Cours de Bases de Donnees
Dana
Torres
Luis
Gonzalez
SaraTassini
| jeudi 10 Avril |
9.30-11.00
Introduction +Modelisation conceptuel
+ EX
n°1 13.30 - 15.30
Model physique, le langage
SQL
|
| vendredi 11 Avril |
9.00-11.00
Introduction
PHP, Mysql 13.30 - 16.00
Préparation du Projet |
Définition : Une base de données (BD) est un ensemble de données mémorisées sur des supports accessibles par un ordinateur pour satisfaire simultanément plusieurs utilisateurs de façon sélective et en temps très court. Elles constituent le cœur du système d’information.
Il existe 4 types de bases de données :
Les BD constituent le cœur du système d’information. La conception de ces bases est la tâche la plus ardue du processus de développement du système d’information.
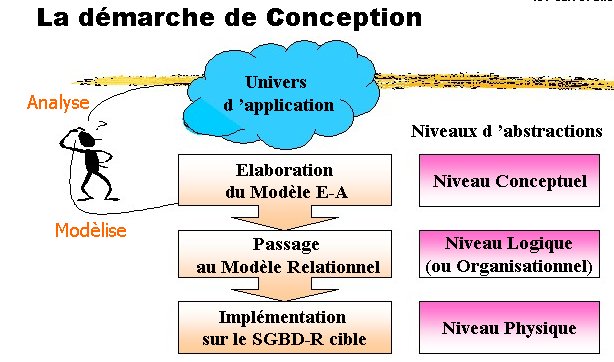
Les méthodes de conception préconisent une démarche en étapes et font appel à des modèles pour représenter les objets qui composent les systèmes d’information, les relations existantes entre ces objets ainsi que les règles sous-jacentes.
La modélisation se réalise en trois étapes principales qui correspondent à trois niveaux d’abstraction différents :
I. Niveau conceptuel : représente le contenu de la base en termes conceptuels, indépendamment de toute considération informatique.
II. Niveau logique relationnelle : résulte de la traduction du schéma conceptuel en un schéma propre à un type de BD.
III. Niveau physique : est utilisé pour décrire les méthodes d’organisation et d’accès aux données de la base.
La modélisation est une étape fondamentale de la conception de la BD dans la mesure où, d’une part, on y détermine le contenu de la BD et, d’autre part, on y définit la nature des relations entre les concepts principaux.
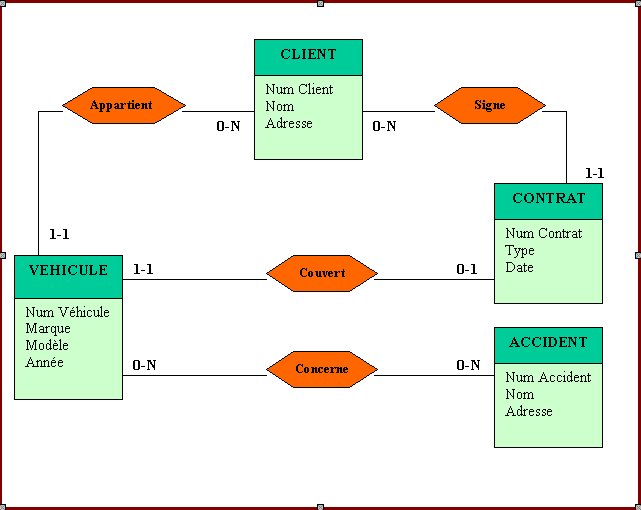
Il existe deux catégories d’entités :
- Entités régulières : son existence ne dépend pas de l’existence d’une autre entité.
- Entités faibles : son existence dépend de l’existence d’une autre entité.
Ex : l’entité CONTRAT n’existe que si l’entité CLIENT correspondante est présente.
Figure N° 1 : LES ENTITES

Un attribut peut être obligatoire ou facultatif et avoir un domaine de valeurs.
Figure N° 2 : LES ATTRIBUTS
Contrairement aux entités, les relations n’ont pas de relations propres. Les relations sont caractérisées, comme les entités, par un nom et éventuellement des attributs.
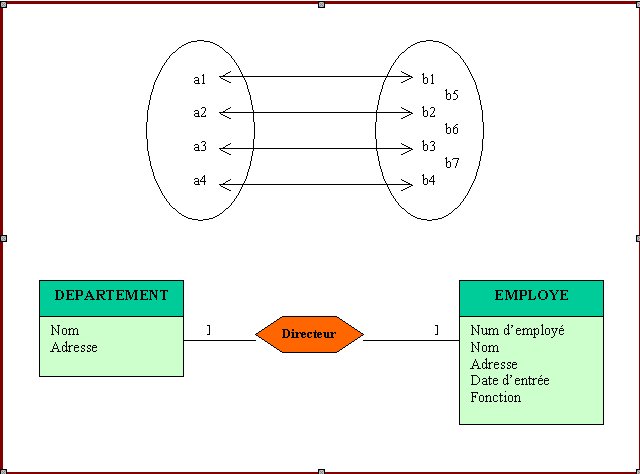
Cardinalité : la description complète d’une relation nécessite la définition précise de la participation des entités. La cardinalité est le nombre de participation d’une entité à une relation.
Cardinalité un à un : si et seulement si un employé ne peut être directeur que dans un seul département et un département n’a qu’un seul employé comme directeur.
Figure N° 3 : CARDINALITE UN à UN
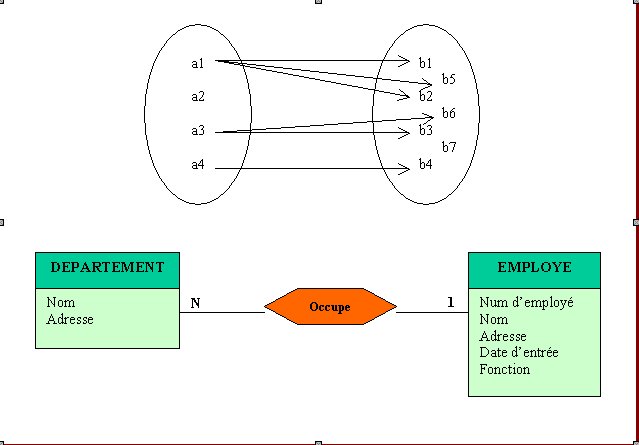
Cardinalité un à plusieurs : un département peut occuper plusieurs employés qui réalisent différentes fonctions mais chaque employé ne fait partie que d’un seul département.
Figure N° 4 : CARDINALITE UN à PLUSIEURS
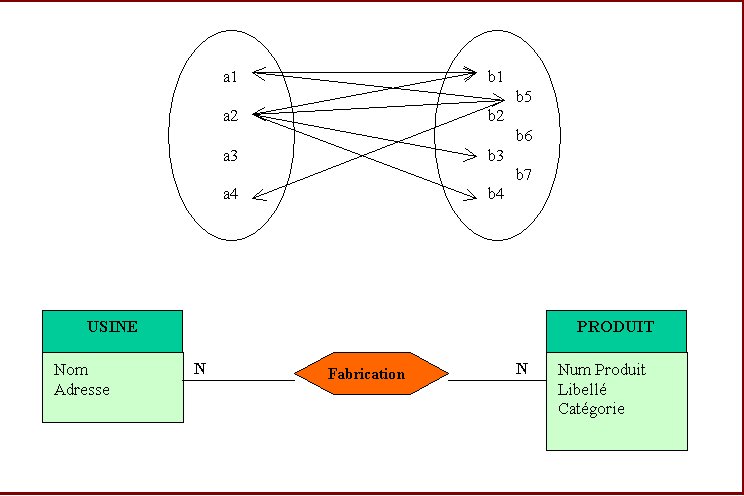
Cardinalité plusieurs à plusieurs : un type de produit peut être fabriqué en plusieurs usines et une usine donnée peut fabriquer plusieurs types de produits.
Figure N° 5 : CARDINALITE PLUSIEURS à PLUSIEURS
Les cardinalités présentées ci-dessus sont appelées cardinalités maximales dans la mesure où elles représentent le nombre maximum de participations d’une entité à une relation.
En revanche, la cardinalité minimale est le nombre minimal de participations d’une entité à une relation. La cardinalité minimale peut être 0 ou 1.
Les cardinalités maximales et minimales traduisent les contraintes propres aux entités et relations. Dans un schéma conceptuel, elles sont représentées comme suit :
0-1 aucune ou une seule
1-1 une et une seule
0-N aucune ou plusieurs
1-N une ou plusieurs
Figure N° 6 : CARDINALITES MINIMALES ET MAXIMALES
Une situation à modéliser peut avoir plusieurs schémas différents, chaque modèle présentant des avantages et des inconvénients.
Pour mesurer la qualité d’une modélisation ER il existe plusieurs critères à utiliser de manière combinée :
La construction d’un schéma conceptuel peut se réaliser de la manière suivante :
1. Déterminer la liste des entités.
2. Pour chaque entité :
a) établir la liste de ses attributs ;
b) parmi ceux-ci, déterminer un identifiant.
3. Déterminer les relations entre les entités.
4. Pour chaque relation :
a) dresser la liste des attributs propres à la relation ;
b) vérifier la dimension (binaire, ternaire, etc.) ;
c) définir les cardinalités.
5. Vérifier le schéma obtenu, notamment :
a) supprimer les transitivités ;
b) s’assurer que le schéma est connexe ;
c) s’assurer qu’il répons aux demandes.
6. Valider avec les utilisateurs.
II. Modélisation logique relationnelle
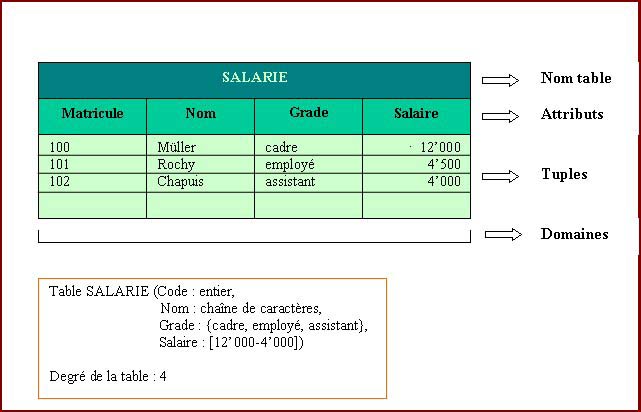
Dans le modèle relationnel, les entités du schéma conceptuel sont transformées en tableaux à deux dimensions. Le modèle relationnel s’appui sur trois concepts fondamentaux : le domaine, l’attribut et la relation ou table.
Domaine simple : si tous les éléments sont atomiques ou décomposables.
Ex : l’ensemble des grades du salarié peut être définit en extension par employé, agent de maîtrise, ou cadre.
Domaine composé : si les éléments peuvent être décomposés.
Ex : les dates sont décomposées d’un jour, un mois et une année.
Figure N° 8: DESCRIPTION D’UNE TABLE à DEUX DIMENSIONS D’UNE BASE DE DONNEE
Les contraintes d’intégrité : permettent d’assurer la cohérence des données. Les contraintes d’intégrité sont :
Contrainte de domaine : restriction de l’ensemble des valeurs possibles d’un attribut.
Contrainte de clé : définit un sous-ensemble minimal des colonnes tel que la table ne puisse contenir deux lignes ayant mêmes valeurs pour ces colonnes.
Il existe trois
types de clés:
Contrainte obligatoire : précise qu’un attribut ou plusieurs attributs doivent toujours avoir une valeur.
Contrainte d’intégrité référentielle ou d’inclusion: lie deux colonnes ou deux ensembles de colonnes de deux tables différentes.
La théorie de la normalisation : permet de définir formellement la qualité des tables au regard du problème posé par la redondance des données. La théorie de la normalisation s’appui sur la dépendance fonctionnelle. Cod a définit un ensemble de formes normales caractérisant les tables relationnelles :
· Première forme normale : si elle ne contient que des attributs atomiques.
· Deuxième forme normale : si elle ne contient que des attributs atomiques et, si de plus, il n’existe pas de dépendance fonctionnelle entre une partie d’une clé et une colonne non clé de la table.
· Troisième forme normale : si elle ne contient que des attributs atomiques, s’il n’existe pas de dépendance fonctionnelle entre une partie d’une clé et une colonne non clé de la table et si, de plus, aucune dépendance fonctionnelle entre les colonnes non clé.
Ainsi, plus une table est normalisée moins elle comporte de redondances et donc de risques d’incohérence sémantiques dans les schémas relationnels.
Les règles principales de transformation d’un schéma conceptuel Entité-Relation en un schéma relationnel sont :
Règle I : Toute entité est traduite en une table relationnelle dont les caractéristiques sont les suivantes :
Figure N° 9 : TRADUCTION DE LA RELATION PLUSIEURS à PLUSIEURS
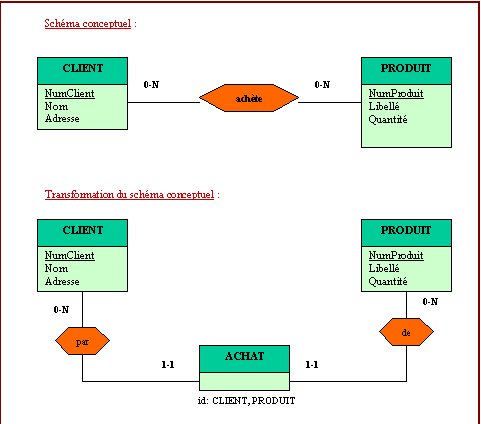
Règle II : Toute relation binaire plusieurs à plusieurs est traduite en une table relationnelle dont les caractéristiques sont les suivantes :
· le nom de la table est le nom de la relation ;
· la clé de la table est formée par la concaténation des identifiants des entités participant à la relation ;
· les attributs spécifiques de la relation forment les autres colonnes de la table.
Une contrainte d’intégrité référentielle est générée entre chaque colonne clé de la nouvelle table et la table d’origine de cette clé.
Figure N° 10 : TRADUCTION DE LA RELATION PLUSIEURS à PLUSIEURS
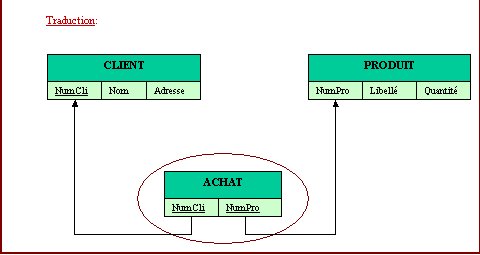
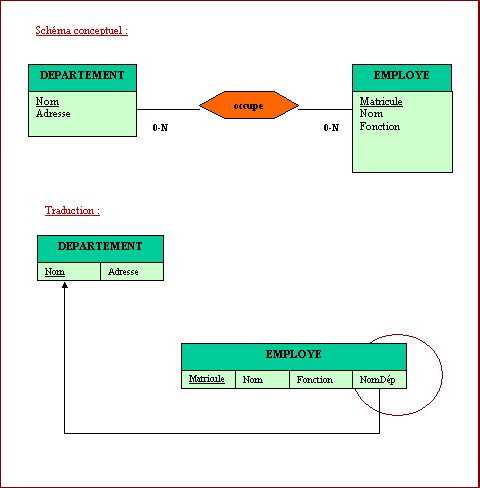
Règle III : Toute relation binaire un à plusieurs est traduite :
· le nom de la table est le nom de la relation ;
· la clé de la table est l’identifiant de l’entité participent à la relation côté 1 ;
· les attributs spécifiques de la relation forment les autres colonnes de la table.
Figure N° 11 : TRADUCTION DE LA RELATION UN à PLUSIEURS
Règle 4 : Toute relation binaire un à un est traduite, au choix, par l’une des trois solutions suivantes :
· fusion des tables des entités qu’elle relie (choix1) ;
· report de clé d’une table dans l’autre (choix2) ;
· création d’une table spécifique reliant les clés des deux entités (choix3).
Les attributs spécifiques de cette relation sont ajoutés à la table résultant de la fusion (choix1), reportés avec la clé (choix2), ou insérés dans la table spécifique (choix3).
Figure N° 12 : TRADUCTION DE LA RELATION UN à UN

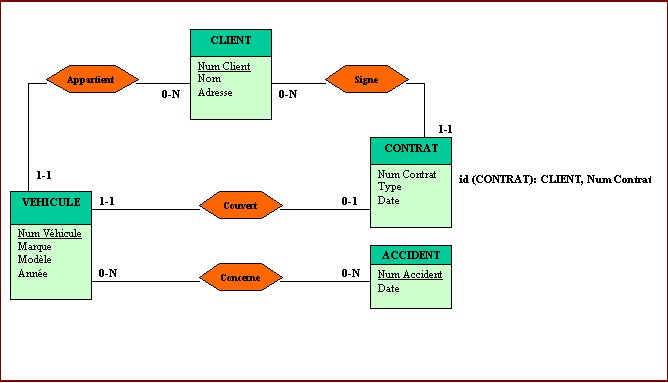
Figure N° 13a: TRADUCTION D’UN SCHEMA CONCEPTUEL EN SCHEMA RELATIONNEL
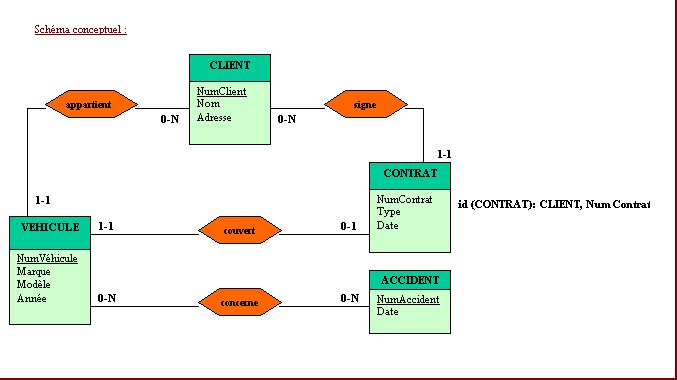
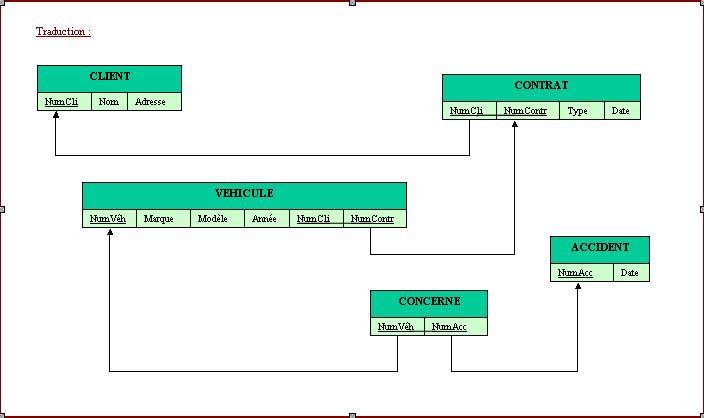
Figure N° 13b: TRADUCTION D’UN SCHEMA CONCEPTUEL EN SCHEMA RELATIONNEL
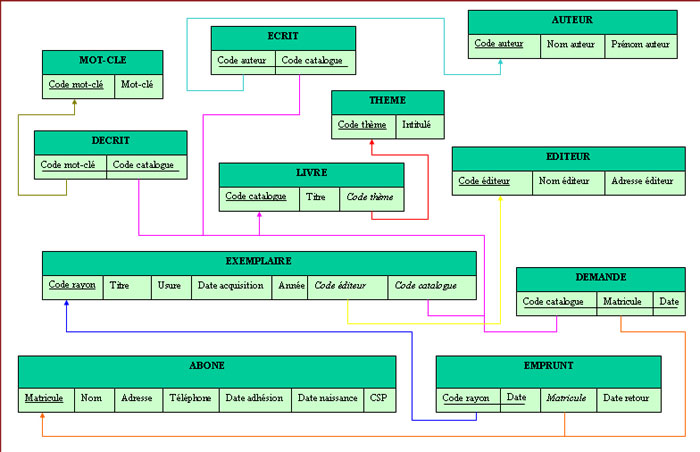
Transformer le schéma ER de la gestion de la bibliothèque de l’exercice n°1 en schéma relationnel.
Le langage SQL (Structured
Query Langage) s’appui sur les opérateurs de l’algèbre
relationnelle définit en 1970 par Codd, mathématicien, chercheur chez IBM. Le langage SQL est basé sur le concept
de relation de la théorie des ensembles.
Opérateurs de l’algèbre relationnelles :
Les opérations de base :
Les opérations ensemblistes
Cet opérateur ne porte que sur 1 relation.
Il permet de ne retenir que certains attributs spécifiés d'une relation.
On obtient tous les n-uplets de la relation à l'exception des doublons.

SELECT DISTINCT liste d'attributs FROM table ;
SELECT liste d'attributs FROM table ;
Exemples :
SELECT
DISTINCT Espèce FROM Champignons ;
SELECT DISTINCT Espèce, Catégorie FROM Champignons ;
La clause DISTINCT permet d'éliminer les doublons.
Cet opérateur porte sur 1 relation.
Il permet de ne retenir que les n-uplets répondant à une condition exprimée à l'aide des opérateurs arithmétiques ( =, >, <, >=, <=, <>) ou logiques de base (ET, OU, NON).
Tous les attributs de la relation sont conservés.
Un attribut peut ne pas avoir été renseigné pour certains n-uplets. Si une condition de sélection doit en tenir compte, on indiquera simplement : nom_attribut "non renseigné".

SELECT * FROM table WHERE condition ;
Exemple :
SELECT * FROM Champignons WHERE Catégorie="Sec" ;
La condition de sélection exprimée derrière la clause WHERE peut être spécifiée à l'aide :
des opérateurs de comparaison : =, >, <, <=, >=, <>
des opérateurs logiques : AND, OR, NOT
des opérateurs : IN, BETWEEN, LIKE, IS
Autres exemples :
Soit la table ETUDIANT (N°Etudiant, Nom, Age, CodePostal, Ville)
SELECT *
FROM ETUDIANT
WHERE Age IN (19, 20, 21, 22, 23) ;
SELECT *
FROM ETUDIANT
WHERE Age BETWEEN 19 AND 23 ;
SELECT *
FROM ETUDIANT
WHERE CodePostal LIKE '42%' ;
SELECT *
FROM ETUDIANT
WHERE CodePostal LIKE '42___' ;
SELECT *
FROM ETUDIANT
WHERE Ville IS
NULL ; // Etudiants pour lesquels la ville
n'est pas renseignée
SELECT *
FROM ETUDIANT
WHERE Ville IS
NOT NULL ; // Etudiants pour lesquels la ville
est renseignée
JOINTURE (R1, R2, condition d'égalité entre attributs)
- Cet opérateur porte sur 2 relations qui doivent avoir au moins un attribut défini dans le même domaine (ensemble des valeurs permises pour un attribut).
- La condition de jointure peut porter sur l'égalité d'un ou de plusieurs attributs définis dans le même domaine (mais n'ayant pas forcément le même nom).
- Les n-uplets de la relation résultat sont formés par la concaténation des n-uplets des relations d'origine qui vérifient la condition de jointure.
Remarque : Des jointures plus complexes que l'équijointure peuvent être réalisées en généralisant l'usage de la condition de jointure à d'autres critères de comparaison que l'égalité (<,>, <=,>=, <>).
En SQL, il est possible d'enchaîner plusieurs jointures dans la même instruction SELECT.
En SQL de base :
SELECT * FROM table1, table2, table3, ...
WHERE table1.attribut1=table2.attribut1 AND table2.attribut2=table3.attribut2 AND ...;
Exemple :
SELECT * FROM Produit, Détail_Commande
WHERE Produit.CodePrd=Détail_Commande.CodePrd
;
ou en utilisant des alias pour les noms des tables :
SELECT * FROM Produit A, Détail_Commande
B
WHERE A.CodePrd=B.CodePrd
;
Cet opérateur porte sur 2 relations qui doivent avoir le même nombre d'attributs définis dans le même domaine (ensemble des valeurs permises pour un attribut). On parle de relations ayant le même schéma.
La relation résultat possède les attributs des relations d'origine et les n-uplets de chacune, avec élimination des doublons éventuels.

SELECT liste d'attributs FROM table1
UNION
SELECT
liste d'attributs
FROM table 2 ;
Exemple :
SELECT n°enseignant, NomEnseignant FROM
E1
UNION
SELECT n°enseignant, NomEnseignant FROM E2 ;
Cet opérateur porte sur deux relations de même schéma.
La relation résultat possède les attributs des relations d'origine et les n-uplets communs à chacune.

Exemple :
E1 : Enseignants élus au CA
E2 : Enseignants représentants syndicaux
On désire connaître les enseignants du CA qui sont des représentants syndicaux.
R2 = INTERSECTION (E1, E2)
En SQL de base :
SELECT attribut1, attribut2, ... FROM
table1
WHERE attribut1 IN (SELECT attribut1 FROM table2) ;
ou avec SQL2 :
SELECT attribut1, attribut2,
... FROM table1
INTERSECT
SELECT attribut1,
attribut2, ... FROM
table2 ;
Exemple :
SELECT n°enseignant, NomEnseignant FROM
E1
WHERE n°enseignant IN (SELECT n°enseignant
FROM E2) ;
ou
SELECT n°enseignant, NomEnseignant FROM
E1
INTERSECT
SELECT n°enseignant, NomEnseignant FROM E2 ;
Cet opérateur porte sur deux relations de même schéma.
La relation résultat possède les attributs des relations d'origine et les n-uplets de la première relation qui n'appartiennent pas à la deuxième.
Attention ! DIFFERENCE (R1, R2) ne donne pas le même résultat que DIFFERENCE (R2, R1)

Exemple :
On désire obtenir la liste des enseignants du CA qui ne sont pas des représentants
syndicaux.
R3 = DIFFERENCE (E1, E2)
SELECT attribut1, attribut2, ...
FROM table1
WHERE attribut1 NOT IN (SELECT attribut1 FROM table2) ;
SELECT table1.attribut1, table1.attribut2,...
FROM table1 LEFT OUTER JOIN table2 ON table1.attribut1
= table2.attribut1
WHERE table2.attribut1 IS NULL ;
Exemple :
SELECT n°enseignant, NomEnseignant FROM
E1
WHERE n°enseignant NOT IN (SELECT
n°enseignant FROM E2) ;
ou
SELECT n°enseignant, NomEnseignant FROM
E1
EXCEPT
SELECT n°enseignant, NomEnseignant FROM E2 ;
ou encore
SELECT E1.n°enseignant, E1.NomEnseignant
FROM E1 LEFT OUTER JOIN E2 ON E1.n°enseignant = E2.n°enseignant
WHERE E2.n°enseignant IS NULL ;
voici le résultat renvoyé par la jointure externe gauche entre E1 et E2 :
- Cet opérateur porte sur deux relations.
- La relation résultat possède les attributs de chacune des relations d'origine et ses n-uplets sont formés par la concaténation de chaque n-uplet de la première relation avec l'ensemble des n-uplets de la deuxième.
Exemple :
Etudiants Epreuves
Examen = PRODUIT (Etudiants, Epreuves)
-
SELECT * FROM table1, table2 ;
Exemple :
SELECT * FROM Etudiants, Epreuves ;
-
La création d’une table peut être réalisée au moyen de la commande suivante :
CREATE TABLE nom_table
Le langage SQL dispose également des commandes suivantes :
ALTER TABLE : permet la modification de la structure d’une table, ajout d’une colonne, ajout d’une contrainte, modification de la définition d’une colonne, suppression d’une contrainte, etc.
DROP TABLE : permet de supprimer une table.
RENAME : permet de modifier le nom d’une table.
Le langage de manipulation des données comprend quatre instructions principales :
SELECT : pour l’interrogation d’une ou plusieurs tables ;
INSERT : pour l’ajout des lignes dans une table ;
UPDATE : pour la modification des lignes ;
DELETE : pour la suppression des lignes.
Les contraintes de colonnes et les contraintes de table matérialisent les différentes contraintes d’intégrité dont les SBD prend en charge la vérification systématique :
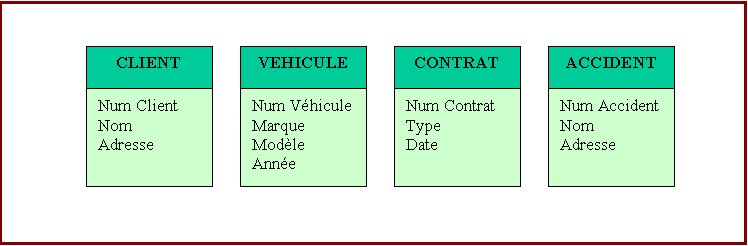
Traduction du schéma relationnel de la Fig. 13b en langage SQL
NumCli char (12) not null,
Adresse char (60) not null,
primary key (NumCli) );
NumCli char (12) not null,
NumContr char (38) not null,
Type decimal (4) not null,
Date date not null,
primary key (NumCli, NumCtr),
foreign key (NumCli) references CLIENT);
NumVeh char (16) not null,
Marque char (30) not null,
Modele decimal (30) not null,
NumCli char (12) not null,
NumContr decimal (8) not null,
primary key (NumVeh),
unique (Numcli, NumContr),
foreign key (NumCli) references CONTRAT);
NumAcc char (10) not null,
Date date not null,
primary key (NumAcc) );
NumVeh char (16) not null,
NumAcc char (10) not null,
primary key (NumVeh, NumAcc),
foreign key (NumVeh) references CLIENT
foreign key (NumAcc) references CLIENT);
- Créer une base de donné dans MyAdmin.
- Rédiger un rapport.
Le rapport devra comprendre la justification du thème et la démarche conceptuelle suivie (présentation du schéma conceptuel et relationnelle utilisé) .
Philippe Rigaux
(2001), Pratique de MySQL et PHP, O'REILLY.
J.Akoka et I.Comyn-Wattiau (2001), Conception des bases de données
relationnelles en pratique, Vuibert, Paris.