



In order to understand how services are provided on the Internet, let's shortly define the "server-client" concept. A server is a computer and/or program which provides resources to other machines or programs. A Client (or client program) uses resources from a server. "Traffic" on the information highway refers to information packets going from one machine to another using a certain communication protocol. Each computer on the Internet has a unique ID number (e.g. 129.194.81.44). Most computers also have a symbolic name (e.g. "tecfa.unige.ch"). The last element refers to a network (e.g. "ch" means "Swiss research net"). The second last element refers to an organisation (e.g. "unige" means "University of Geneva"). The first element usually refers to a specific machine. In principle, one can connect from any machine to any other. Special gateways allow some access to machines on other kinds of networks. Let's now examine a few protocols providing interesting services on the Internet:
"FTP" stands for File Transfer Protocol; on many systems, it's also the name of a user-level program that implements that protocol. This program allows a user to transfer files to and from a remote network site.
"Telnet" is the name of the protocol which allows you to connect to a remote machine. Normally you need access privileges, but some services, e.g. library or educational database lookups are provided freely without restrictions.
"Anonymous FTP" indicates that a user may log into the remote system as user "anonymous" with an arbitrary password. Thousands of anonymous FTP servers exist. A lot of research institutions make available research papers and software that way. Normally, each country has one or several huge and well known servers "Archie" servers index major servers and you can query them to find some on which huge amounts of programs and papers are made available. Special appropriate software (including educational) on the net.
"Usenet" is a large set of computers (not restricted to the Internet) who exchange "news". People can post articles tagged with one or more universally-recognised labels, called "news groups". Those news groups are organised in hierarchies. Most of those hierarchies are public and spread out through the entire world. Some (like "Clari News") are commercial and some are local. A number of software packages are used for reading and posting articles. On the Internet, most organisations use the Network News Transfer Protocol (NNTP) to receive a "News feed", to make articles available to client news readers of the local network and to propagate locally posted articles to other sites.
Given the huge amount of files and services available and the relatively high "noise/information level" of "Usenet News", applications have been invented to organise access to network resources in a uniform way. The first widely used system has been "Gopher", a menu based system which allows you to browse and search documents, link to resources such as Usenet, Archie, campus information systems, and even connect to other Gophers. All gophers in "gopher space" are also linked with a geographical index. Since one can get easily lost in gopher space, special "Veronica Servers" exist which index major gopher sites. Gophers are very popular in education and with institutions dealing with Education.
Many other services and protocols exist. A few of them are: WAIS (a Wide Area information Server with a a powerful full-text indexing engine); Finger and X500 (systems to provide information on people); IRC ("Internet Relay Chat", implementing real-time discussion); Hytelnet (an integrator for library access), MUDs (real-time multi-user textual virtual realities, mainly used for role-playing and adventure gaming), NFS (the most popular network file sharing system for workstations), MBone ("Multicast BackBone", an extension to the IP protocol allowing for video-conferencing on standard WAN lines).
The "World-Wide Web" (WWW) is now becoming the most popular campus and world-wide information system on the Internet. It has all of Gopher's functionalities, but is not hindered by Gopher's relatively simple menu-based organisation. The WWW allows you to explore the unlimited world-wide digital "web" of information. It's integrated hypertext system relates information in an easy to use way. Almost every document you look at provides you with pointers, or links, which you can follow to other documents on related subjects. A number of interactive search engines exist to locate information in and outside of the WWW. Some of those are based on "spiders", programs crawling through the net and picking up information. The WWW is an evolving standard and it's potential for education is now recognised by both academia and business.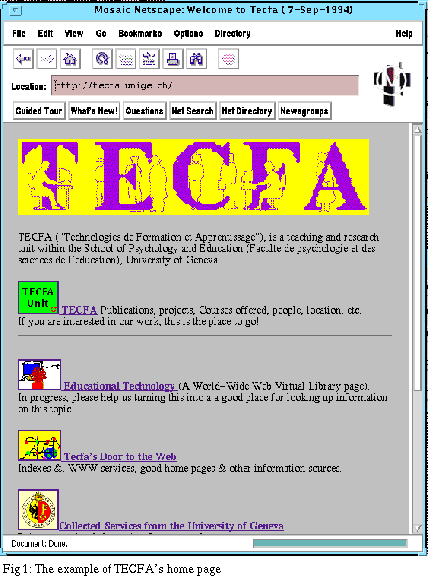
Generated with CERN WebMaker