
plus nécessaire que les lignes sont longues (ibidem.)
Plusieurs
études concernent la lisibilité des textes écrits
entièrement en majuscules. On pourrait penser qu'il ne s'agit pas d'un
paramètre spécifique à l'interaction homme-machine. En
réalité, au début des années 80, il arrivait
fréquemment de rencontrer sur un ordinateur des textes
entièrement écrits en majuscules. Tinker (1965) établit
que lire des textes en majuscules est environ 14% plus lent que des textes en
majuscules et minuscules. Cette différence semble due au fait que notre
lecture est saccadée: l'oeil ne 'glisse' pas sur le texte de
façon continue, mais reste fixé une fraction de seconde sur un
mot, puis saute au suivant. Les moments de fixation sur un mot constituent 94%
du temps de lecture. Sachant qu'un adulte lit environ 250 mots par minutes, on
comprend qu'il ne peut déchiffrer ces mots caractère par
caractère, mais que, dans la majorité des cas, il reconnaît
directement le mot en tant que tel, en tant que pattern visuel (ou au moins ses
constituants). Or, la forme d'un mot est liée à la
variété des lettres. Lorsque ces mots sont entièrement en
majuscules, le mot prend une forme rectangulaire. Cette perte d'identité
visuelle (voir figure 2.2) expliquerait le ralentissement de la lecture des
mots en majuscules.

Figure 3.2 : L'utilisation de majuscules diminue l'identité visuelle du
mot
Par contre, si dans un texte où alternent normalement majuscules et
minuscules, un mot se trouve entièrement écrit en majuscules, il
attirera davantage l'attention du lecteur. Le concepteur de logiciels
interactifs dispose d'une multitude de procédés d'emphase
visuelle: il peut jouer avec les polices de caractères, la taille des
caractères, leur style (gras, souligné, italique,...), leur
couleur, il peut afficher mot en mode vidéo-inversé (en blanc sur
fond noir) ou en sur-brillance, l'encadrer ou le faire clignoter. Certains de
ces procédés appartiennent depuis longtemps à la
typographie et ne sont pas spécifiques à l'interaction
personne-machine. En outre, il existe plusieurs formes de clignotement:
afficher/effacer, afficher en brillance forte puis faible, afficher en mode
vidéo normal, puis en mode inversé. Selon Smith & Mosier
(1986), la fréquence de clignotement idéal est de 2 à 5
fois par seconde, pour autant que le temps pendant lequel le mot est
effectivement lisible représente au moins 50% du cycle
affichage-effacement. Le clignotement est un procédé d'emphase
visuelle assez radical qui est moins utilisé de nos jours. Il est
utilisé pour signaler les informations urgentes. Il est alors souvent
accompagné d'un message sonore. Ces procédés d'emphase
visuelle ne sont efficaces que s'ils sont utilisés avec parcimonie: si
un texte comprend un mot en couleur, celui-ci attirera l'attention; s'il
comprend une dizaine de mots en couleur, cet effet sera perdu. Les
procédés d'emphase consistent essentiellement à
différencier un élément particulier au sein d'un ensemble
d'éléments présentés. L'emploi abusif des
procédés d'emphase leur enlève toute efficacité.
2.4 Structure des écrans
L'attention n'est pas uniquement influencée par les artifices de
présentation cités dans la section précédente, mais
aussi par des aspects plus structurels. En voici deux exemples observés
auprès de pilotes d'avion (Wickens, 1987):
- Les pilotes vérifient le plus souvent l'altimètre parce
qu'il est l'indicateur qui varie le plus souvent, c'est-à-dire celui qui
a le plus de chances d'apporter une information nouvelle. Parmi les facteurs
qui conduisent l'attention du sujet vers un élément, il y a donc
un aspect statistique.
- La perception de patterns tels que le parallélisme des aiguilles
des nombreux cadrans facilite la détection d'informations nouvelles (non
- parallélisme de l'aiguille d'un des écrans).
Les
études sur la mémoire à court terme soulignent
l'intérêt de structurer l'information en unités de plus
haut niveau. De nombreuses recherches ont établi que cette
mémoire peut contenir entre 5 et 9 éléments d'information.
Toute la question consiste à savoir ce qu'on identifie comme un
élément d'information. Il semble cependant qu'on puisse
dépasser cette capacité maximale en structurant les informations
en objets de plus haut niveau, intégrant des informations
élémentaires. L'interface peut guider l'utilisateur dans la
construction d'objets complexes et structurés.
La mémoire à court terme conserve spontanément
l'information pendant une coutre durée (200 ms). Toutefois, en mettant
en oeuvre des mécanismes volontaires de maintien, la
répétition par exemple, il est possible de maintenir en
mémoire l'information pendant le temps nécessaire pour la
réalisation d'une tâche. On parle alors plutôt de
mémoire de travail. Nous reviendrons ultérieurement sur le
rapport de l'information avec la tâche et l'activité du sujet.
L'organisation des écrans constitue une étape critique de la
conception des interfaces. Cette structure résulte de l'identification
de zones (cadres, couleur de fond,...), de groupes d'objets (alignements,
proximité,...) et de relations entre items (de même couleur, de
même graphisme, ...). L'importance de la structure est illustrée -
de façon délibérément caricaturale - par les
figures 2.3 a et b (inspirées de Tullis, 1988), qui présentent un
panorama fictif des cinémas d'une ville . Dans la figure 2.3,
l'information est listée comme un texte. Dans la figure 2.4,
l'information est structurée en différentes zones, ce qui
facilite la lecture de l'écran et les comparaisons.

Figure 3.3: Présentation de l'information en format texte

Figure 3.4 : Présentation structurée de l'information
L'étude de la structure de l'écran doit être
rapproché des théories de la gestalt selon lesquelles le
tout est plus que la somme des parties. Face à ensemble de stimuli, nous
percevons certains 'patterns' de préférence à d'autres.
Certains de ces biais semblent universels. Le plus connu d'entre eux est le
principe de symétrie, qui réfère notre
préférence vers la décomposition des images en
éléments symétriques. Anderson (1980) cite d'autres
principes:
- Principe de proximité. Les éléments proches
sont associés en unités: dans la Figure 2.5 nous percevons cinq
colonnes de points et non cinq lignes, car l'espace vertical entre deux points
est inférieur à leur espacement horizontal.

Figure 3.
5 : Effet de proximité (selon Anderson, 1980)
- Principe de similarité. Les objets qui se ressemblent ont
tendance à être associés: dans la Figure 2.6, bien que les
espacements soient identiques à ceux de la Figure 2.5, nous percevons
une alternance de lignes homogènes de points et de lignes
homogènes de croix, plutôt que les colonnes composées de
points et de croix.
Figure 3.
6 : Effet de similarité (selon Anderson, 1980)
Ces principes décrivent des biais universels de la perception.
L'utilisateur est aussi sujet à des biais individuels. En particulier,
notre perception est influencée par ce que nous nous attendons
à voir. Ce biais est individuel car il dépend des
connaissances préalables de l'utilisateur et du contexte dans lequel il
utilise le logiciel. Il est particulièrement important dans la lecture:
nous anticipons systématiquement les mots qui suivent ceux que nous
lisons. Par conséquent, lorsqu'il existe un mode conventionnel de
présentation des données (sur support papier), par exemple la
structure des adresses, il est préférable d'utiliser ce mode
(Tullis, 1988). Selon Anderson (1980), l'identification de patterns familiers
demande moins d'attention. Lorsqu'il n'y a pas de pattern familier, les sujets
doivent consacrer une partie de leur attention à assembler les
éléments en un tout interprétable.
Le concepteur de logiciel interactifs peut exploiter ce biais perceptif en
induisant lui-même les attentes de l'utilisateur. En créant des
invariants dans la présentation des informations, l'auteur
favorisera l'induction de patterns visuels qui accéléreront
l'interprétation des écrans ultérieurs. Si l'auteur prend
la précaution d'afficher systématiquement le même type
d'informations au même endroit, l'utilisateur pourra construire des
automatismes lui permettant de fixer directement le point de l'écran
où se trouve l'information recherchée. C'est un principe
général en psychologie: la création d'automatismes permet
de réduire les ressources attentionnelles nécessaires.
L'efficacité de la structure d'écran dépend
également de la tâche, notamment de l'ordre dans lequel le sujet
doit traiter les informations présentées. Cet ordre
détermine le trajet de l'oeil de l'utilisateur.
- Le sujet a plus de chances de percevoir un élément nouveau
si celui-ci se trouve dans son champ visuel. L'angle de perception visuelle
fine est de 2.5 degrés, celui de perception périphérique
est de 60 degrés (Wickens, 1987). Il est important de minimiser la
distance que doit parcourir l'oeil entre différent points de lecture
(Wickens, 1987). C'est sur ce principe que repose la conception d'un cockpit.
Malheureusement, comme c'est souvent la cas dans ce domaine, le principe
inverse est également vrai: la proximité de plusieurs
informations visuelles peut également avoir un effet distracteur
(Wickens, 1987).
- Corollaire du principe précédent, les informations
utilisées fréquemment devraient être regroupées
(Tullis, 1988).
- Si les informations doivent être traitées dans un ordre
prévisible (par exemple, prix total - rabais - taxes - prix réel)
, il est préférable de les disposer dans cet ordre, afin de
minimiser le trajet de l'oeil entre deux informations qui doivent être
traitées consécutivement. L'ordre de disposition des
éléments devrait respecter les habitudes de lecture de
l'utilisateur, à savoir, dans notre culture, du haut vers le bas et de
gauche à droite.
- Si les informations concernent un processus qui possède une
dimension spatiale, il peut être intéressant que la disposition
géographique des données mette en évidence leur origine
(Tullis, 1988): par exemple, des mesures effectuées sur un moteur
complexe seront affichées sur un schéma de ce moteur, à
l'endroit où elles ont été prélevées, les
données provenant de divers points du territoire seront
positionnées par rapport à leur origine
géographique,....
Ces principes peuvent sembler contradictoires.
Imaginons par exemple que le plan d'une maison soit affiché à
l'écran. L'utilisateur peut cliquer sur un objet (un mur, une porte,...)
pour en connaître les dimensions. Afin de minimiser les écarts
visuels, ces dimensions devraient être affichées le plus
près possible de l'objet auquel elles réfèrent. Par
contre, si le concepteur désire créer des invariants dans la
présentation, il devrait au contraire afficher systématiquement
les dimensions au même endroit, par exemple, en bas de la fenêtre.
Cette contradiction peut être surmontée en définissant des
invariants 'relatifs' de présentation, par exemple 'les dimensions sont
toujours affichées immédiatement sous l'objet mesuré".
2.5 Activité de l'utilisateur
Parmi les défauts fréquents dans la conception de logiciels, en
particulier des logiciels éducatifs, on trouve l'illusion qu'une
information présentée à l'écran sera
intégrée par l'utilisateur. Or, lorsqu'une information est
présentée, au moins quatre étapes restent à
franchir avant d'aboutir à son intégration.
1) Le sujet peut ne pas avoir le temps de percevoir l'information. Cet accident
arrive fréquemment dans les logiciels qui offrent à l'utilisateur
un temps limité pour lire une information. Même si ce temps est
prévu avec une grande marge de sécurité, il n'est pas
impossible que le sujet soit à ce moment précis distrait par un
événement externe, désire penser au problème ou
vérifier une information. Le logiciel n'est qu'un des
éléments de l'environnement de l'utilisateur. La seule
façon de s'assurer que le sujet ait le temps de lire l'information est
de lui demander de signaler qu'il a fini de lire (bouton).
2) Si le sujet presse le bouton 'continue', cela n'implique pas
nécessairement qu'il ait lu l'information. Nous pressons
régulièrement ce bouton sans lire le contenu de l'écran,
par exemple lorsqu'un logiciel nous force à passer à travers un
série d'écrans que nous connaissons déjà. Certains
novices font la même chose par inadvertance, par exemple, ils ont
poussent deux fois 'continue' parce que le système n'a pas
répondu assez rapidement au premier signal. La seule façon de
s'assurer que le sujet ait lu l'information (texte, graphique, image,...) est
de le soumettre à une activité telle qu'il ne puisse
répondre qu'au moyen de l'information présentée.
3) Admettons que le sujet lise l'information, cela n'implique pas qu'il l'ait
comprise. Il peut la comprendre superficiellement, c'est-à-dire en
comprendre chaque mot, sans en comprendre la pertinence par rapport à la
tâche. La seule façon de s'assurer que le sujet comprenne
l'information, c'est de lui proposer une activité qu'il ne peut
réussir qu'en utilisant correctement l'information
présentée.
4) Enfin une information, même comprise, n'est pas nécessairement
intégrée dans les structures cognitives du sujet. D'une parte,
l'intégration repose sur l'activité du sujet, plus
précisément sur la manière dont le sujet va traiter cette
information. C'est au cours de cet traitement que le sujet doit créer
les liens entre la nouvelle information et d'autres informations
déjà en mémoire D'autre part, la mémoire à
long terme étant organisée sémantiquement, les
informations importantes doivent permettre un traitement sémantique
(Thomson, 1984). On choisira par exemple des icônes dont le graphisme
évoque la fonction associée plutôt que des icônes
abstraites, arbitrairement associées à une fonction. Notons que
les systèmes d'hypertextes que nous étudierons dans le module 10
reposent sur les théories relatives à l'organisation de notre
mémoire à long terme (réseaux sémantiques).
Nous n'affirmons pas que toute information présentée dans
l'interaction doive faire l'objet de ces quatre étapes. Nous attirons
simplement l'attention du concepteur sur le fait qu'il ne peut supposer a
priori que l'information présentée au sujet traversera avec
succès les étapes qui conduisent à son intégration.
Ce n'est pas impossible, mais ce n'est en aucune manière garanti. Si le
concepteur considère qu'une information particulière est
importante et doit être assimilée par l'utilisateur, il faut que
celle-ci fasse l'objet d'une activité plus complexe que de presser
simplement le bouton "continue". L'activité permettant de traiter
l'information constitue à la fois le processus qui permet à
l'utilisateur d'intégrer l'information et le procédé qui
permet au système de vérifier si l'information a
été correctement assimilée. Cette remarque est
très importante car il n'est pas rare de trouver des logiciels
éducatifs qui se réduisent à une séquence
d'écrans de présentation d'informations. L'activité du
sujet se limite à tourner les pages. Aujourd'hui encore, certains
logiciels peuvent être caractérisés de simples
'tourne-page', même si le choix de la page est un peu plus complexe. Dans
la plupart des hypertextes, l'activité du sujet se limite à lire
les textes, l'activité de 'tourner la page' prenant dans une structure
non-linéaire le nom plus élégant de 'navigation'. De
même, dans de nombreux logiciels multimédia, l'activité du
sujet se limite à sélectionner la séquence qu'il
désire visionner, il ne fait que 'zapper'.
L'idée de livre électronique n'est pas a rejeter pour autant,
mais à adapter aux avantages et inconvénients de l'informatique.
Il faut se souvenir qu'il est plus facile de lire un texte imprimé qu'un
texte présenté à l'écran. En outre, le lecteur d'un
livre dispose de certaines options qui ne sont pas toujours offertes par les
logiciels électroniques: souligner un passage important, revenir en
arrière, estimer où il se trouve dans le récit (en
regardant l'épaisseur du livre), sauter au Nième chapitre,...
L'intérêt des livres électroniques réside surtout
dans l'intégration des activités de lecture à d'autres
activités: par exemple, accéder à un traité de
langue française en rédigeant un document, en entrant directement
à un niveau pertinent par rapport au problème de grammaire
rencontré.
2.6 Charge de travail mental
Certains chercheurs, plutôt que de définir la quantité
d'information présente à l'écran, ont tenté
d'obtenir une estimation quantitative de l'activité de l'utilisateur. Le
concept de charge de travail mental ('mental workload') fut utilisé
dès les années soixante par les ergonomes chargés
d'évaluer des interfaces complexes tels qu'un cockpit d'avion ou le
tableau de commandes d'une centrale nucléaire. Ce concept répond
à des besoins très pragmatiques, par exemple savoir si un pilote
commet davantage d'erreurs de lecture des indicateurs de vol lorsqu'il est en
même temps en communication radiophonique avec la tour de contrôle.
Le concept de charge mentale recouvre une variété de facteurs
psychologiques (stress, motivation, attention, ...). Il est en particulier
lié aux limitations de capacité et de traitement de la
mémoire de travail. Il est difficile de traduire les travaux sur la
charge mentale en termes de spécifications relatives au design de
systèmes parce que ces travaux ont été davantage
orientés vers l'évaluation de dispositifs que vers leur
conception. Les chercheurs se sont intéressés aux mesures de la
charge mentale (Hancock & Meshkati,1988), davantage qu'à sa
définition théorique. On distingue trois types de mesures de la
charge mentale:
2.6.1 Les mesures de performance
Les mesures de performance sont généralement liées
à une estimation du niveau d'exigence de la tâche. La figure 2.6
permet de définir la notion de surcharge mentale. On demande au sujet de
réaliser une tâche qu'il maîtrise bien (point a sur la
figure 2.6), et on augmente progressivement les exigences de cette tâche
(par exemple, accroître le taux d'information à traiter) (point
b). Pendant la première phase (a -> b), l'augmentation de la
difficulté de la tâche n'affecte pas les performances du sujet,
mesurées par le taux d'erreurs ou le temps de réponse. Par
contre, au-delà d'un certain seuil, tout accroissement de la
difficulté de la tâche affecte immédiatement les
performances du sujet. La différence de difficulté entre c et d
se reflète sur les performances, alors que ce n'était pas le cas
entre a et b, pourtant espacés par le même intervalle. Cette
détérioration des performances est considérée comme
la manifestation du dépassement de la charge maximale de travail, ou, en
d'autres termes, comme l'effet d'une surcharge. La notion de la charge mentale
est liée à l'estimation de la marge d'accroissement de la
difficulté de la tâche au-delà de laquelle les performances
du sujet diminuent (Kantowitz, 1987; Jex, 1988; Eggemeier, 1988). Il s'agit
donc d'une définition 'en négatif' des capacités du sujet.
Cette définition peut être comparée à celle du sujet
qui évaluerait sa taille non en regardant ses pieds, mais en
considérant l'espace qui lui reste au-dessus de la tête lorsqu'il
franchit une porte. Nous reviendrons ultérieurement à ces mesures.
2.6.2 Les mesures physiologiques
Les mesures physiologiques utilisées pour mesurer la charge cognitive
concernent diverses mesures d'activité cérébrale
(potentiels évoqués), de fréquence cardiaque, de
mouvements oculaires, de clignement des paupières, et de contraction
musculaire (Wilson & O'Donnell, 1988).
2.6.3 Les mesures subjectives
Les mesures subjectives consistent à demander au sujet
d'auto-évaluer sa charge cognitive. Hart & Staveland (1988)
décrivent différents types de questions utilisées par la
NASA pour mettre en oeuvre cette auto-évaluation:
- Exigences mentales. Les activités mentales (penser,
décider, calculer, se souvenir, chercher,...) étaient-elles
simples, complexes, fatigantes,... ?
- Exigences physiques. Les activités physiques
étaient-elles intenses, harassantes, laborieuses,...?
- Exigences temporelles. Avez-vous ressenti une forte pression
liée au rythme auquel les données étaient
présentées ou auquel les événements se produisaient?
- Performance. Pensez-vous que vous avez été efficace,
êtes-vous satisfait de vos performances, avez-vous atteint les/vos buts?
- Effort. Dans quelle mesure avez-vous eu à travailler dur
pour atteindre ces performances?
- Frustration. En réalisant cette tâche, vous
êtes-vous sentis insécurisés, découragés,
irrités, stressés, ennuyés... ou plutôt
sécurisés, gratifiés, contents et détendus?

Figure 3.7: En situation de surcharge cognitive, toute augmentation de
la difficulté de la tâche conduit à une
détérioration des performances. (Adapté de Eggemeier,
1988)
Au sein des travaux relatifs à la mesure de la charge mentale, deux
éléments sont pertinents pour les concepteurs de logiciels
interactifs. Le premier élément concerne la relation entre les
différentes mesures, plus précisément le fait que les
mesures subjectives (auto-évaluation) sont fortement
corrélées avec les mesures objectives (performances) (Miller and
Hart, 1984, cités part Meshkati & Lowenthal, 1988; Reid &
Nygren, 1988). Si les sujets sont capables d'auto-estimer de façon
relativement fiable leur charge mentale, il ne serait pas inutile
d'intégrer cette information dans nos systèmes. L'auteur peut par
exemple donner à l'utilisateur la possibilité de modifier
directement le système en réglant certains paramètres, par
exemple la vitesse de présentation des informations ou le nombre
d'informations présentées simultanément.
Nous reviendrons sur ces diverses formes d'adaptation dans le module 8.
Wierwille (1988) indique cependant que les sujets de ses expériences
expriment souvent le besoin de baser leur jugement sur un compte-rendu de leurs
performances. En d'autres termes, le concepteur doit garder à l'esprit
que la qualité de l'auto-évaluation sera fortement
influencée par la précision des feed-back concernant les
performances de l'utilisateur.
Le second point intéressant dans ces études réside dans le
fait que, pour amener le sujet à franchir le seuil de surcharge
cognitive, les expérimentateurs demandent généralement au
sujet de réaliser une deuxième tâche, simultanément
à la première. Par exemple, ils leur demande de compter à
rebours tout en dessinant des formes géométriques sur
l'écran. Or, l'utilisateur d'un logiciel informatique, réalise en
général aux moins deux activités simultanées: la
tâche elle-même et l'utilisation du logiciel. Par exemple,
l'utilisateur d'un traitement de texte doit à la fois penser à la
rédaction du texte (comme il le ferait s'il écrivait sur papier)
et gérer les outils offerts par le logiciel. Certes, l'objectif d'un
concepteur de logiciels est de rendre son logiciel 'transparent',
c'est-à-dire de permettre à l'utilisateur de concentrer sur la
tâche, sans se soucier du logiciel. Cet idéal est cependant
rarement atteint, l'utilisateur ayant à traduire ses intentions en
termes de commandes offertes par le logiciel.
Certains auteurs proposent l'idée que nous disposons de multiples
processeurs, relativement indépendants les uns des autres, et qui
possèdent chacun des capacités limitées (Wickens, 1987;
Eggemeier, 1988). Il serait donc possible d'être en surcharge pour un
aspect de la tâche et de disposer de ressources cognitives pour un autre
aspect. Selon cette théorie, l'utilisateur pourrait traiter
simultanément des stimuli visuels et sonores, ou produire des
comportements sonores et moteurs (chanter en frappant un rythme), car ceux-ci
font appel à des registres différents. Par contre, il serait
moins efficace de coordonner deux comportements moteurs (frapper des rythmes
différents avec chaque main). Pour Eggemeier (1988), les sujets seraient
capables de traiter en parallèle des stimuli visuels et auditifs
(input), des informations spatiales et symboliques (raisonnement) et des actes
manuels et vocaux (output). Si l'évolution actuelle des sciences
cognitives confirme l'existence de processus multiples, il n'est pas clair
qu'elle aboutisse à l'identification des mêmes composantes. Le
débat concerne notamment la définition des catégories de
stimuli prises en charge par un même processeur ou un même
sous-système cognitif. Par exemple, tous les stimuli visuels ne sont pas
traités de la même manière. La répartition des
ressources serait moins liée à la nature des inputs qu'au type de
traitement de ces stimuli. Il ne nous est pas possible d'entamer ici un
débat sur l'architecture cognitive de l'homme. Le concepteur retiendra
le principe selon lequel deux tâches qui mettent en oeuvre une même
fonction cognitive rentrent en concurrence pour l'allocation des ressources
propres à cette fonction.
Ce principe général doit cependant - une fois de plus -
être nuancé. En effet, si deux sous-tâches partagent
certaines caractéristiques fonctionnelles, l'utilisateur peut
économiser la partie redondante du traitement (Wickens, 1987). Par
exemple, si deux graphes juxtaposés utilisent la même
légende, l'utilisateur ne doit interpréter qu'une courbe et peut
comprendre la seconde directement par rapport à la première. En
outre, l'exécution de tâches parallèles semble meilleure si
les deux éléments à traiter sont intégrés au
sein d'un objet d'ordre supérieur, en particulier si la tâche
implique une comparaison entre les composantes (Wickens, 1987).
Une autre façon de réduire la charge mentale imposée par
une tâche multiple consiste à automatiser certaines
sous-tâches. Lorsqu'une tâche est bien automatisée, elle
requiert des ressources limitées. On peut alors ajouter une autre
tâche sans grande détérioration des performances (Fisk,
Ackerman & Schneider, 1987). Nous sommes par exemple capables de conduire,
de sortir notre carte de parking tout en continuant la conversation avec le
passager. L'exercice répété d'une même tâche
permet son automatisation. Nous avons précédemment utilisé
l'exemple de l'utilisateur du traitement de texte qui réalise en
parallèle deux tâches, exprimer ses idées et utiliser le
logiciel. Il est probable que lorsque cet utilisateur aura totalement
automatisé l'utilisation du système, celle-ci ne
représentera plus qu'une charge minimale. Le système deviendra
'transparent'. L'utilisateur pourra consacrer toutes ses ressources à la
rédaction.
Certes, la pratique intensive d'une démarche ne donne pas toujours lieu
à une automatisation. L'automatisation repose sur l'induction
d'invariants entre les situations rencontrées à travers un
même programme. Elle dépend donc du degré de
cohérence entre les situations. Si les conventions changent au cours
de l'interaction, l'utilisateur ne peut induire d'invariants puisque ceux-ci
n'existent pas. Nous verrons dans le module 6 que la cohérence est la
qualité primordiale d'un langage d'interaction. Toutefois, l'inverse de
ce principe possède également une certaine vérité:
il arrive que l'exercice répété d'une compétence
conduise à décroître les performances, effet dû
à la lassitude (Fisk, Ackerman & Schneider, 1987). Signalons enfin
que la question de l'automatisation prend une dimension particulière
dans l'interaction personne-machine: si l'utilisateur peut automatiser une
activité, pourquoi le système ne pourrait-il prendre cette
activité en charge? Cette question doit être
considérée sérieusement au moment de partager les
tâches entre le système et l'utilisateur.
2.7 Affichage et effacement dans Authorware
La présentation d'informations dans Authorware repose essentiellement
sur deux icônes: l'icône de présentation et l'icône
d'effacement. La première a été présentée
dans le module précédent. L'affichage et l'effacement reposent
sur des principes relativement simples. Le contenu d'une icône de
présentation s'affiche en superposition de ce qui se trouve
déjà à l'écran au moment où cette
icône est exécutée. Si les objets de cette icône sont
opaques, ils cachent ceux qui se trouvaient affichés
préalablement au même endroit. Si les objets de l'icône sont
transparents, l'utilisateur verra ce qui se trouvait préalablement
à l'écran à travers les parties blanches du nouvel objet
affiché. Le réglage de l'affichage en mode opaque ou transparent
doit être réalisé pour chaque objet ou groupe d'objets, au
moyen de l'item 'modes' du menu 'Attributes' (ce menu peut-être
détaché sous forme de palette).
Le contenu d'une icône de présentation reste affiché
jusqu'au moment ou l'auteur demande son effacement. Il existe deux
manières d'effacer de l'information:
- L'auteur place l'icône d'effacement dans le programme
à l'endroit correspondant au moment désiré de
l'effacement. Pour indiquer quelle icône doit être effacée,
l'auteur clique sur un objet appartenant à l'icône dont le contenu
sera entièrement effacé. Il n'est pas possible d'effacer une
partie du contenu de l'icône (voir module 1). C'est l'ensemble des
éléments de cette icône ou rien! Si l'auteur veut effacer
des données en plusieurs fois, il devra répartir celles-ci en
plusieurs icônes de présentation.
- Les icônes qui contrôlent un processus itératif offrent
une gestion automatisée des effacements. L'icône
d'interaction dispose d'un paramètre permettant de préciser si la
question doit être effacée après chaque réponse
(puis réaffichée), ou à la fin de l'interaction, ou ne
doit pas être effacée. Les mêmes possibilités
existent pour les boucles créées au moyen de l'icône de
décision. Les dialogues d'édition de réponses demandent
à l'auteur si le feed-back doit être effacé avant la
réponse suivante, après cette réponse, à la fin de
l'interaction ou ne doit pas être effacé.
L'auteur peut en
général choisir un effet d'effacement: effacement simple,
affaiblissement progressif, effet de zoom, ... Il en va de ces effets
d'effacement comme des procédés d'emphase visuelle: ils n'ont
d'effet que s'ils sont utilisés avec parcimonie et cohérence.
Lorsqu'on utilise l'icône d'effacement, le temps de présentation
de l'information dépend des icônes qui se trouvent entre
l'apparition d'une information et l'icône d'effacement. Dans cet
intervalle, l'auteur placera au minimum une icône d'attente: celle-ci
interrompt l'exécution du déroulement du programme. La
durée de l'interruption dépend des options choisies par l'auteur.
- Interruption pendant un nombre de secondes spécifié par
l'auteur. Le compte à rebours pouvant être visualisé
à l'écran sous forme d'un petit réveil (mais celui-ci peut
distraire l'utilisateur).
- Interruption jusqu'au moment où l'utilisateur presse une touche
quelconque ou un bouton du type "continue". Le texte de ce bouton est constant
à travers un programme. Il peut être modifié dans les
options offertes par le menu 'file setup'.
Le premier mode d'interruption
(durée spécifique) sera réservé aux cas où
l'information présentée est très simple ou peu importante.
Lorsqu'il s'agit d'une information complexe, il est indispensable de laisser le
sujet le temps nécessaire pour en prendre connaissance.
Authorware dispose des procédés d'emphase visuelle classiques
(taille, style, couleur,...). Il ne dispose pas de procédure de
sur-brillance, ni de clignotement. Le clignotement peut cependant être
réalisé au moyen de l'icône de décision (voir module
7), en créant une boucle qui affiche et efface le même item.
Nous avons insisté sur la création d'invariants dans la
disposition des éléments à l'écran. Pour les
construire, l'auteur peut trouver utile d'inclure une grille d'écran,
telle qu'elle existe dans de nombreux logiciels de dessin. Authorware n'en
dispose malheureusement pas. Une solution consiste à dessiner cette
grille dans une icône de présentation insérée en
début de programme. Il peut s'agir d'une simple grille composée
de traits horizontaux et verticaux ou d'un 'patron' spécifique tel que
celui-ci illustré par la figure 2.7. Celle-ci apparaîtra par
transparence sous les écrans suivants et permettra de positionner les
éléments de façon précise. Lorsque le logiciel sera
prêt, il suffit alors de supprimer l'icône comportant cette grille.
Il est également possible de standardiser l'agencement des zones de
réponse en spécifiant leur position au moyen de nombres au lieu
de positionner les zones avec la souris. Cette possibilité est offerte
par le bouton 'Position et Size' dans le dialogue d'édition d'une
réponse. Il est en est de même pour le feed-back: tout objet
graphique (texte ou dessin) peut être positionné par des variables
('calculate initial position' dans l'item 'effects' du menu 'Attributes').
Figure 3.8 : Patron permettant à l'auteur de disposer les informations
selon une structure cohérente toute au long de l'interaction (ces zones
ne sont pas nécessairement visibles par l'utilisateur).
3. Modes d'interaction.
L'objectif de ce module est de pouvoir utiliser les différents modes
d'interaction offerts par Authorware. Cette utilisation exige de comprendre
d'une part, ce qui est commun à toute interaction, quel qu'en soit le
mode, et, d'autre part, ce qui lui est spécifique. Ce module vise en
particulier à attirer l'attention sur des éléments de
l'interaction qui ne sont généralement pas perçus, par
exemple le fait qu'un bouton change momentanément de couleur lorsqu'on
clique dessus. Ces signaux influencent fortement le bon fonctionnement de
l'interaction.
3.1 Exploration
L'activité proposée consiste à tester les
différentes versions du programme 'Cash Machine' qui se trouvent dans le
module 3. Ces variantes proposent toutes la même question: l'utilisateur
doit préciser s'il désire prélever de l'argent sur son
compte courant ou sur son compte d'épargne. Les 6 variantes proposent
divers types de réponse pour le sujet: introduire sa réponse au
clavier, cliquer sur un bouton ou un autre symbole graphique, déplacer
un objet,...
Bien que les activités du sujet varient d'une version à l'autre,
la structure de ces six programmes est rigoureusement identique. Authorware
représente d'une part la structure de l'interaction par un organigramme
et, d'autre part, le ou les modes d'interaction par des symboles
spécifiques greffés sur l'organigramme.
3.2 Types de réponses
Nous considérons sept types de réponse:
1) en pressant un 'bouton' (type 'button');
2) en cliquant dans une zone sensible (type 'click/touch');
3) en cliquant sur un objet sensible (type 'clickable object');
4) en déplaçant un objet (type 'movable object');
5) en introduisant plusieurs caractères au clavier (type 'text');
6) en pressant une touche (type 'keypress');
7) en sélectionnant un item dans un menu déroulant (type
'pull-down menu').
Il s'agit des types de réponse offerts par Authorware, mais il sont,
pour la plupart, également disponibles ou programmables dans d'autres
langages. Authorware propose en outre trois autres types de réponse
('conditional','time limit' et 'tries limit'). Ceux-ci ne constituent cependant
pas des modes de réponse à proprement parler, mais des tests
complémentaires qui peuvent être intégrés dans
l'analyse de la réponse. Nous y reviendrons dans le module 5.
Les types de réponse 'zone sensible' (2) et 'objet sensible' (3) sont
très semblables du point de vue de l'utilisateur. Une 'zone' sensible
permet de définir comme classe de réponses tout point
sélectionné dans un zone rectangulaire de l'écran. La zone
en elle-même n'est pas visible pour l'utilisateur. La figure 3.1.a
illustre la pertinence du mode 'zone sensible': le sujet peut cliquer dans une
zone qui ne correspond pas à un objet précis. La figure 3.1.b.
illustre une limitation du mode 'zone sensible': les zones étant
rectangulaires, la zone incluant le segment B et celle qui inclut le segment C
se superposent. Dans ce cas, si le sujet clique dans l'intersection des zones B
et C, l'auteur ne peut déterminer si le sujet a répondu B ou C.
Le type de réponse 'objet sensible' permet de définir comme
classe de réponse tout point sélectionné à
l'intérieur d'un objet, ce qui permet de résoudre le
problème illustré par la figure 3.1b. Un autre avantage des
objets sensibles est que ceux-ci peuvent être en mouvement, option
particulièrement intéressante pour les jeux.
La sélection d'un objet dont la largeur n'est que d'un pixel demande une
certaine dextérité. Pour éviter les problèmes qui
en résultent, il faut soit définir des objets plus larges, soit
dessiner derrière l'objet visible un objet sensible plus large et
invisible par l'utilisateur (par exemple, un rectangle blanc sur fond blanc).
Cette technique est possible parce que ce que Authorware fonctionne pendant
l'exécution en mode 'calque'. Tous les objets appartenant à une
même icône constituent un seul objet sensible. Aussi, pour
réaliser l'exemple de la figure 3.1.b au moyen d'objets sensibles, les
objets B et C doivent être créés et affichés dans
des icônes de présentation distinctes. Si la lettre B appartient
à la même icône que le segment B, elles fera donc partie de
l'objet sensible. Ce principe est valable également pour le mode de
réponse 'déplacement d'objet' et pour le déplacement
d'objets au moyen de l'icône d'animation (voir module 9).
Figure 4.1: (a) A gauche: Utilisation pertinente du mode 'zone sensible'(b) A
droite: Utilisation inadéquate du mode 'zone sensible' (Les zones de
réponse représentées en pointillé ne sont en
réalité pas visibles par l'utilisateur).
3.3 Structure d'une interaction
Ce module concerne la structure interne des interactions. La manière
dont plusieurs dialogues s'enchaînent et déterminent la structure
d'un logiciel sera analysée dans le module 7. Grosso modo, une
interaction comprend une question du système, la réponse de
l'utilisateur et les feed-back produits par le système.
Néanmoins, en regardant de plus près, une interaction peut se
décomposer en six étapes:
1) La présentation d'un déclencheur d'activité. Un
déclencheur ou stimulus recouvre non seulement les questions prises au
sens pédagogique du terme, mais également tout
événement qui déclenche une activité de
l'utilisateur, par exemple l'apparition d'un ennemi dans un jeu ou la
présence d'un menu dans la barre de menus.
2) L'élaboration et l'émission d'une réponse par
l'utilisateur. Le terme 'réponse' recouvre non seulement les
réponses à une question de nature pédagogique, mais
également des activités telles que construire un objet, choisir
un item de menu, ou encore poser une question. Le sujet construit sa
réponse, la modifie éventuellement, jusqu'au moment où il
réalise un acte particulier défini comme signal
d'émission.
3) La réception d'une réponse par le système. Le
logiciel doit 'accepter' la réponse introduite par le sujet. Ceci
implique dans certains cas une suspension du déroulement du programme
jusqu'au moment où l'utilisateur produit un signal d'émission.
L'utilisateur est généralement informé de la bonne
réception de sa réponse par la machine grâce à un
signal de réception.
4) L'analyse de réponse. Le processus d'analyse de réponse
est souvent réalisé par une séquence de tests permettant
d'identifier à quelle classe de réponse appartient la
réponse de l'utilisateur. Une classe peut être définie en
extension: "5 ou -5". Une classe peut bien sûr ne contenir qu'une seule
réponse. Une classe peut aussi être définie en
compréhension: par rapport à une réponse-type (par
exemple, la réponse 'hydrogène' et ses variations orthographiques
raisonnables), au moyen des critères numériques (p.ex.,
l'ensemble des nombres entiers pour un distributeur de billets) ou de
critères plus complexes (l'ensemble des dates plausibles dans un
logiciel de réservation). La succession des tests qui permettent
d'identifier la classe à laquelle appartient une réponse doit
respecter une logique précise décrite ci-après.
5) L'association d'un feed-back à chaque classe de
réponses. Le terme feed-back recouvre non seulement des messages de type
"C'est juste", mais également toute autre activité
sélectionnée par le système sur base de la classe de
réponses identifiée: par exemple, poser une sous-question,
choisir une chapitre, imprimer un document, effacer un fichier,...
6) L'association d'un branchement à chaque classe de
réponses. Le branchement détermine à quel point sera
reprise l'exécution du programme après le feed-back. Dans un
didacticiel, les branchements les plus fréquents consistent à
reposer la question ou à passer à la question suivante.
Nous reprenons chacune de ces étapes par la suite. La figure 3.2.
présente un algorithme qui décrit la structure d'une interaction.
Comme dans tout algorithme, les tests sont généralement
représentés par des formes proches du losange. Cette structure
est - à quelques différences près - utilisée par
Authorware pour décrire un logiciel. La figure 3.3, très proche
de la représentation d'une interaction dans Authorware, résulte
d'une rotation de la figure 3.2. Une caractéristique intéressante
d'Authorware est que la structure de l'interaction est indépendante
du type de réponse. Cette abstraction est liée au fait que
les formes de branchement proposées sont identiques quel que soit le
mode de réponse. Or ce sont ces formes de branchement qui
déterminent la structure de l'algorithme.
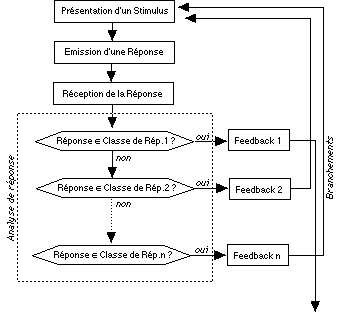
Figure 4.2 : Structure d'une interaction
Cette organisation des interactions pourrait laisser penser que Authorware est
limité à la réalisation de séquences de questions
et de réponses. Certes, Authorware privilégie les programmes de
structure linéaire ou en arbre. Ce biais n'est pas anodin car il
renforce la tendance naturelle de certains concepteurs à reproduire des
structures existantes sur d'autres médias, majoritairement
linéaires. Toutefois, ce langage dispose d'un concept qui lui donne une
grande souplesse: les réponses permanentes. L'auteur peut par exemple
créer un bouton 'permanent' (en sélectionnant l'option
'perpetual' dans le dialogue de spécification du bouton). Celui-ci reste
visible et activable tant que le programme ne le désactive pas
explicitement. Si un bouton est activable en permanence, il permet à
l'utilisateur de sortir de la structure prédéterminée de
l'interaction et même de la séquence d'interactions. Il permet
donc à l'utilisateur de s'échapper du scénario
linéaire et au concepteur de créer des situations plus ouvertes.
Il rapproche en cela Authorware de langages de programmation moins contraignant
au niveau de la structure.
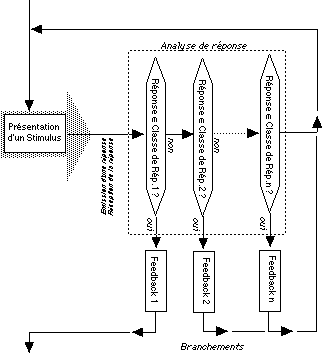
Figure 4.3 : Transformation de l'algorithme 3.2 'à la Authorware'
Parmi les sept types de réponse décrits, seuls les types 'texte'
et 'touche' ne peuvent être permanents. Les réponses de type 'item
de menu' sont généralement des réponses permanentes. Un
logiciel de dessin peut être analysé comme un certain nombre de
questions permanentes et d'interactions locales. Les palettes constituent par
exemples des questions permanentes implicites qui invitent l'utilisateur
à sélectionner un outil de dessin (réponse 'zone
sensible'). Si l'utilisateur répond en sélectionnant l'outil
'droite', il entre dans une interaction en deux phases: il clique une
première fois pour poser un point, puis une seconde fois pour
désigner le second point définissant la droite. Nous reviendrons
sur les réponses permanentes dans le module 7.
3.3.1 Déclencher l'activité de l'utilisateur
Dans Authorware, la présentation du stimulus est réalisée
au moyen de l'icône 'interaction'. La question est dessinée telle
qu'elle apparaîtra à l'utilisateur, au moyen des mêmes
outils que l'icône de présentation. Elle comporte trois types
informations:
1) le stimulus proprement dit, c'est-à-dire
l'élément qui déclenche l'activité du sujet: la
question, la modification de l'icône qui signale la présence de
courrier,...
2) une information concernant le mode de réponse: le sujet
doit-il répondre en cliquant sur un objet, en déplaçant un
objet, en entrant un texte au clavier,...?
3) une information concernant les réponses possibles: soit la
liste des réponses possibles dans le cas de questions fermées,
soit les contraintes quant à l'expression de réponses ouvertes
(p.ex. longueur maximale).
Les catégories b et c ont un caractère différent de la
première. La première, le stimulus proprement dit, concerne le
contenu de l'activité du sujet, alors que les deux autres
définissent en quelque sorte un contrat d'interaction. Cet aspect
'méta-communicatif' existe également dans un dialogue naturel.
Par exemple, dans la question "Peux-tu m'envoyer une note qui résume les
tendances du marché", la question porte sur les tendances du
marché, mais il est précisé en outre que le mode de
réponse doit être de type 'note', c'est-à-dire écrit
et succinct. Dans l'interaction personne-machine, il faut être attentif
à ces aspects méta-communicatifs:
- Les informations sur l'interaction sont le plus souvent implicites. Par
exemple, si l'utilisateur voit trois boutons, il peut en déduire que le
mode de réponse attendu est 'cliquer sur un bouton' et que les
réponses possibles sont les trois boutons.
- Si cette information est absente ou trop implicite, elle doit être
explicitée: "Cliquez sur le symbole qui représente ...",
"Répondez par OUI ou NON",...
- Si ces informations sont relativement stables au cours d'une
séquence d'interactions, elles peuvent être
précisées une fois pour toutes au début de cette
séquence.
- Si le stimulus proprement dit occupe tout l'espace disponible, ces
informations sur le mode d'interaction peuvent être
présentées dans un écran distinct, pour autant qu'elles
puissent facilement être mémorisées.
- Si ces informations sont complexes, elles peuvent être
présentées au début de l'interaction et rester accessibles
pendant l'interaction (par exemple au moyen d'un bouton 'Rappel des
consignes').
Pour chaque type de réponse, Authorware permet de
régler certains paramètres qui influencent l'information dont
dispose le sujet à propos de l'interaction:
1) Réponses de type 'bouton' et 'menu'. La présence des
boutons et des menus à l'écran indique intuitivement à
l'utilisateur comment il doit répondre et quelles sont les
réponses possibles. Certains boutons ou items de menu peuvent être
désactivés (option 'active if true' dans le dialogue de
définition d'une réponse). Ils apparaissent alors en gris. Dans
le cas des boutons, l'auteur peut choisir de le rendre invisible. La
différence entre un bouton gris ou invisible n'est pas anecdotique.
Lorsque le bouton est affiché en gris, l'utilisateur perçoit
toujours la structure de l'interaction, bien que certains items soient
simplement désactivés. Il mémorise la position des
commandes dans les menus même lorsque celles-ci sont inactives. Par
contre, si le bouton est invisible, il y a moins de chances que l'utilisateur
perçoive ces invariants. Dans le premier cas, la notion
d'activation/désactivation est explicite; dans le second cas, elle est
implicite et risque donc de surprendre certains utilisateurs.
2) Réponses de type 'zone sensible' et 'objet sensible'. Le
concepteur peut changer la forme du curseur lorsque celui-ci passe sur
une zone ou un objet sensible. Le curseur de substitution est choisi parmi une
petite librairie de curseurs disponibles sur le système utilisé
(Mac ou Windows). Cette librairie peut être enrichie par le concepteur
qui désire créer des formes de curseur très
spécifiques (par exemple, des instruments particuliers). En parcourant
l'écran avec la souris, l'utilisateur détecte les réponses
possibles à chaque changement de forme du curseur. Les réponses
de type 'zone sensible' disposent d'une option 'mark after match' qui affiche
une marque noire à gauche de chaque zone que l'utilisateur
sélectionne. Celui-ci est donc informé des zones qu'il a
précédemment sélectionnées. Cette information
est précieuse lorsque le sujet doit, pour une même question,
fournir plusieurs réponses espacées dans le temps (par exemple,
choisir les chapitres dans une table des matières). Cette information
n'est pas disponible pour les réponses de type 'objet sensible'. Elle
n'est pas effaçable en cours d'interaction et n'est malheureusement pas
modifiable par l'auteur (qui voudrait par exemple la placer ailleurs ou en
changer la forme). Si ces contraintes ne conviennent pas à l'auteur, ou
s'il utilise un autre langage qui n'offre pas cette fonctionnalité, il
est relativement simple de la programmer. Il s'agit d'ajouter dans chaque
feed-back l'affichage d'un symbole quelconque, lequel n'informe pas de la
qualité de la réponse, mais simplement de son choix.
3) Réponses de type 'déplacement d'objet' et 'touche'. Ces
types de réponse n'offrent pas d'option qui permette à
l'utilisateur de deviner le mode d'interaction. Ce mode devra donc soit
être clarifié par la nature même du stimulus (par exemple,
l'utilisateur sait que les pièces d'un jeu d'échec doivent
être déplacées), soit être explicitement
décrites dans l'icône d'interaction (par exemple,
" Déplace les pièces dans les boîtes ", ou
" Réponds par A ou B ").
4) Réponses de type 'texte'. Lors qu'une réponse texte est
fournie, le sujet voit la zone de réponse,
matérialisée par un 'entry marker' indiquant le début de
la zone réponse (sous forme d'un triangle dans Authorware), ainsi que
par le changement du curseur en curseur-texte (barre verticale). Le
triangle de début de réponse est optionnel dans Authorware.
L'auteur ne devrait s'en passer que lorsque l'utilisateur perçoit
clairement où apparaîtra le texte entré au clavier: par
exemple, dans des formulaire où le texte sera affiché dans une
zone précise, dans des texte lacunaires ou les mots absents sont
remplacés par des points , ... Lorsque la zone de réponse est
encadrée ou affichée dans une autre couleur, l'utilisateur peut
estimer la longueur maximale de la réponse attendue. Toute autre
contrainte sur la réponse doit être spécifiée de
façon explicite: "Veuillez ne pas utiliser de forme négative",
"Veuillez vous exprimer au présent", "Respectez les majuscules",
"Répondez par un seul mot,"...
Lorsque le sujet dispose de plusieurs possibilités de réponse, il
est parfois utile de préciser si ces réponses sont
complémentaires ou exclusives. Les concepteurs de l'interface
standard du Macintosh ont pour cela différencié deux types de
boutons:
- les bouton-radio sont mutuellement exclusifs au sein d'un groupe de
boutons: la sélection d'un bouton a pour effet de
dé-sélectionner le bouton alors sélectionné dans ce
groupe (comme les boutons de sélection sur une radio)
- les 'check-box' sont cumulables: la sélection d'un item n'a
pas d'effet sur les autres items préalablement
sélectionnés (comme dans le remplissage d'une check-list').
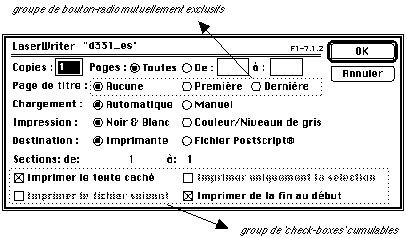
Figure 4.4: Bouton-radio et 'check-box' dans le dialogue d'impression du
système 7 du Macintosh
Comme l'illustre la figure 3.4., ces deux types de bouton ont des
représentations graphiques différentes. Il serait
intéressant de vérifier quel pourcentage des utilisateurs de ce
système sont conscients de cette convention ou l'utilisent
implicitement. Authorware n'a pas inclus ce genre de bouton dans son
répertoire de types de réponse. L'auteur désirant
construire quelque chose de semblable devra donc le faire manuellement,
à savoir gérer l'affichage (apparition et disparition du point
noir dans un bouton-radio et d'une croix dans les check-box) et gérer
les relations entre les bouton-radio d'un même groupe.
3.3.2 L'élaboration et l'émission d'une réponse par
l'utilisateur.
Cette phase et la suivante ne font pas l'objet d'une représentation
explicite dans Authorware. L'exécution d'un programme s'interrompt
après l'icône 'interaction'. Elle reprend au moment où le
sujet a terminé d'introduire sa réponse, par exemple lorsqu'il a
cliqué sur un bouton, déplacé un objet dans une des zones
prévues ou pressé la touche 'return' au terme d'une
réponse-texte. Le signal d'émission est spécifique
à chaque mode d'interaction. Lorsqu'une icône d'interaction
comprend des réponses de types différents (par exemple, une
réponse 'texte' et un bouton 'aide'), l'analyse reprend dès que
le signal d'émission de l'une des réponses a été
fourni.
1) Réponses de type 'bouton' . Emettre une réponse
consiste à cliquer sur un bouton. Le signal est envoyé lorsque
l'utilisateur relâche le bouton de la souris. Si ce dernier
déplace le curseur hors du bouton sans relâcher le bouton de la
souris, sa réponse n'est pas émise. Le bouton par
défaut dispose d'un autre signal d'émission: presser la
touche 'return'. Sur Macintosh par exemple, l'utilisateur en est informé
par une convention implicite selon laquelle ces boutons apparaissent
encerclés par un deuxième trait, plus épais. Une
interaction ne peut contenir qu'un seul bouton par défaut, que le
concepteur désigne par l'option 'button type'. L'utilisation de boutons
par défaut est particulièrement utile lorsqu'on peut facilement
anticiper la réponse la plus probable du sujet (par exemple, bouton
'imprimer' dans le dialogue d'impression d'uns document). L'usage de boutons
par défaut est évidemment inadéquat dans une question
destinée à évaluer des connaissances.
2) Réponses de type 'menu'. Emettre une réponse
consiste à cliquer sur le titre du menu apparaissant dans la barre de
menus (haut de l'écran), à garder le bouton enfoncé tout
en déplaçant le curseur jusqu'à l'item
sélectionné. Le signal d'émission est transmis lorsque
l'utilisateur relâche le bouton de la souris.
3) Réponses de type 'zone sensible' et 'objet sensible'.
Le concepteur peut régler le critère d'émission
de la réponse en termes de nombre de 'clicks' sur l'objet. Trois cas
sont proposés: la réponse est émise (1) dès que le
curseur passe sur la zone ou l'objet sensible (zéro-click), (2) lorsque
le sujet clique une fois, ou (3) lorsque le sujet clique deux fois. Dans le
module 1, nous avons vu que le double-click correspond
généralement à une réponse de type 'ouvre' ou 'met
en route', alors que le simple click est utilisé pour désigner un
objet. Par contre, le mode zéro-click est plus adapté aux cas
où l'utilisateur peut obtenir une information 'en passant' sur un objet,
par exemple ses dimensions. La disponibilité de plusieurs modes
d'émission permet au concepteur de discriminer différents
niveaux d'intentionnalité: le sujet peut cliquer une fois pour
obtenir de l'information sur un objet et deux fois pour désigner
celui-ci comme réponse (ou cliquer respectivement zéro fois et
une fois).
4) Réponses de type 'déplacement d'objet' .
L'émission de la réponse consiste à relâcher le
bouton de la souris lorsque l'objet déplacé se trouve à un
endroit spécifique. La position prise en compte sera celle du centre de
l'objet. Certaines variantes peuvent être introduites, par exemple
permettre à l'utilisateur de déplacer l'objet en plusieurs fois
(et de presser un bouton lorsqu'il a terminé) ou d'utiliser les touches
de déplacement du curseur pour ajuster finement la position finale de
l'objet). Ces variantes ne sont pas prises en charge par Authorware, mais elles
peuvent être programmées par l'auteur.
5) Réponses de type 'texte' et 'touche. Par défaut,
le signal d'émission d'une réponse de type 'texte' est la touche
'return'. Les possibilités d'édition de cette réponse sont
généralement limitées à l'effacement d'un
caractère ou de portions du texte. Dans Authorware, l'auteur peut
modifier le signal d'émission et le remplacer par exemple par une touche
fonction ou la touche 'enter'. Il est recommandé de ne remplacer le
signal 'return' que lorsqu'on a de bonnes raisons de le faire, car cette
convention fait aujourd'hui partie du bagage informatique de l'utilisateur
moyen. Une 'bonne raison' de remplacer le signal 'return' est lorsqu'un 'retour
de chariot' fait partie de la réponse elle-même, par exemple
lorsque l'utilisateur doit entrer un texte de plusieurs lignes. L'auteur peut
également demander que le système génère
lui-même le signal d'émission lorsque N caractères ont
été introduits. En réalité, une réponse de
type 'touche' constitue une réponse de type 'texte' pour laquelle ce
nombre maximal de caractères a été fixé à 1.
On peut par exemple fixer cette limite à 3 lorsque le sujet doit
répondre par OUI ou NON. Il convient d'utiliser le 'return automatique'
('auto entry') avec la plus grande prudence, car le sujet habitué
à presser 'return' au terme de sa réponse aura tendance à
presser 'return' même lorsque ce geste ne lui est pas demandé.
Dans certains cas, ce signal excédentaire sera conservé dans le
buffer d'entrées (entry buffer) et traité comme la réponse
à la question suivante, sans que l'utilisateur ait la possibilité
d'y répondre. Certaines solutions sont cependant disponibles dans ce
cas, telles que vider explicitement la queue d'entrées
(possibilité qui n'est pas offerte Authorware) ou demander au
système d'ignorer les réponses vides (constituées du seul
signal d'émission). Authorware permet en outre de définir la
taille et la position de la fenêtre de réponse, de
déterminer la longueur maximale de la réponse (en nombre de
caractères), ainsi que la police et la taille des caractères. Ces
options ainsi que celles concernant le signal d'émission ne sont pas
définies dans le dialogue propre à une réponse (comme
c'était le cas pour les types de réponse ci-dessus), mais dans
l'icône d'interaction elle-même (en choisissant 'Text Entry
Options'). Par conséquent, les options choisies concernent l'ensemble
des réponses 'texte' associées à une même
icône d'interaction. Authorware ne gère qu'une zone
d'entrée de texte par icône d'interaction. Pour une
interaction de type 'formulaire' dans laquelle plusieurs zones de
réponse-texte semblent disponibles simultanément, il faut donc
prévoir plusieurs interactions différentes ainsi qu'un
interaction d'ordre supérieur qui permet à l'utilisateur de
sélectionner la zone de réponse (en cliquant ou au moyen des
touches 'flèche').
3.3.3 La réception de la réponse par le système.
Dans la conversation courante, nous utilisons de brefs messages pour signaler
à notre interlocuteur la bonne réception de son message: 'Je vous
ai entendu et je vais vous répondre'. Ce signal de réception peut
se limiter à un léger hochement de tête. Dans l'interaction
personne-machine d'autres conventions ont été établies.
Ces conventions sont partiellement liées au type de réponse.
Elles sont définies dans le dialogue associé à chaque
réponse. Le concepteur peut définir d'autres signaux de
réception de la réponse que ceux offerts par Authorware, par
exemple un son. Ces signaux doivent alors être explicitement
prévus par l'auteur et insérés dans le feed-back.
1) Réponses de type 'bouton'. La réception de la
réponse est confirmée par l'affichage momentané en
contraste inversé du bouton sélectionné.
2) Réponses de type 'menu. La réception de la
réponse est confirmée par le clignotement de l'item lorsque le
bouton est relâché.
3) Réponses de type 'zone sensible' et 'objet sensible'.
L'auteur peut demander l'affichage momentané en contraste
inversé de l'objet ou la zone sélectionnée.
4) Réponses de type 'déplacement d'objet'.
Authorware propose trois signaux de réception du message: l'objet
déposé peut (1) rester à destination, (2) être
déplacé automatiquement au centre de la zone identifiée ou
(3) être ramené à sa position de départ. Le signal 2
(centration) est intéressant lorsqu'on désire éviter au
sujet les tâtonnements liés à un ajustement fin de la
position de l'objet. Le signal 3 (retour) est utile lorsque le sujet rencontre
plusieurs fois la même interaction. Il retrouve alors les objets à
leur position de départ. Il est également utilisé dans le
cas illustré par la figure 3.4. L'auteur y définit deux zones de
réponse A et B plus une zone C qui recouvre l'ensemble de
l'écran. Si l'utilisateur dépose l'objet ni dans A, ni dans B,
cet objet sera considéré comme ayant été
déposé dans C. L'auteur demandera à Authorware de ramener
à son point de départ tout objet déposé en C afin
de signaler à l'utilisateur qu'il a manqué sa cible.
5) Réponses de type 'texte'. Dans Authorware, lorsque le
sujet presse 'return', la zone réponse apparaît dans une autre
couleur.
6) Réponses de type 'touche. Aucun signal de
réception de message n'est fourni par ce mode de réponse.
3.3.4 L'analyse des réponses
L'analyse des réponses se compose d'une série de tests successifs
effectués par Authorware selon leur disposition dans l'icône
d'interaction (de la gauche vers la droite). La plupart de ces tests sont
simples: les coordonnées (x,y) du click du sujet appartiennent-elles
à tel bouton, à tel objet ou à telle zone sensible? Le
'click' a-t-il été effectué sur tel item de menu ou dans
telle zone de destination? Les tests concernant les réponses de type
'texte' sont un peu plus complexes et expliqués dans le module 4.
L'ordre des tests est important lorsque ces tests ne sont pas exclusifs,
c'est-à-dire lorsque la même réponse peut appartenir
à plusieurs classes de réponses. Comme l'illustre la figure 3.5,
les réponses qui exigent un 'click' de la souris (type 'bouton', 'objet
sensible', 'zone sensible' ou 'déplacement d'objets') ne sont pas
exclusives: l'utilisateur peut cliquer sur un point qui appartient à
plusieurs zones. Il en va de même pour les réponses de type
'texte' ou 'touche': une même réponse peut correspondre à
plusieurs patterns. Il convient dans ces cas de considérer les tests
dans leur ordre et de suivre les branchements associés. Nous reviendrons
à ce problème dans le module 4.
Il ne faut pas confondre 'test satisfait' et 'bonne réponse'. Les tests
réalisés sur la réponse du sujet ne déterminent pas
en soi si une réponse est correcte ou incorrecte d'un point de vue
pédagogique. Un test vérifie simplement si une réponse
appartient ou non à une classe de réponses, c'est-à-dire
si elle satisfait aux critères qui définissent cette classe de
réponse. Si le résultat du test est positif, cela signifie
simplement que la réponse appartient à cette classe. Cette classe
peut être une classe de réponses incorrectes. Dans Authorware,
l'auteur peut préciser si une classe de réponses est correcte
('correct answer'), erronée ('wrong answer') ou non jugée ('not
judged'). Dans la catégorie 'non jugée', on inclut
généralement les réponses non interprétables ou les
réponses aux questions non didactiques (par exemple, "Quel est votre
nom?"). Le fait de définir une réponse comme correcte, incorrecte
ou neutre ne modifie pas la structure de l'interaction. Elle permet seulement
à Authorware de comptabiliser automatiquement le pourcentage de
réponses correctes et incorrectes.
Figure 4.5: Zones de réponse imbriquées (vues en mode auteur)
3.3.5 L'association d'un feed-back à chaque classe de
réponses.
Le feed-back est l'icône associée à une réponse. Il
s'agit le plus souvent d'une icône de présentation, mais il peut
tout aussi bien s'agir d'une icône de son, d'animation, de calcul,
d'attente ou d'effacement. Si l'auteur désire associer plusieurs
icônes, il place une icône 'groupe' à l'intérieur de
laquelle il peut construire un sous-programme. Le terme feed-back ne se limite
donc pas, comme nous l'avons dit précédemment, à un simple
message d'évaluation d'une réponse du type "C'est exact". Si
l'utilisateur pousse sur un bouton 'effacer', le feed-back est l'effacement. Si
l'utilisateur déplace un objet de type 'crayon', le feed-back est
l'apparition du trait. L'auteur dispose d'une liberté totale quant
à la définition de ces feed-back.
3.3.6 L'association d'un branchement à chaque classe de
réponses.
Dans l'algorithme d'analyse de réponse, les deux cas de branchement les
plus fréquents sont soit de recommencer l'interaction ('try
again') afin fournir une nouvelle réponse, soit quitter
l'interaction ('exit interaction') afin reprendre le déroulement
normal du programme. Dans une situation didactique, le premier branchement est
généralement associé aux réponses incorrectes et le
second aux réponses correctes ainsi qu'aux cas où lorsque le
sujet a dépassé un critère donné (nombre maximum de
tentatives de réponse, temps maximum de réponse).
Avec ces deux types de branchement, lorsqu'un test est positif, le programme
soit sort de l'interaction (`exit interaction'), soit attend une nouvelle
réponse (`try again'), ce qui implique que cette réponse subit un
et un seul test. Si l'auteur désire que la réponse passe
plusieurs tests successifs même dans le cas où le premier est
positif, il peut demander le branchement 'continue'. Dans ce cas,
Authorware passe simplement au test suivant. Son exécution est
visualisée par le fait que la flèche renvoie vers la ligne des
tests successifs. Cette possibilité sera en particulier utile si
l'utilisateur introduit deux informations de nature différente, par
exemple "3500 francs français". L'évaluation de cette
réponse exige, d'une part, une analyse de "francs français" par
l'analyseur de réponse textuelle et, d'autre part, une
vérification du montant par une réponse de type conditionnelle.
L'utilisation précise de ces formes de branchement sera
détaillée dans le module 5 consacré à la structure
des interactions. Une quatrième forme de branchement ('return')
est utilisé pour les réponses permanentes. Elle s'écarte
de la structure temporelle des interactions décrite dans ce chapitre et
sera par conséquent décrit dans le module consacré
à l'architecture des programmes (module 7).
Rappelons que ces modes de branchement sont indépendants du mode
d'interaction. Dans Authorware, le type de branchement est
sélectionné dans un menu qui est identique pour tous les types de
réponse.
3.4 Gestion d'écran
L'effacement de la question, de la réponse et du feed-back peuvent
être réalisés manuellement au moyen de l'icône
d'effacement. Authorware offre toutefois une gestion semi-automatisée de
l'effacement au sein d'une interaction:
3.4.1 Effacer la question.
Le dialogue d'édition de l'icône d'interaction permet de
préciser le mode d'effacement (effets spéciaux) et le moment de
l'effacement de la question (contenu de l'icône interaction):
- en fin d'interaction ('upon exit');
- après chaque réponse du sujet ('after each entry');
- seulement par une icône explicite d'effacement ('don't
erase').
3.4.2 Effacer la réponse.
Par défaut, une réponse de type texte est effacée
dès que le sujet introduit le premier caractère de la
réponse suivante. En sélectionnant 'text entry options', l'auteur
peut en demander l'effacement immédiat.
3.4.3 Effacer le feed-back.
Ce qui figure sur l'écran au terme du feed-back peut être
effacé:
- avant que le sujet fournisse une autre réponse ('before next
entry');
- après que le sujet fournisse une nouvelle réponse ('after
next entry');
- lorsque l'interaction est terminée ('upon exit');
- seulement par une icône explicite d'effacement ('don't
erase').
La gestion de l'écran est régie par les principes
décrits dans le module 2. Le principe d'information minimale peut
conduire l'auteur à scinder l'interaction en plusieurs écrans
(accessibles par un bouton ou menu), par exemple lorsque les consignes sont
complexes et ne peuvent être affichées simultanément
à la question. Le principe qui consiste à créer des
invariants d'écrans reste essentiel. Si l'auteur prend la
précaution d'afficher systématiquement au même endroit
chaque question ou de réserver une zone pour les feed-back,
l'utilisateur induit rapidement des automatismes lui permettant de trouver plus
rapidement l'information pertinente. Ces invariants seront d'autant plus utiles
qu'ils sont maintenus à travers une longue séquence
d'interactions.
L'auteur sera particulièrement attentif à maintenir à
l'écran l'information nécessaire à l'activité de
l'utilisateur. Il se souviendra que:
- Effacer la question à chaque réponse prive le sujet de
pouvoir relire la question pour comprendre le feed-back.
- Effacer la réponse avant que le sujet n'ait lu le feed-back prive
le sujet de pouvoir comparer sa réponse et le feed-back fourni.
- Effacer le feed-back avant que le sujet fournisse une nouvelle
réponse ne permet pas au sujet de relire le feed-back pendant qu'il
réfléchit à sa nouvelle réponse.
4. L'analyse des réponses
On parle de question fermée, ou de question à choix multiple,
lorsque le sujet choisit sa réponse dans un ensemble fini de
propositions. La plupart des types de réponse offerts par Authorware
correspondent à des questions fermées (boutons zones
sensibles,...). Ce module passe en revue les défauts fréquents de
ce type de questions et les moyens de les éviter. On parle de question
ouverte lorsque le sujet construit sa réponse, en particulier lorsqu'il
répond par du texte (écrit ou oral). Ce module décrit le
traitement des réponses 'texte' tel qu'il est réalisé par
Authorware. Les techniques utilisées en intelligence artificielle pour
traiter des réponses plus complexes (traitement du langage naturel) sont
ensuite brièvement présentées.
4.1 Questions ouvertes et fermées
On parle de question fermée, ou question à choix multiple,
lorsque le sujet choisit sa réponse dans un ensemble fini de
propositions. La plupart des types de réponse offerts par Authorware
correspondent à des questions fermées:
- le sujet choisit sa réponse parmi les N boutons proposés;
- le sujet clique sur une des N zones ou objets sensibles définis
(ces zones ou objets peuvent parfois être nombreux);
- le sujet déplace un objet dans une des N zones définies;
- le sujet presse une des N touches considérées;
- le sujet sélectionne un des N items des M menus
définis.
On parle de question ouverte ou de question à
réponse construite lorsque le sujet construit sa réponse, en
particulier lorsqu'il répond par du texte (écrit ou oral). Du
point de vue de l'élève, les réponses de type 'texte' lui
permettent en effet de construire librement sa réponse. Toutefois, du
point de vue de la machine, les réponses de type texte sont
analysées par rapport à un ensemble de classes de réponses
(voir figure 4.1). Ces questions pourraient donc être
considérées comme des questions fermées.
Pour les autres modes d'interaction étudiés, l'analyse de la
réponse se limite à vérifier si la réponse fournie
correspond à une des réponses prévues. Dans certains cas,
l'ensemble des réponses prévues est défini en extension.
Dans le cas de réponses texte, l'auteur définit des classes de
réponses considérées comme synonymes. Ces sous-ensembles
sont grands, voire infinis. Aussi, ils ne sont pas définis en extension,
mais comme des espaces de variation autour d'une réponse-type.
L'auteur définit la réponse type (ou pattern) et les variations
autorisées. Le processus de comparaison d'une réponse et d'un
pattern porte le nom de 'pattern matching'.
Figure 5.1 : Comparaison de l'analyse de réponses 'bouton' et de
l'analyse de réponses 'texte'
Toutes les réponses construites ne sont pas des réponses texte.
Une réponse construite non-verbale consiste par exemple à
assembler les divers éléments d'un circuit électrique. Une
telle réponse peut être décomposée en une
séquence d'interaction simples (du type de celles décrites dans
le module précédent), au cours desquelles le sujet
sélectionne et positionne des objets. Le problème apparaît
si l'auteur veut analyser globalement le circuit construit par le sujet. Il
doit alors tenir compte des objets connectés, des valeurs
associées (intensité, résistance) et de la position
relative des objets. Cette analyse complexe peut être
réalisée avec Authorware, mais celui-ci ne comprend pas de
fonction spécifique pour ce type d'analyse. Par contre, Authorware
dispose d'outils spécifiques pour l'analyse des réponses de type
'texte. Ceux-ci permettent d'identifier les mots, leurs caractéristiques
et leur ordre dans la phrase. Ces outils sont décrits dans la section
4.3.
4.2 Avantages et inconvénients des QCM dans un didacticiel
Les QCM ont été intensivement utilisés dans
l'évaluation pédagogique car ils permettent un traitement rapide,
objectif et facilement programmable des réponses. Ils ont cependant
souvent été critiqués, car la plupart d'entre eux
étaient mal construits et ne fournissaient pas une mesure valide des
compétences. La plupart de ces défauts ne sont cependant pas
intrinsèques aux QCM. Certains QCM peuvent posséder un pouvoir
diagnostic supérieur aux questions ouvertes, par exemple en incluant
parmi les propositions un ou plusieurs 'distracteurs' (proposition
correspondant à une erreur classique des sujets). Voici quelques
conseils concernant la construction d'un QCM.
- Clarté du tronc: Le tronc désigne la question
elle-même, par exemple 'laquelle des propositions suivantes est
correcte?'. Il convient d'éviter les formulations négatives
('laquelle des propositions suivantes est incorrecte') et à fortiori les
doubles négations ('laquelle des propositions suivantes n'est pas
incorrecte' ou 'quel pays n'a pas quitté l'URSS en 1990?'). Ces
formulations introduisent une difficulté supplémentaire qui ne
correspond pas à la compétence mesurée et réduisent
par conséquent la validité interne de la question: le sujet peut
se tromper parce qu'il n'a pas lu attentivement la question et non par
ignorance de la réponse. Dans les cas où une formulation
négative est inévitable, il convient de mettre la forme
négative en évidence: 'Laquelle des lois suivantes n'est
PLUS en vigueur aujourd'hui ?'.
- Nombre de réponses possibles: Augmenter le nombre de
propositions permet de réduire le rôle du hasard. En outre,
compter un score négatif pour les réponses erronées incite
le sujet qui ne connaît pas la réponse à s'abstenir de
répondre, plutôt que de répondre au hasard. On peut
alternativement inclure un bouton 'Je ne sais pas'. Certains logiciels
permettent au sujet d'indiquer son degré de confiance dans sa
réponse, par exemple en misant de l'argent fictif ou tout autre valeur
prélevée dans un contexte ludique.
- Nombre de réponses correctes: Le raisonnement de
l'utilisateur sera plus complexe si on ne lui indique pas à l'avance le
nombre de propositions vraies. Sachez en outre que le concepteur a tendance
à placer la réponse correcte vers le milieu de la liste des
propositions et à ne pas mettre la proposition correcte au même
endroit dans deux questions consécutives.
- Construire des distracteurs pertinents: Afin de multiplier le
nombre de propositions, le concepteur a parfois tendance a ajouter des
propositions fantaisistes que le sujet peut écarter sans aucune
difficulté. En outre, les affirmations générales
('toujours', 'jamais', 'tous', 'aucun',..) sont généralement
fausses. Les affirmations nuancées ont tendance à être
vraies ('dans certains cas', 'le plus souvent', 'parfois',...).
Nous avons
vu dans le module 3 que l'interface du Macintosh utilise deux
représentations différentes des questions à choix
multiples: les 'check box' sont utilisées lorsque plusieurs
réponses peuvent être fournies alors que les 'radio button' ne
permettent de communiquer qu'une seule réponse. Ces types de bouton ne
sont pas disponibles dans Authorware. Si l'auteur veut profiter de
l'assimilation probable de ces conventions par les utilisateurs, il devra
dessiner des objets d'interactions qui imitent l'apparence et le fonctionnement
de ces boutons.
Il existe une forme plus complexe de questions fermées, les questions
à appariement, qui consistent à mettre en relation des
propositions fournies dans deux listes distinctes. Dans ce cas, le nombre de
réponses possibles est fortement accru, ce qui réduit la part
laissée au hasard. La présentation classique des questions par
appariement est celle présentée dans la figure 4.2.a : le sujet
relie par un trait les propositions qu'il désire associer. Ce type
d'interaction peut être construit au moyen d'Authorware, par un
développeur avancé (fonction 'drawline). Le programmeur
débutant peut lui substituer un format de présentation
illustré par la figure 4.2.b. Pour autant que le sujet comprenne le
principe d'un tableau à deux entrées, son activité
cognitive sera identique à celle sollicitée par l'interaction
illustrée en 4.2.a. En effet, dans les deux questions a et b,
l'activité mentale du sujet consiste à former les paires (A,2),
(B,2), (B,4) et (D,1). La question B est plus facile à programmer
puisqu'il suffit de créer des zones sensibles et d'y faire
apparaître une marque lorsque le sujet clique sur cette zone. Cette
solution illustre deux idées importantes de ce cours. Primo,
l'interaction est évaluée par rapport à l'activité
cognitive du sujet davantage que par rapport à son activité
physique (cliquer, déplacer la souris, frapper une touche). Secundo,
lorsqu'une interaction facile à réaliser sur papier (a) se
révèle plus difficile sur écran, il est parfois
préférable de lui chercher une substitution que d'obstiner
à la transposer fidèlement.

Figure 5.2 : Questions à appariement: à gauche,
présentation classique (a), à droite, présentation en
table (b).
Voici certaines recommandations concernant la construction des questions par
appariement:
- La question est plus complexe si la relation entre les deux listes n'est
pas bijective, c'est-à-dire si une proposition de la première
série peut-être associée à plusieurs propositions de
la seconde série et réciproquement. Lorsque deux listes de quatre
items doivent être appariées, le nombre de réponses
possibles est de 24 (factorielle de 4) si la relation est bijective et de 256
(44) si la relation n'est pas bijective.
- Si les deux listes ont la même longueur, les sujets peuvent induire
à tort que cela implique une relation bijective. L'auteur peut soit
proposer des listes de longueurs différentes, soit préciser la
nature de la relation dans le tronc de la question ('Plusieurs flèches
peuvent partir du même point ou arriver au même point'; 'Plusieurs
croix peuvent être placées dans la même ligne ou dans la
même colonne').
- Si les deux listes sont de longueurs différentes, il est
préférable de placer la plus longue à gauche. Imaginons
que les deux listes comprennent respectivement 8 et 3 items. Les sujets ont
tendance à lire la première proposition de la liste de gauche
puis à chercher son correspondant dans la liste de droite. Si celle-ci
ne contient que quelques items, les sujets les retiendront assez rapidement et
pourront délibérer sur chaque item de gauche sans relire à
chaque fois toutes les propositions de la liste de droite.
4.3 Analyse des réponses 'texte' par Authorware
4.3.1 Principes de 'pattern matching'
L'objectif d'un 'pattern matcher' est de définir de façon
synthétique une classe de réponses considérées
comme équivalentes par l'auteur. Les solutions les plus avancées
permettent de définir la structure syntaxique de ces phrases. Elles sont
décrites dans la section 4.4. Des procédures plus simples de
pattern matching sont disponibles dans les langages-auteur. Ces méthodes
reposent sur l'identification d'un ou plusieurs mots-clé,
c'est-à-dire des mots que l'on considère comme essentiels dans la
réponse. L'auteur peut autoriser des variations orthographiques simples
liées à la définition du pattern lui-même et
spécifier quelques paramètres qui influencent la procédure
de pattern matching. La procédure de pattern matching consiste en une
mise en correspondance, mot par mot, caractère par caractère,
de la réponse de l'utilisateur et du 'pattern' spécifié
par le concepteur. Elle peut se visualiser par le défilement du
pattern le long de la réponse analysée (figure 4.3). La
fenêtre du pattern 'saute' de mot en mot, jusqu'au moment où un
mot de la réponse correspond au pattern.
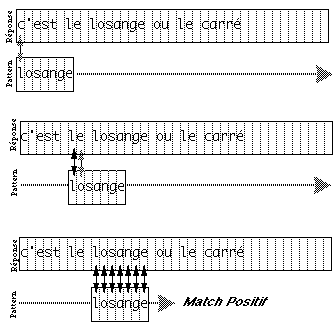
Figure 5.3 : Visualisation du fonctionnement de pattern matching
Un pattern est composé de caractères simples et de
caractères spéciaux. Un caractère simple doit être
mis en correspondance avec un caractère identique dans la réponse
analysée. Un caractère spécial peut être mis en
correspondance avec plusieurs caractères de la réponse
analysée. Les caractères spéciaux disponibles dans
Authorware sont présentées dans la section 4.3.2. Si la
fenêtre du pattern parcourt toute la réponse sans que ce pattern
ait été mis en correspondance avec un élément de
cette réponse, le résultat du matching est négatif (voir
figure 4.4). Le terme 'résultat négatif' n'indique pas si une
réponse est correcte ou incorrecte, il indique simplement si le pattern
a été identifié. Si le pattern décrit une
réponse incorrecte et que la réponse fournie satisfait ce
pattern, le résultat de l'analyse sera positif. Les termes
'résultat positif' et 'résultat négatif' signifient
respectivement 'pattern identifié' et 'pattern non identifié',
ils n'ont pas de signification pédagogique.
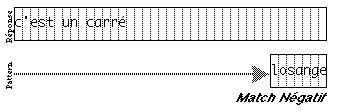
Figure 5.4 : La résultat du processus de matching est négatif
4.3.2 Définition du pattern
Par défaut, le matching n'autorise aucune différence entre les
caractères du pattern et de la réponse, y compris des
différences mineures telles que la présence d'une majuscule au
lieu d'une minuscule. Toute tolérance dans la mise en correspondance
doit être spécifiée par le concepteur.
4.3.2.1 Caractères spéciaux
Un caractère spécial (également appelé 'joker')
peut être mis en correspondance avec une classe de caractères.
Authorware offre deux caractères spéciaux: * et ?. Chaque
caractère spécial peut être déclaré normal
(si vous désirez par exemple vérifier que l'utilisateur met un ?
au bout de sa question), en le faisant précéder d'un 'backslash'
( \ = option + majuscule + /):
- Le caractère spécial ? peut être mis en
correspondance avec n'importe quel caractère. Il ne permet cependant pas
l'oubli de ce caractère, ni l'ajout d'un caractère qui
introduirait un décalage entre la réponse analysée et le
pattern. Par exemple, le pattern `losange' sera identifié dans les mots
`losange', `lozange', `lorange'... mais pas dans le mot `lossange'.
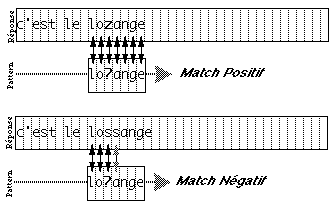
Figure 5.5 : Fonctionnement du caractère spécial '?'
- Le caractère spécial * peut être mis en correspondance
avec zéro, un ou plusieurs caractères quelconques. Il permet en
particulier d'accepter l'oubli de lettre, le redoublement incorrect de
consonnes, etc. On peut visualiser son rôle comme un décrochement
du pattern dont la partie qui n'est encore satisfaite continuerait sa course
à la manière d'un wagon fou dans le petit matin blême. Si
le pattern se constitue uniquement d'un *, il est identifié dans toute
réponse.
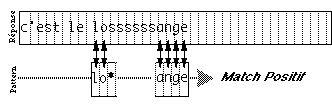
Figure 5.6 : Fonctionnement du caractère spécial '*'
4.3.2.2 Patterns disjonctifs
Le concepteur peut définir plusieurs patterns synonymes. Le OU s'exprime
dans Authorware par une barre verticale (|). Le résulat de l'analyse
sera positif lorsqu'un des patterns spécifiés est
identifié dans la réponse. Ce processus de matching disjonctif
est illustré par la figure 4.7: arrivé en bout de course, la
fenêtre reprend la comparaison au début avec un autre pattern.

Figure 5.7 : Matching disjonctif
4.3.2.3 Patterns conjonctifs
Le matching de pattern conjonctif fonctionne de la même façon,
à la différence évidente que chacun des patterns doit
être identifié dans la réponse. Il existe deux
façons de réaliser un pattern conjonctif: avec ou sans respect de
l'ordre. Ces modalités sont expliquées plus bas. Authorware
n'utilise pas de symbole pour exprimer la conjonction: le pattern 'A B'
signifie 'A' et 'B'.
4.3.2.4 Patterns complexes
Le pattern 'A B | C D' correspond à la formule '(A et B) ou (C et D)'.
Les réponses 'A B' et 'C D' seront acceptées. Si les contraintes
d'ordre sont levées (voir ci-dessous), les réponses et 'B A' et
'D C' seront également acceptées. Par contre, les réponses
'A D', 'A C', 'B C', ... conduiront à un résultat négatif.
4.3.3 Filtrage de la réponse de l'élève
Filtrer la réponse de l'utilisateur consiste à la traiter avant
de commencer le matching.
4.3.3.1 Elimination des signes de ponctuation
Cette option ('Ignore: extra punctuation') élimine de la réponse
tout signe de ponctuation qui ne figure pas dans le pattern. Par contre, si le
pattern comporte par exemple un ";", et que la réponse comporte
également un ";", celui-ci ne sera pas supprimé afin de permettre
le matching ultérieur.
4.3.3.2 Elimination des espaces
Cette option ('Ignore: all spaces' dans le dialogue 'Text Response Options')
élimine tous les blancs de la réponse de l'élève.
Cette option doit être utilisée avec prudence vu que ce sont les
blancs qui décomposent la réponse en mots à comparer au
pattern. Cette option peut s'avérer utile par exemple dans le cas
où les sujet doit répondre par un seul nombre. S'il introduit '1
237' avec un espace après le chiffre des millier, Authorware identifiera
deux nombres dans sa réponse.
4.3.4 Spécifications relatives à la procédure de
matching
Authorware permet de modifier le fonctionnement standard du processus de
pattern matching.
4.3.4.1 Comparaison de majuscules et minuscules
Au cours du matching, les lettres du pattern et de la réponse sont
comparées deux par deux. Même s'il s'agit de deux lettres
identiques, cette comparaison échoue, lorsque l'une est en majuscule et
l'autre en minuscule. Le concepteur peut lever cette contrainte au moyen de
l'option 'Ignore: capitalization'.
4.3.4.2 Mots excédentaires dans la réponses analysée
Les explications fournies jusqu'à présent fonctionnent selon le
principe du défilement de la fenêtre 'pattern' sur la
réponse analysée. Toutefois, ce défilement peut être
inhibé en 'dé-sélectionnant' l'option 'Ignore extra words'
dans le dialogue 'Text Response Options'. Dans ce cas, le pattern et la
réponse sont mis en correspondance dès le premier mot de la
réponse sans possibilité d'ajustement.
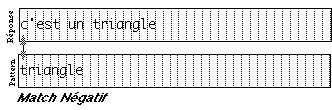
Figure 5.8 : Matching lorsque le concepteur n'accepte pas de mot
excédentaire
4.3.4.3 Conservation de l'ordre lors du matching conjonctif
Lorsque le concepteur définit le pattern 'aaa bbb', il peut
préciser si le matching accepte ou non que les deux
éléments aaa et bbb soient présentés dans le
désordre (option 'Ignore: word order' dans la dialogue 'Text Response
Options') Si le concepteur choisit d'ignorer l'ordre des mots, cela signifie
que chaque composante du pattern conjonctif est recherchée dans
l'ensemble de la réponse. Cela peut se visualiser en imaginant que la
fenêtre du pattern revient en début de réponse comme le
chariot d'une machine à écrire.
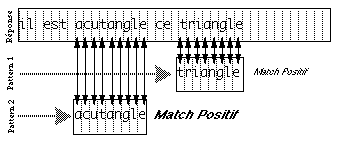
Figure 5.9 : Match conjonctif sans respect de l'ordre
La procédure de respect de l'ordre peut se visualiser de la
manière suivante: lorsque le premier pattern est identifié, la
fenêtre continue sa course avec le second pattern, et ainsi de suite. Si
un des patterns n'est pas trouvé, le résultat est
négatif.
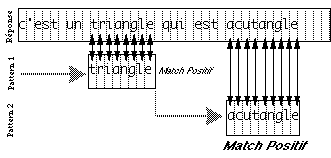
Figure 5.10 : Matching d'un pattern conjonctif avec respect de l'ordre
4.3.4.4 Matching partiel
La procédure de matching partiel est un généralisation du
matching de pattern disjonctif: Elle très utile lorsqu'on désire
que l'utilisateur fournisse n éléments parmi m
éléments attendus. Le concepteur spécifie un pattern
composé d'un certain nombre d'éléments et déclare
le nombre minimal de patterns (option 'Match at least N words' dans la dialogue
'Text Response Options') qui doivent être satisfaits pour que le
résultat du match soit positif. Par exemple, l'auteur qui demande `citez
trois villes de Suisse romande' introduira `Genève Nyon Morges Lausanne
Montreux Neuchatel Sion Martigny Yverdon' (plus d'autres villes s'il le veut)
comme pattern mais spécifiera que seul trois de ces
éléments doivent être identifiées dans la
réponse du sujet pour que le test soit positif.
4.3.4.5 Matching progressif
La procédure de matching progressif permet de satisfaire un ensemble de
patterns à travers plusieurs réponses de l'utilisateur (option
'Incremental matching' dans la dialogue 'Text Response Options'). Cela permet
de traiter des réponses incomplètes. Si l'utilisateur fournit
deux des éléments de la réponse et qu'on lui demande de
compléter celle-ci, il lui suffira de fournir les éléments
qui manquaient dans ses réponses précédentes. Cette
fonctionnalité permet d'éviter un gros travail de programmation
par rapport à des langages classiques.
4.4 Traitement du langage naturel
La disponibilité de procédures paramétrisables d'analyse
de réponse est une caractéristique principale des
langages-auteur. De telles procédures n'existent pas dans les outils
plus universels tels que Hypercard ou Toolbook. La spécificité
d'Authorware par rapport à d'autres langages-auteur est la
présence d'un nombre important de paramètres: ponctuation,
majuscules, mots excédentaires, ordre des mots, espaces, matching
partiel et progressif. Toutefois, il s'agit encore d'un traitement assez
superficiel des réponses, basé sur l'identification de mots et
non de structures. Si le pattern recherché est une phrase, l'auteur peut
soit exiger un respect strict de l'ordre des mots du pattern, soit accorder une
liberté totale. Il ne peut définir un niveau de contrainte
intermédiaire basé sur la syntaxe de la langue.
Considérons par exemple que l'auteur veuille identifier la phrase
suivante: 'Le chien de ma voisine a mordu Michel'. Authorware offre des
possibilités limitées pour discriminer cette phrase parmi
d'autres:
- Si l'auteur définit cette phrase entière comme pattern, avec
ordre strict, la phrase 'Le chien d'une voisine a mordu Michel' sera
rejetée.
- Si l'auteur définit le pattern 'chien voisine mordu Michel', avec
ordre strict, la phrase 'Le chien de la voisine a chassé celui qui a
mordu Michel' sera acceptée.
- Si l'auteur définit le pattern 'chien voisine mordu Michel', sans
contrainte d'ordre, la phrase 'Ma voisine a mordu le chien de Michel' sera
acceptée!
L'idéal serait de pouvoir accepter comme
équivalent à la phrase-cible une phrase telle que 'Michel a
été mordu par le chien de ma voisine'. Certaines techniques
développées par les chercheurs en intelligence artificielle
permettent un tel traitement. Nous les décrivons brièvement ici.
Cette section ne présente pas un tableau de l'état de la
recherche dans ce domaine, elle se limite à présenter quelques
mécanismes élémentaires d'analyse automatique du
langage.
La première étape du traitement du langage consiste à
identifier la catégorie lexicale de chaque mot. Les connaissances
concernant la nature des mots figurent dans un lexique ou dictionnaire.
Celui-ci contient en outre des connaissances morphologiques permettant
d'identifier les diverses variations d'un même mot, notamment de savoir
que 'a mordu' correspond au verbe 'mordre', conjugué à la
troisième personne du passé composé et à la voix
active. Pour traiter notre exemple, les connaissances suivantes sont
nécessaires:
Mot Nature Connaissances
Morphologiques
le article défini masculin singulier le
de préposition de
ma adjectif possessif 1p.s., féminin mon
singulier
chien nom commun masculin singulier chien
voisine nom commun féminin singulier voisin
Michel nom propre masculin singulier Michel
a mordu verbe transitif 3 p.s, passé mordre
composé, voix active
La deuxième étape consiste à identifier des structures
syntaxiques. Ces structures sont décrites en termes de catégories
lexicales et permettent de décrire une grande variété de
phrases. Voici quelques règles qui définissent une grammaire
élémentaire:
1) article + nom commun => groupe nominal
2) adjectif possessif + nom commun => groupe nominal
3) nom propre => groupe nominal
4) article + nom commun + prép. + groupe nominal => groupe nominal
5) verbe transitif + groupe nominal => groupe verbal
6) verbe intransitif => groupe verbal
7) groupe nominal + groupe verbal => phrase
La règle 1 peut se lire comme suit "un article puis un nom commun
forment un groupe nominal". La règle 2 reconnaît 'ma voisine'
comme groupe nominal. La règle 3 identifie 'Michel' comme étant
un groupe nominal. Par contre, si l'utilisateur tape 'mon Michel', aucune de
ces règles n'identifierait cette réponse comme étant
grammaticalement correcte. On peut intégrer dans ces règles des
contraintes morphologiques afin de rejeter une réponse telle que 'mon
voisine'. Après avoir appliqué la règle 2 à 'ma
voisine', il est possible d'appliquer la règle 4 au groupe de mots 'Le
chien de <groupe nominal>'. La figure 4.11 illustre la réduction
progressive de la structure initiale jusqu'à l'identification d'une
structure de phrase élémentaire (règle 7). Ces
connaissances lexicales et grammaticales sont mises en oeuvre par une
procédure de pattern matching plus élaborée que celle
utilisée par Authorware.
La grammaire définie est aussi arbitraire que le pattern défini
par l'auteur avec Authorware. On peut définir des grammaires pour des
sous-langages, des grammaires fausses, des grammaires pour l'analyse
d'expressions algébriques, etc. La procédure d'analyse teste
simplement si une réponse correspond à une grammaire, elle
n'implique pas que cette grammaire ait une valeur absolue. On peut par exemple
analyser une phrase allemande avec une syntaxe française afin de
détecter si un francophone qui apprend l'allemand reproduit dans cette
langue certains aspects de sa langue maternelle. La procédure d'analyse
à partir d'une grammaire formelle n'implique pas non plus que les
règles décrites correspondent à une réalité
psychologique, c'est-à-dire que l'être humain utilise des
règles semblables pour sa compréhension de
l'énoncé. La mise en oeuvre d'un système de règles
est expliqué dans le module 8.
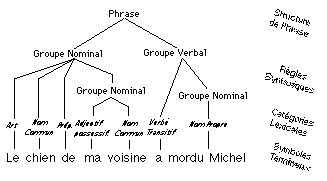
Figure 5.11 : Analyse d'une phrase simple
L'identification de la réponse du sujet peut se faire au moyen de
règles de transformation. Ces règles définissent des
classes de phrases équivalentes à la réponse-cible (du
point de vue de l'auteur). La règle ci-dessous permet de transformer une
phrase exprimée à la voix passive en son équivalent
à la voix active:
sujet (X) + verbe à la voix passive (Y) + 'par' + complément
d'agent (Z)
=>
sujet (Z) + verbe à la voix active (Y) + complément d'objet
direct (X)
Cette règle permet de déterminer que la réponse 'Michel a
été mordu par le chien de la voisine' correspond à la
réponse cible 'Le chien de ma voisine a mordu Michel'. Il convient pour
cela de substituer (le chien de ma voisine) à X, (mordre) à Y et
(Michel) à Z.
(Michel) (a été mordu) (par ) (le chien de la voisine)
=>
(le chien de ma voisine)(a mordu)(Michel)
Ces règles permettent de fournir le feed-back associé à la
phrase-cible identifiée. Par exemple, le concepteur déterminera
que la phrase 'C'est le chien de ma voisine qui a mordu Michel' est une bonne
description de l'image présentée et il fournira le feed-back
'Très bien' à toute phrase équivalente. Cette association
d'une classe de réponses à un feed-back unique constitue
cependant une forme assez rigide d'interaction. On peut faire mieux en
associant une représentation du contenu de la phrase. Ainsi,
l'énoncé utilisé plus haut contient certaines
informations: il s'agit d'une agression (mordre); l'agression a eu lieu dans le
passé; l'auteur de l'agression est un chien (chien-A); la victime de
l'agression est une personne (personne-A); personne-A s'appelle Michel; le
chien appartient à une personne (personne-B); personne-B est de sexe
féminin; personne-B est voisine d'une personne C, auteur de la phrase;
On peut représenter ces entités et leurs relations par des
structures de données. Chaque entité est définie par une
certain nombre de paires attribut-valeur. Par exemple, une personne peut
être décrite par la liste '(nom Paul) (age 35) (taille 178) (sexe
masculin) ...'. L'ensemble des objets qui sont définis par les
même attributs forment une classe. On dit qu'ils constituent des exemples
de cette classe. Les trois personnes (A,B,C) évoquées dans
l'analyse ci-dessus constituent trois exemples de la classe 'personnes'. La
classe 'personnes' constitue une sous-classe de la classe des animaux. La
figure 4.12. illustre les entités décrites, les relations entre
elles ainsi que la hiérarchie des classes. Certains langages
informatiques, dits 'orientés-objet', disposent d'instructions
permettant de définir des classes, d'en créer des exemples, de
définir des traitements spécifiques pour les exemples des
différentes classes, etc.
Cet ensemble d'objets interconnectés porte le nom de 'réseau
sémantique'. Les langages informatiques disposent d'instructions
permettant de retrouver la valeur de l'attribut d'un objet (par exemple
'valeur-de person-A nom'). Si le logiciel dispose de règles permettant
de traduire des questions formulées en langue naturelle en instructions
de lecture du réseau sémantique, il pourra répondre
à des questions telles que: " Est-ce un chien qui a mordu
Michel? ". " A qui appartient le chien qui a mordu Michel? ",
" Ma voisine a-t-elle un chien? ",...
Un réseau sémantique est constituée de symboles et
connections entre symboles. Ces connections permettent de rechercher un symbole
à partir d'un autre, par exemple, de trouver 'voisine' à partir
de 'chien'. Cette performance peut donner à l'utilisateur l'illusion que
le système a compris sa question. L'ordinateur ne comprend en
réalité aucun de ces symboles. Remplacez le symbole 'voisine' par
le symbole 'hk%*3Bz' et le réseau fonctionnera exactement de la
même manière. Aucun de ces symboles ne possède de
signification réelle pour l'ordinateur. Les connaissances
sémantiques de l'ordinateur peuvent se comparer avec la situation d'un
sujet ne parlant pas Chinois, enfermé seul dans une pièce et qui
veut apprendre le chinois au moyen d'un dictionnaire Chinois-Chinois. La
définition d'un mot dans ce dictionnaire renvoie vers d'autres symboles
aussi incompréhensibles que le premier. L'association de symboles
dénués de sens ne fournit pas une véritable
compréhension de ces symboles, mais simplement de produire une
réponse en fonction d'un message complexe.
Les aspects sémantiques et pragmatiques de la langue constituent un
obstacle fondamental au traitement automatique du langage naturel.
Considérons par exemple les phrases suivantes: "Jean a
prêté sa voiture à Paul. Il l'a chaleureusement
remercié." Nos connaissances nous permettent de déterminer que le
pronom 'il' réfère à Paul et non à Jean. Nous
savons que 'prêter' est une action généreuse qui implique
une reconnaissance de l'emprunteur vers le prêteur. Considérons un
autre exemple, inspiré de Dix. et al (1993): "Paul a frappé le
garçon avec un bâton en bois. Christine a frappé le
garçon avec un bonnet en laine." A nouveau, seule une construction du
contexte sémantique nous permet de comprendre que 'avec le bâton
en bois' concerne l'acte de frapper, alors que 'avec le bonnet en laine'
concerne le garçon frappé. La résolution des
ambiguïtés propres au langage courant repose sur une grande
quantité d'informations spécifiques au contexte du message. Ceci
explique que des systèmes relativement robustes n'aient pu être
développés que dans des domaines bien circonscrits, par exemple
la traduction automatique des bulletins d'avalanche. Par contre, toutes les
prévisions concernant le développement de systèmes
génériques de compréhension du langage naturel se sont
révélées largement optimistes.
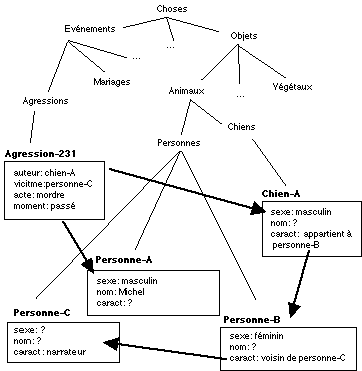
Figure 5.12 : Réseau sémantique permettant d'organiser les
connaissances contenues dans la phrase 'Le chien de ma voisine a mordu Michel'
4.5 La conception des situations de dialogue
Ces techniques de traitement du langage naturel ne peuvent être
réalisées au moyen d'Authorware. Les capacités de
traitement du langage que supportent Authorware sont, nous l'avons dit, plus
restreintes. Certains auteurs ont tendance à construire des interactions
qui dépassent les capacités de traitement offertes par le
système utilisé. La conception d'un logiciel interactif ne
consiste pas à élaborer des activités sans se soucier des
contraintes informatiques, mais au contraire à concevoir des
interactions à l'intérieur d'un espace de contraintes.
Considérons un enseignant qui procède de la façon X dans
sa classe. S'il s'avère que les interactions de type X ne sont pas
supportées par l'outil informatique qu'il a choisi, trois
possibilités lui sont offertes: il peut remettre en question le choix du
logiciel, bricoler le logiciel choisi pour essayer malgré tout de
réaliser le mode X, et enfin chercher une forme d'interaction X',
supportée par le logiciel et fonctionnellement équivalente
à X. Trop souvent, c'est la solution 'astuce bricolée' qui est
choisie. Bien que générale, cette remarque concerne
particulièrement le traitement du langage naturel car nombre d'auteurs
cherchent à reproduire les interactions utilisées par ailleurs,
qui font appel à des capacités d'analyse certes banales chez un
humain, mais sous-développées dans la plupart des logiciels. Ils
cherchent en vain à trouver le 'pattern miracle' capable de discriminer
bonnes et mauvaises réponses. Une meilleure solution consiste en
général à se demander si une interaction
équivalente ne peut se réaliser dans une situation plus
contrainte. Par exemple, au lieu de demander au sujet de décrire sa
famille, on lui demandera de trouver la différence entre deux familles
présentées à l'écran. En d'autres termes, la
qualité d'une analyse de réponse ne dépend pas uniquement
du traitement prévu par l'auteur, mais de la mesure dans laquelle
l'espace des réponses possibles est contraint par la situation. Les
contraintes imposées par la situation définissent en quelques
sorte un niveau intermédiaire entre des questions fermées et des
questions complètement ouvertes.
4.6 Exercices
Les exercices ci-dessous proposent des analyses de réponses simples. Des
cas plus complexes seront traités dans le module suivant.
4.6.1
Question: "Entre les étoiles se forment des nuages,
appelés nuages interstellaires. Ils sont composés à 90%
d'un gaz. Lequel?"
Réponses Feedback
hydrogène, hydrogene "C'est exact. Ces nuages comportent
également des atomes neutres, des ions
et quelques molécules."
ydrogene, hidrogene, ydrogène, hidrogène "C'est exact. Note cependant que
l'orthographe exacte est hydrogène."
autres réponses "Non, il s'agissait d'hydrogène."
4.6.2
Question: "Quel est le pluriel de 'das Kind'?"
Réponses Feed-back
die Kinder "Très bien"
Kinder "Il manque l'article. Recommence."
kinder "Attention aux majuscules! Essaie à
nouveau."
Kinde, Kinden, Kinds "Le pluriel de kind ressemble à celui de
'das Feld', 'die Felder'. Essaie encore."
autre réponses "Le pluriel se forme généralement en
ajoutant -e, -en, -er ou -s. Propose une
autre réponse."
4.6.3
Question: "Citez trois villes de Suisse romande."
Réponses Feed-back
3 villes "Très bien."
correctes
1 ou 2 villes "Très bien. Complétez votre réponses."
correctes
aucune ville "Je ne trouve pas de ville romande dans votre réponse.
correcte J'attends une autre proposition."