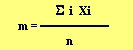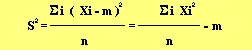|
Notions
de Statistique Descriptive
|
|
|
Comme disait Pythagore :"Le nombre est essence
de toutes choses", mais il a représente surtout une quantité.
Mais les nombres ont comme qualité principale d'être en nombre
infini. Ils représentent donc une infinité de quantité.
Comme on a toujours un peu de mal à s'imaginer la signification
exacte de l'infini ( moi en tout cas j'ai du mal), alors imaginez une quantité
infinie de nombre représentant des quantités. On s'en sort
plus.
C'est là que des petits malins (appelé
depuis des statisticiens) se sont imaginé que si l'on a affaires
à une certaine série de nombres, l'on pourrait les regrouper
en "groupe" pour faciliter leur traitement en supposant que tout ces nombres
ont des propriétés homogènes. C'est comme ça
qu'est née la notion de statistique descriptive. En psychologie
ou dans toute autre branche lorsque l'on effectue une mesure sur un groupe
(exemple la taille d'un groupe d'individus), l'on se retrouve avec un certain
nombre de valeurs correspondant aux individus. On dira que la taille représente
la variable (ce qui varie entre les individus et qui nous intéresse
pour les calculs) et que le groupe d'individus représente l'échantillon
qui est une partie de l'ensemble total des individus que l'on appel la
population. On s'intéressera donc à un individu comme
étant membre d'un groupe (les hommes, les femmes, les humains, les
martiens...). Le but de la statistique descriptive est donc de décrire
des données en mettant de l'ordre et une certain régularité;
c'est comme si l'on faisait le résumé du livre : le résumé
à l'avantage d'être plus court, plus facile à lire
et comporte (en général, parce que j'en connais qui font
de ces résumés...) les éléments essentiels,
mais le résumé néglige certains aspect pour facilité
la lecture. En statistique nous aurons recourt à la partie
statistique inférentielle
pour savoir à quelle point l'on peut
résumer sans perdre des informations essentielles et quel est le
meilleur résumé avec le moins d'erreur. |
la statistique descriptive se compose de 3 domaines
distincts :
-
la statistique uni variée :
On étudie la répartition d'une population selon une variable
( la taille, le poids ...)
-
la statistique bivariée : On étudie
ici la relation qui peut exister entre deux variables (entre la taille
et le poids, par exemple...)
la statistique multi variée:
On ne parlera pas ici de statistique. bivariée mais il s'agit de
relations entre plusieurs variables que l'on traite avec des méthode
comme l'analyse factorielle.
|
-
la statistique uni variée :
Il est souvent astucieux lorsqu'on est confronté
à une variable (ex : la taille) de faire un graphique pour avoir
une représentation visuelle (qui plus facile à se représenter
que des formules abstraites). La plupart des représentation de la
distribution d'une variable statistique que l'on appelle communément
la distribution ont une forme spécial comme la courbe en cloche
de LAPLACE - GAUSS. L'on peut recueillir deux types de données sur
une distribution uni variée :
-
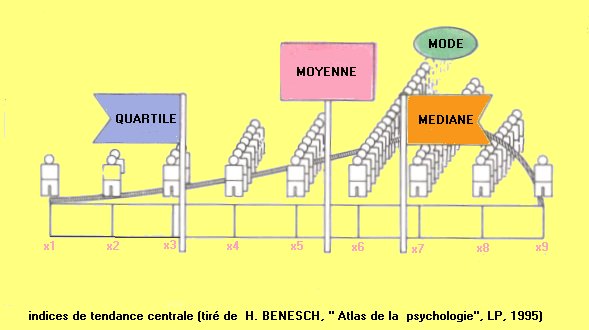
Les indices de tendance centrale : Ce sont des
indices qui donnent des informations sur la position générale
de la distribution on distingue trois indices de tendance centrale principaux
: La Moyenne, la Médiane, le mode.
La moyenne : La moyenne est au groupe ce
que le score est à l'individu, c'est-à-dire qu'elle permet
de savoir la position exacte d'une groupe ou d'un échantillon sur
un axe (une variable). elle se calcul en additionnant tout les valeurs
obtenues par des élément d'un échantillons et en divisant
cette somme par le nombre total de valeurs. (si les valeurs de taille pour
3 individus sont 182 cm, 170 cm et 167 cm, la moyenne est (182+170+167)
/ 3. ) :
La médiane : La médiane va
diviser la distribution de sorte à obtenir deux moitiés ayant
chacune 50 % des valeurs de la distribution.
Le mode : représente la valeur
la plus fréquente de la distribution numérique ( si l'on
a les valeurs suivantes pour la taille : 156, 178, 189, 178, 152; le mode
est 178 car la valeur 178 apparaît le plus, c'est-à-dire deux
fois alors que les autres n'apparaissent qu'une fois).
-
Les indices de dispersion : donnent des renseignements
sur la dispersion et la variabilité dans un groupe, à savoir
à quel point les valeurs de la distributions sont homogène
( si les valeurs sont proches de la moyenne ou pas) et hétérogène
( si écart entre la moyenne et les valeur extrême est trop
important). On parlera ici principalement de la variance et de l'écart
type: l'écart type se calcul en élevant la variance au carré
et la variance se calcule en faisant la somme des (valeurs Xi moins la
moyenne M) le toute au carré et divisé par l'effectif total
N :
|
-
La statistique bivariée :
Si nous nous intéressons à la relation
qu'il pourrait y avoir entre deux variables distinctes, nous aurons recours
à la statistique bivariée. Le type d'analyse que nous pouvons
faire sur deux variables est de l'ordre corrélationnel, c'est-à-dire
que nous nous intéresserons à la relation éventuelle
qui peut exister entre deux variables, par exemple le degrés de
dépendance etc... Les calculs se font ici en recherchant des indices
de covariation ( ou variation concomitante) entre les deux variables (exemples
: La relation entre le poids et la taille sur une population peut être
calculer par un indice d'association ou indice corrélatif ). On
parlera ici de trois types d'indices principaux applicables selon le type
de la variable à laquelle on a affaire : Le coefficient X²
(lire chi carré) et K de Cramer, les coefficients Rhô de Spearman
et Tau de Kendall, et le coefficient r de Bravais-Pearson.
Tableau des indices de tendances, de dispersions
et de dépendances selon les 3 types de variables :
|
nb de variables
|
Échelles :
|
Nominale
|
ordinale
|
quantitative
|
|
1 variable
|
Indices de tendance :
|
Mode
|
Médiane
|
Moyenne
|
|
1 variable
|
indice de dispersion
|
Entropie
|
ESI, EMR
|
Variance, Écart type
|
|
2 variables
|
indices de dépendance
|
Chi carré, Cramer
|
Rho de Spearman, Tau de Kendall
|
r de Bravais-Pearson
|
Les questions que l'on se posent à propos
de la relation entre deux variables statistique sont les suivantes :
-
Quelle est la forme de la relation ?
-
Quelle est l'intensité de la relation ?
Quelle est le sens de la relation ?
|
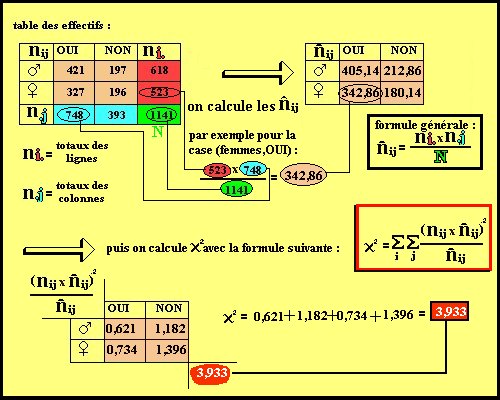
-
Le Chi carré et le coefficient
de Cramer : Le X² est un indice de dépendance applicable
uniquement au variables nominales. Son calcul se fait à partir d'un
tableau d'effectif (répartition des sujets selon les modalité
) : prenons l'exemple d'une étude sur l'influence du sexe (première
variable, 2 modalité) sur la réponse à une question
(2ème variable, 2 modalités) dont le résultat est
résumé dans le tableau 1. Le calcule du chi carré
se fait de la manière suivante :
Le Chi carré prend des valeur entre
0 et l'infini. La valeur dépend des dimension du tableau des effectifs
et de l'effectif lui-même. Si le chi carrée = 0 , c'est qu'il
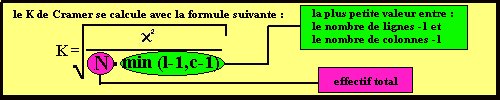
n'y a aucune corrélation entre les deux variables. Le K de Cramer
est une forme centrée réduite du chi carré. Il varie
donc entre 0 et 1. plus la valeur de K est proche du 1 plus il y a corrélation
entre les deux variables.
|
-
Le Rho de Spearman et le Tau
de Kendall : Ces indices ne peuvent être
calculer sur une variables quantitatives. On les utilise de préférence
sur des variables du type ordinale et qualitatives en générale.
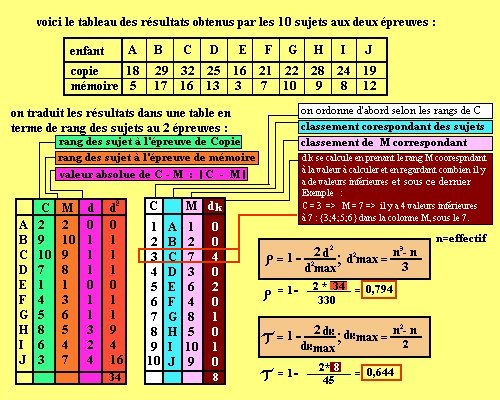
Prenons l'exemple d'une étude sur deux variables ordinales où
l'on aimerait mettre en évidence la relation entre une épreuve
de copie d'après modèle (var 1.) et une épreuve de
reproduction de mémoire (var 2.) d'une figure donnée par
10 (échantillons) enfants de 10 ans (population):
|
-
Le r de Bravais-Pearson :
Le r est un coefficient que l'on calcul sur des variables quantitatives.
|
|